| > Show on single page > Show on multiple pages |
Copyright © 2016 Squoring Technologies
Licence
No part of this publication may be reproduced, transmitted, stored in a retrieval system, nor translated into any human or computer language, in any form or by any means, electronic, mechanical, magnetic, optical, chemical, manual or otherwise, without the prior written permission of the copyright owner, Squoring Technologies.
Squoring Technologies reserves the right to revise this publication and to make changes from time to time without obligation to notify authorised users of such changes. Consult Squoring Technologies to determine whether any such changes have been made.
The terms and conditions governing the licensing of Squoring Technologies software consist solely of those set forth in the written contracts between Squoring Technologies and its customers.
All third-party products are trademarks or registered trademarks of their respective companies.
Warranty
Squoring Technologies makes no warranty of any kind with regard to this material, including, but not limited to, the implied warranties of merchantability and fitness for a particular purpose. Squoring Technologies shall not be liable for errors contained herein nor for incidental or consequential damages in connection with the furnishing, performance or use of this material.
Abstract
This edition of the Configuration Guide applies to Squore 16.2.0 and to all subsequent releases and modifications until otherwise indicated in new editions.
Table of Contents
chart
measure and indicator
List of Tables
Table of Contents
This document was released by Squoring Technologies.
It is part of the user documentation of the Squore software product edited and distributed by Squoring Technologies.
The Squore Configuration Guide provides a complete reference for the configuration and administration of Squore 16.2.0, with step-by-step instructions to customise the different models that define Squore behaviour.
This manual is intended for Squore administrators. It allows to fine-tune the Squore configuration to fit specific needs or contexts. Note however, that the default parameters work in most cases for most users, and that only experienced and technical-savvy users should try to modify those settings.
If you are already familiar with Squore, you can navigate this manual by looking for what has changed since the previous version. New functionality is tagged with (new in 16.2) throughout this manual. A summary of the new features described in this manual is available in the entry * What's New in Squore 16.2? of this manual's Configuration Guide.
For information on how to use and configure Squore, the full suite of manuals includes:
Squore Installation Checklist
Squore Installation and Administration Guide
Squore Getting Started Guide
Squore Command Line Interface
Squore Eclipse Plugin Guide
Squore Configuration Guide
Squore Reference Manual
If the information provided in this manual is erroneous or inaccurate, or if you encounter problems during your installation, contact Squoring Technologies Product Support: http://support.squoring.com/
You will need a valid Squore customer account to submit a support request. You can create an account on the support website if you do not have one already.
For any communication:
support@squoring.com
Squoring Technologies Product Support
76, allées Jean Jaurès / 31000 Toulouse - FRANCE
Approval of this version of the document and any further updates are the responsibility of Squoring Technologies.
The version of this manual included in your Squore installation may have been updated. If you would like to check for updated user guides, consult the Squoring Technologies documentation site to consult or download the latest Squore manuals at http://support.squoring.com/documentation/16.2.0. Manuals are constantly updated and published as soon as they are available.
Table of Contents
This chapter describes how to work with the default configuration and how to build on it to extend Squore.
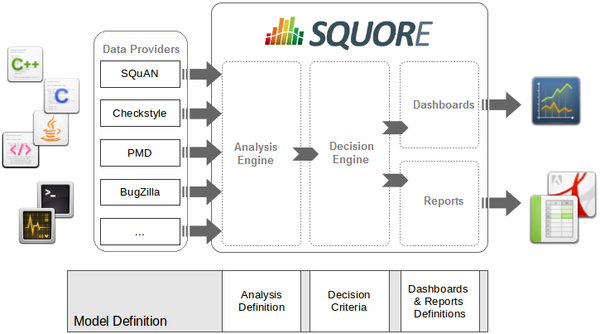
The picture above shows the different components involved in the Squore process.
The main building blocks of the Squore configuration are:
SQuORE parser and other Data Providers are the inputs for the process, providing base measures for the analysis model.
Analysis Models define the transformation between base measures, which are retrieved from Data Providers and derived measures.
Decision models define how to process raw data (i.e. base measures) and analysis data (i.e. derived measures) to raise action items.
Dashboards present the overall results in a convenient way. They are deeply customisable and can show all the information needed in day-to-day usage of Squore.
Reports extract information and present it in a document (PDF, Powerpoint or spreadsheet). They can be used for external reporting, e.g. when there is no access to the Squore interface.
Models define how Squore computes metrics (analysis model), how action items are created (decision model), and how data is displayed (dashboards and reports).
All models are located in the <SQUORE_HOME>/configuration/models directory.
Each folder in <SQUORE_HOME>/configuration/models is a separate model. Each model has
a wizard, i.e. a series of screens where users configure the options available for the model before launching an analysis,
as described in Chapter 8, Project Wizards.
The Shared folder is different, since it is not a self-contained model, but rather a
collection of components that are meant to be imported by other models in the configuration. This avoids creating redundancy, and redefining
the same metrics or indicators every time.
The Shared Model is located in the same directory as other models: <SQUORE_HOME>/configuration/models.
Its structure is similar to other models, but it does not appear in the user interface.
To understand some of the common measures and rules used across Squore you can take a look at
the common definitions available in <SQUORE_HOME>/configuration/models/Shared/Analysis/product_quality/code, especially:
artefact_rating
call_relation
cloning
complexity
control_flow_analysis
line_counting
rule_checking
stability
Squore is fully customisable and allows you to override the default models and add your own ones. Your modifications to the
default configuration should never be made directly in <SQUORE_HOME>/configuration, but in your own configuration folder which you
will make Squore aware of by editing <SQUORE_HOME>/config.xml. This allows you to create only the files that are needed
for your modifications and minimise the amout of files to add to version control.
In order to add a configuration folder for your modifications:
Create a folder called MyConfiguration
Create two subfolders folder called configuration and addons
Edit Squore Server's <SQUORE_HOME>/config.xml to add MyConfiguration/configuration
and MyConfiguration/addons as registered configuration and addons paths, as described
in the Installation and Administration Guide in the section called Adding a Configuration Folder
As a Squore administrator, log in and click Administration > Reload Configuration
Squore now knows that it needs to load the models that exist in your custom configuration as well as the ones in the default
configuration folder. If you want to override a file in the default configuration folder, recreate the folder structure in your
custom configuration folder, copy the file from the default configuration folder and make the necessary modifications. Because
the custom configuration folder is listed first in <SQUORE_HOME>/config.xml, the file in the custom configuration
folder will be used instead of the file in the default configuration folder.
Creating a new model is as simple as creating a folder in your custom configuration folder and creating the various definition files needed for the Analysis Model, the Decision Model, the dashboard and reports you want to enable:
Create a new directory MyModel in the MyConfiguration/configuration/models directory.
In the MyModel folder, create the following sub-folders:
Analysis
Dashboards
Decision
Description
Exports
Analysis
Reports
Wizards
Log into Squore as administrator, reload the configuration and click Models > Validator. Your new model should be visible in the list of available models.
The following section of this manual will cover how to use existing packages from the Shared folder and how to display text in the web infterface.
A model is a collection of several Bundle.xml files where your entire model is described. A model folder normally contains the following bundles:
MyModel/Analysis/Bundle.xml, where artefact types, metrics, indicators and rules are defined
MyModel/Dashboard/Bundle.xml, where the charts displayed in the web interface are defined
MyModel/Decision/Bundle.xml, where you define the action items for your model
MyModel/Description/Bundle.xml, where you translate all the elements of your model into several languages
MyModel/Exports/Bundle.xml, where you define the type of information that users can export from the web UI
MyModel/Highlights/Bundle.xml, where the different types of highlight categories are defined
MyModel/Properties/Bundle.xml, where optional properties about your model are defined
MyModel/Reports/Bundle.xml, where you define the type of reports that can be created from the web UI
MyModel/Wizards/Bundle.xml, where you define the parameters to be used when creatign a project with your model
More information about each type of bundle is available in this manual. Note that a Bundle.xml file normally includes external files located elsewhere in the standard Squore configuration. This allows reusing modules between models.
The following is an (incomplete) example of a Bundle.xml file that includes other files from the Squore configuration. Note that the
xmlns:xi
declaration in the Bundle
element is
mandatory if you want to include external files.
<?xml version="1.0" encoding="utf-8" standalone="yes"?>
<Bundle xmlns:xi="http://www.w3.org/2001/XInclude" >
<!-- Aliases -->
<ArtefactType id="CODE" heirs="PACKAGES;FILES;CLASSES;MODULES" />
<ArtefactType id="PACKAGES" heirs="APPLICATION;SOURCE_CODE;FOLDER" />
<ArtefactType id="FILES" heirs="FILE" />
<ArtefactType id="CLASSES" heirs="CLASS" />
<xi:include href="../../Shared/Analysis/SQuORE_BasicScales.xml" />
<!-- SQuORE Base Measures -->
<xi:include
href="../../Shared/Analysis/product_quality/code/line_counting/line_counting.xml" />
<xi:include
href="../../Shared/Analysis/Code/ObjectOrientation/squore_java_oo_basemeasures.xml" />
<xi:include
href="../../Shared/Analysis/Code/ObjectOrientation/SQuORE_Inheritance.xml" />
<!-- Rule Checking -->
<xi:include
href="../../Shared/Analysis/Code/RuleSet/SQuORE_Java_RuleSet.xml" />
<!-- SQALE Analysis Model -->
<xi:include
href="../../Shared/Analysis/Code/SQALE/SQALE_Characteristics.xml" />
<xi:include href="SQALE_Requirement.xml" />
<RootIndicator indicatorId="SQALE_INDEX_DENSITY" artefactTypes="APPLICATION;FOLDER;SOURCE_CODE" />
<RootIndicator indicatorId="SQALE_INDEX" artefactTypes="FUNCTION;CLASS;FILE" />
<Measure measureId="COST" targetArtefactTypes="APPLICATION" defaultValue="0" />
</Bundle>
All paths in a Bundle.xml are relative to Bundle.xml.
The bundle file is an xml file, which means that you must respect the XML syntax, otherwise Squore will not be able to read it. This means for example that the following characters are forbidden, and must be replaced by their corresponding entity reference:
& needs to be replaced by &
< needs to be replaced by <
> is preferably replaced by >, but this is not mandatory
" needs to be replaced by " (only when used inside an attribute value)
' needs to be replaced by ' (only when used inside an attribute value)
To learn more about entities, visit en.wikipedia.org/wiki/List_of_XML_and_HTML_character_entity_references
In order to provide a simple way to display dashboards in multiple languages in the Squore web interface, all strings have been externalised
to .properties files
. A .properties
file contains translations for all the metrics, rules, action items, charts and other objects described in your model. A model contains a
Bundle.xml that lists all the .properties files that need to be loaded for this model.
In your description bundle, inlude a .properties file by adding a Properties
element.
Squore will select the appropriate display language for this model according to the language options defined in the
available
and default
attributes, as shown below:
<?xml version="1.0" encoding="utf-8" standalone="yes"?> <Bundle available="fr,en" default="en"> <Properties src="../../Shared/data_provider/squan_sources/descriptions" /> </Bundle>
In the example above, it is assumed that two files exist with the names
Shared/data_provider/squan_sources/descriptions_en.properties
and Shared/data_provider/squan_sources/descriptions_fr.properties, since you declared both languages in the
available
attribute. Users are free to switch between the English and French languages using the flag
icons in the Squore web interface. By default, Squore will display the descriptions from descriptions_en.properties,
since you set the default language to "en" using the default
attribute.
Properties files are simple text files containing key-value pairs to associate text to a property of an element of your model.
For example, the metric SLOC is translated using this line in a .properties file:
SLOC.DESCRIPTION=The number of source line of codes
If we need the desctiption of SLOC to be different for artefact of type CPP_FUNCTION and APPLICATION, we can use a more advanced definition:
M.SLOC.DESCRIPTION.APPLICATION=The number of source line of codes in the application M.SLOC.DESCRIPTION.CPP_FUNCTION=The number of source line of codes in the function
The convention for this syntax is as follows:
[PREFIX.]IDENTIFIER.PROPERTY[.ARTEFACT_TYPE]=My localised text
where:
PREFIX is a prefix used to indicate which type of object the localised text applies to. If no prefix is specified, then the localised text is used for all objects in the model with this identifier. The supported values for PREFIX are:
M for measures
I for indicators
C for charts
EVO for trend icons
EX for exports
FA for families
FI for findings
G for groups
HI for highlights
LOP for scale levels (levels of performance)
MO for models
PERM for permissions
PRO for profiles
RO for roles
RE for reports
SC for scales
ST for action item statuses
T for artefact types
TA for tables
TA#IN for links tables displaying inbound links
TA#OUT for links tables displaying outbound links
TST for action item tests
TUTO for tutorial descriptions
WI for wizards
MIL for milestones
IDENTIFIER is the ID of the object as described in the model.
PROPERTY is the property being set. It is one of:
MNEMO to specify a mnemonic, i.e. a short representation of the object that is used where space needs to be preserved. Note that if no mnemonic is specified, the raw identifier will be used instead in the UI.
NAME to specify a name, i.e. the common, human-understandable representation of an object.
DESCR to specify a description for the object.
JUSTIF to specify a justification for a rule. This is displayed in the Findings pane and allows you to provide more details about why a rule is used.
URL to specify a URL associated with the object. This URL is displayed below the description of a rule on the Findings tab, or in any popup that shows the full description of a measure or indicator on the Dashboard. This URL is clickable and opens in a new browser window. This is usually useful if you want to link to the definition of a coding standard ourside of Squore.
ICON to specify an icon for a scale level (LOP), a trend icon in the artefact tree (EVO) or a group icon (G) in the project portfolios.
IMAGE to specify an image for a scale level (LOP) when displayed as a KPI on the dashbaord.
COLOR to specify the colour to represent a metric (M, I), a scale level (LOP) or a milestone (MIL) on a chart or a popup describing a scale. For more information about the supported colour formats, consult [colour syntax] .
NODATA to specify a text to be displayed in a chart (C) on the dashboard when no data can be displayed on the chart.
TREE_NAME to specify a name for a chart (C) that is used in the Dashboard Editor's tree of charts.
ARTEFACT_TYPE is used to restrict the scope of the property to the specified type of artefact. If no ARTEFACT_TYPE is specified, then the property applies for all artefact types.
Properties files are also used to customise tooltips appearing on the dashboard, as described in the section called “Using Tooltips”
Examples
Usual set of properties for a measure or an indicator:
STATUS.MNEMO=Status STATUS.NAME=Requirement Status STATUS.DESCR=Status (draft or final)
Usual set of properties for a rule to display in the Findings tab:
R_NOGOTO.MNEMO=NOGOTO R_NOGOTO.NAME=No GOTO R_NOGOTO.DESCR=A unconditional GOTO shall not be used to jump outside the paragraph. R_NOGOTO.JUSTIF=GOTO statements should be avoided because they complicated the task of analyzing and verifying the correctness of programs (particularly those involving loops). R_NOGOTO.URL=https://xkcd.com/292/
Usual set of properties for a scale:
SC.STATUS.NAME=Requirement Readiness Assessment LOP.UNKNOWN.MNEMO=Unknown LOP.UNKNOWN.NAME=Unknown LOP.UNKNOWN.DESCR=Unknown LOP.UNKNOWN.IMAGE=../Shared/Images/images/questionmark.png LOP.UNKNOWN.ICON=../Shared/Images/icons/questionmark.png LOP.UNKNOWN.COLOR=#C11B17 LOP.DRAFT.MNEMO=Draft LOP.DRAFT.NAME=Draft LOP.DRAFT.DESCR=Draft LOP.DRAFT.IMAGE=../Shared/Images/icons/wip.png LOP.DRAFT.ICON=../Shared/Images/icons/wip.png LOP.DRAFT.COLOR=#FFDB58 LOP.FINAL.MNEMO=Final LOP.FINAL.NAME=Final LOP.FINAL.DESCR=Final LOP.FINAL.IMAGE=../Shared/Images/icons/final.png LOP.FINAL.ICON=../Shared/Images/icons/final.png LOP.FINAL.COLOR=#41A317
The path to an image or icon file is relative to the root of the folder containing the model.
Using a different description for a metric when using it on the Action Items tab with the TST prefix:
OVERPERFORMANCE.MNEMO=Over-Performance
OVERPERFORMANCE.NAME=Over-Performance
OVERPERFORMANCE.DESCR=You are over-performing at this time.
TST.OVERPERFORMANCE.DESCR=Your current progress of {2}% is exceeding your objective for the next milestone by over 20% ({0}% in {1} days). /Either you are pretty good, or you underestimated yourself when setting your goals. Consider revising your objectives.
In the example above, / is used to indicate a new line in the description.
{0}, {1} and {2} are parameters that are dynamically filled in when viewing the action item. For more information, consult the section called “Trigger-Based Action Plans”.
Overriding a name and description for a specific type of artefact:
RAM.MNEMO=RAM RAM.NAME=Used RAM RAM.NAME.APPLICATION=Sum of Used RAM RAM.DESCR=Used RAM RAM.DESCR.APPLICATION=Sum of Used RAM
Squore resolves properties from the more specific to the more abstract, as shown below:
Note that aliases are not supported, only real artefact types. If you want to specify a description for functions in all languages, you have to add a line for each of the function types: CPP_FUNCTION, C_FUNCTION, ADA_FUNCTION...
Setting a chart's name and description
C.PERFORMANCE_TREND.NAME=Performane Trend C.PERFORMANCE_TREND.DESCR=<h1>Reading the Performance Trend Chart</h1><p>This chart shows a history of the performance trend for our application, as recorded nightly by our performance tests.</p><p>If you see any variation, you should perform the following three checks</p><ol><li>Is it a false positive, See if an error was reported in Jenkins</li><li>Check the machine logs for an explanation</li><li>Has someone already reported a bug? If not, <b>please do!</b></li></ol>
You can use the following HTML tags in chart descriptions: h1, h2, h3, h4, h5, h6, p, span, div, br, i, b, u, a, pre, hr, ul, ol, li
Setting help text for tutorials. Note that only .DESCR is supported:
TUTO.WELCOME_TUTORIAL_RISK.DESCR=Understanding the Risk Index Model TUTO.WELCOME_TUTORIAL_RISK_DESCRIPTION.DESCR=This tutorial takes you around the dashboard of the Squore Risk Index model to explain the concepts behind the ranking and help you understand how to improve your project based on the specific action plan generated by this model. TUTO.EXPLAIN_TRENDS.DESCR=<b>Warning!</b><br/>Pay attention to this trend icon: <img src="dashboard_tour/tree_up.png" />
HTML is supported in help text, but not in the main description of the tutorial that
appears in the tutorial selection popup. You can insert images in the help text, using the relative path to the image file from
Bundle.xml.
Here are the locations of the default types, permissions, roles and profiles, and statuses:
Types: <SQUORE_HOME>/configuration/models/Shared/Analysis/Code/Types/rights_en.properties
Permissions: <SQUORE_HOME>/configuration/models/Shared/Description/rights_en.properties
Roles and profiles: <SQUORE_HOME>/configuration/models/Shared/Description/roles_en.properties
Statuses: <SQUORE_HOME>/configuration/models/Shared/Description/status_en.properties
You are free to override or extend these defaults in your own .properties file in your model.
In order to set an icon for a type, create an image called identifier.png (the identifier must be lowercase) in
your configuration under models/Shared/Images/icons/types.
You can create your own Data Providers by using the built-in frameworks included in Squore. Each solution uses a different approach, but the overall goal is to produce one or more CSV files that your Data Provider will send to Squore to associate metrics, findings, textual information or links to artefacts in your project.
This section helps you choose the right framework for your custom Data Provider and covers the basics of creating a custom configuration folder to extend Squore.
The following is a list of the available Data Provider frameworks:
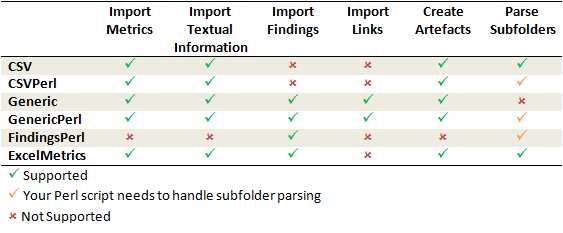
Data Provider frameworks and their capabilities
Csv
The Csv framework is used to import metrics or textual information and attach them to artefacts of type Application or File. While parsing one or more input CSV files, if it finds the same metric for the same artefact several times, it will only use the last occurrence of the metric and ignore the previous ones. Note that the type of artefacts you can attach metrics to is limited to Application and File artefacts. If you are working with File artefacts, you can let the Data Provider create the artefacts by itself if they do not exist already. Refer to the full Csv Reference for more information.
CsvPerl
The CsvPerl framework offers the same functionality as Csv, but instead of dealing with the raw input files directly, it allows you to run a perl script to modify them and produce a CSV file with the expected input format for the Csv framework. Refer to the full CsvPerl Reference for more information.
FindingsPerl
The FindingsPerl framework is used to import findings and attach them to existing artefacts. Optionally, if an artefact cannot be found in your project, the finding can be attached to the root node of the project instead. When launching a Data Provider based on the FindingsPerl framework, a perl script is run first. This perl script is used to generate a CSV file with the expected format which will then be parsed by the framework. Refer to the full FindingsPerl Reference for more information.
Generic
The Generic framework is the most flexible Data Provider framework, since it allows attaching metrics, findings, textual information and links to artefacts. If the artefacts do not exist in your project, they will be created automatically. It takes one or more CSV files as input (one per type of information you want to import) and works with any type of artefact. Refer to the full Generic Reference for more information.
GenericPerl
The GenericPerl framework is an extension of the Generic framework that starts by running a perl script in order to generate the metrics, findings, information and links files. It is useful if you have an input file whose format needs to be converted to match the one expected by the Generic framework, or if you need to retrieve and modify information exported from a web service on your network. Refer to the full GenericPerl Reference for more information.
ExcelMetrics
The ExcelMetrics framework is used to extract information from one or more Microsoft Excel files (.xls or .xslx). A detailed configuration file allows defining how the Excel document should be read and what information should be extracted. This framework allows importing metrics, findings and textual information to existing artefacts or artefacts that will be created by the Data Provider. Refer to the full ExcelMetrics Reference for more information.
The Data Providers that are not based on these frameworks can do a lot more than just import information from CSV files. Here is a non-exhaustive list of what some of them do:
Use XSLT files to transform XML files
Read information from microsoft Word Files
Parse HTML test result files
Query web services
Export data from OSLC systems
Launch external processes
If you are interested in developping Data Providers that go beyond the scope of what is described in the open frameworks, consult Squoring Technologies to learn more about the available training courses in writing Data Providers.
After you choose the framework to extend, you should follow these steps to make your custom Data Provider known to Squore:
Create a new configuration tools folder to save your work in your
custom configuration folder: MyConfiguration/configuration/tools.
Create a new folder for your data provider inside the new tools
folder: CustomDP. This folder needs to contain the following files:
form.xml defines the input parameters for the Data Provider, and the base framework to use
form_en.properties contains the strings displayed in the web interface for this Data Provider
config.tcl contains the parameters for your custom Data Provider that are specific to the selected framework
CustomDP.pl is the perl script that is executed automatically if your custom Data Provider uses one of the *Perl frameworks.
Edit Squore Server's configuration file to register your new configuration path, as described in the Installation and Administration Guide.
Log into the web interface as a Squore administrator and reload the configuration.
Your new Data Provider is now known to Squore and can be triggered in analyses. Note that you may have to modify your Squore configuration to make your wizard aware of the new Data Provider and your model aware of the new metrics it provides. Refer to the relevant sections of the Configuration Guide for more information.
Table of Contents
Analysis Models define how metrics data is computed and aggregated. You can browse and analyse models through the Models > Viewer menu in the Squore web interface.
Analysis Models define building blocks organised in a hierarchical structure. The following blocks can be used:
Blocks can refer to each others, for example computations use measures and rules. The syntax used for computations is documented in Chapter 5, Computation Syntax.
You can define any artefact type in your model by declaring them in the
artefactTypes
attribute of your analysis model's RootIndicator
, as shown below.
The following definition of the ROOT main indicator declares the types APPLICATION, FILE, CLASS, FUNCTION, REQUIREMENT,
TEST_PLAN, TEST_SUITE and TEST:
<RootIndicator artefactTypes="APPLICATION;FILE;CLASS;FUNCTION;REQUIREMENT;TEST_PLAN;TEST_SUITE;TEST" indicatorId="ROOT" />
In addition, you can define aliases to group types of artefacts together to use later when defining metrics in your analysis model. The
ArtefactType
definition below groups the artefacts defined above into CODE and DOCUMENT aliases:
<ArtefactType id="CODE" heirs="APPLICATION;FILE;CLASS;FUNCTION" /> <ArtefactType id="DOCUMENT" heirs="REQUIREMENT;TEST_PLAN;TEST_SUITE;TEST" />
This means that the long artefact declaration above can be rewritten as follows:
<RootIndicator artefactTypes="CODE;DOCUMENT" indicatorId="ROOT" />
You can use aliases everywhere in your configuration, except in properties files.
You can also use the ArtefactType
element with a manual
attribute to declare that some artefacts can be added manually by the user, as shown below:
<ArtefactType id="TEST_SUITE" parents="APPLICATION;TEST_SUITE;TEST_PLAN" manual="true" /> <ArtefactType id="TEST" parents="TEST_SUITE" manual="true" /> <ArtefactType id="TEST_PLAN" parents="APPLICATION" manual="true" /> <ArtefactType id="REQUIREMENT" parents="APPLICATION" manual="true" />
Manual artefacts can be added by users with the required permissions via a context menu in the Artefact Tree
The Measure
element defines the semantics of a single measure.
From a technical standpoint, a measure is merely a mapping between the information provided by the Data Provider and known Squore elements.
Base Measures only define the measure name and identifier,
whereas Derived Measures define how they are computed from other measures.
A Measure without computation is a base measure. The following two examples show how the SLOC (Source Lines Of Code)
base measure and the COMR (Comment Rate) derived measure are defined:
<Measure
measureId="SLOC"
targetArtefactTypes="APPLICATION;FILE"
defaultValue="1" />
<Measure measureId="COMR" defaultValue="0">
<Computation stored="true"
targetArtefactTypes=
"APPLICATION;FOLDER;FILE;FUNCTION;CLASS;PROGRAM"
result="(CLOC+MLOC)*100/(SLOC+CLOC)" />
</Measure>The attributes allowed for the Measure
element are as follows:
measureId
(mandatory) is the unique identifier of the measure,
as used in the properties files[1]. Any alphanumerical value is accepted for this attribute as long as it is at least two characters and starts with a letter.
targetArtefactTypes
is the type of artefact targeted by the measure.
For more information about artefact types, consult the section called “Artefact Types”.
excludingTypes
allows refining targetArtefactTypes
to exclude certain types that may have been included via an alias. You can for example specify that a metric exists for all JAVA types except for JAVA_INTERFACE with the following syntax:
<Measure measureId="TEST_COVERAGE" defaultValue="-1">
<Computation targetArtefactTypes="PACKAGES;JAVA" excludingTypes="JAVA_INTERFACE"
result="IF(IS_DP_OK(JACOCO),TST_COV,-1)" />
</Measure>
defaultValue
(optional, default: not set) sets the default value to be used if no value is found for this metric.
usedForRelaxation
(optional, default: false) indicates that the measure is used in this model to indicate whether an
artefact is relaxed of excluded. Note that only one measure per artefact type in your model can use this attribute.
stored
(optional, default: true) defines whether a base measure's value is stored in the database (true) or discarded (false) after an analysis.
suffix
(optional, default: empty) is the label
displayed after the value of the metric in the UI (currently this applies to the Indicator Tree and the Measures tab only).
dataBounds
(optional, default: none) allows
specifying which range of values should be considered valid for this measure (currently this applies to the Indicator Tree and the Measures tab only).
invalidValue
(optional, default: -) is the text
that should be displayed when an invalid value is set for the measure (currently this applies to the Indicator Tree and the Measures tab only).
noValue
(optional, default: ?) is the text
displayed when no value exists for this metric in the database (currently this applies to the Indicator Tree and the Measures tab only).
format
(optional, default: NUMBER) is the format used to display the
value of the measure in the UI. Each supported format has additional parameters, as described below:
- format="NUMBER": (default) + pattern="Java Number Pattern" + decimals="" + roundingMode="" - format="PERCENT": + decimals="" + roundingMode="" - format="INTEGER": + roundingMode="" - format="DATE|TIME|DATETIME": + pattern="Java Date Pattern" + dateStyle="" (only for DATE and DATETIME) + timeStyle="" (only for TIME and DATETIME)
pattern
accepts any Java DecimalFormat or SimpleDate Pattern.
Refer to http://docs.oracle.com/javase/6/docs/api/java/text/DecimalFormat.html and http://docs.oracle.com/javase/6/docs/api/java/text/SimpleDateFormat.html for more information.
decimals
(optional, default: 0) is the number of decimals places to be used for displaying values
roundingMode
(optional, default: HALF_EVEN)
defines the behaviour used for rounding the numerical values displayed. The supported values are:
CEILING to round towards positive infinity.
DOWN to round towards zero.
FLOOR to round towards negative infinity.
HALF_DOWN to round towards "nearest neighbour" unless both neighbours are equidistant, in which case round down.
HALF_EVEN to round towards the "nearest neighbour" unless both neighbours are equidistant, in which case, round towards the even neighbour.
HALF_UP to round towards "nearest neighbour" unless both neighbours are equidistant, in which case round up.
UP to round away from zero.
For more examples of rounding mode, consult http://docs.oracle.com/javase/6/docs/api/java/math/RoundingMode.html.
dateStyle
(optional, default: DEFAULT): the date formatting style,
used when the displayType is one of DATE or DATETIME.
timeStyle
(optional, default: DEFAULT): the time formatting style,
used when the displayType is one of DATETIME or TIME. See above for available styles.
The attributes allowed for the Computation
element are as follows:
targetArtefactTypes
is the type of artefact targeted by this definition.
For more information about artefact types, consult the section called “Artefact Types”.
stored
(optional, default: true) defines whether a derived measure's value is stored in the database (true) or discarded (false) after an analysis.
result
specifies how the measure is computed from other metrics values.
Identifiers used in the result are measureIds, and the syntax is described in Chapter 5, Computation Syntax.
The measure defined is then used with its identifier, prefixed with B. for base measures, or prefixed with D. for derived measures. The following example shows the use of a derived measure for a computation:
<Computation
targetArtefactTypes="APPLICATION;FOLDER;FILE;CLASS;FUNCTION"
result="(D.MET_OKR+D.RULE_OKR)/2" />Tip: Inheritance
Analysis models support inheritance and overriding of metrics according to the following rules:
If a metric is defined twice for a type, the first definition takes priority for this artefact type. An INFO message is displayed in the Validator to inform you that a definition is overriden by another one.
A metric definition for a specific type overrides a metric definition for a more generic type (typically an alias).
As a result, the following definitions are allowed in your Bundle.xml:
Specifying a different computation for one sub-type
<ArtefactType id="MODULES" heirs="FUNCTION" /> <ArtefactType id="FUNCTION" heirs="C_MODULES;PHP_MODULES;JAVA_MODULES" /> <Measure measureId="VG" defaultValue="1"> <Computation targetArtefactTypes="MODULES" result="CCN+TERN+OREL+ANTH+CABL-(CASE+DEF)" /> <Computation targetArtefactTypes="PHP_MODULES" result="CCN+TERN+OREL+ANTH" /> </Measure>
Overriding a computation imported from another file by specifying it before the file import
<?xml version="1.0" encoding="UTF-8"?> <Bundle xmlns:xi="http://www.w3.org/2001/XInclude"> (...) <Measure measureId="COMR" defaultValue="0"> <Computation targetArtefactTypes="CODE" result="IF(ELOC+CLOC=0,-1,(CLOC+MLOC)/(ELOC+CLOC))" /> </Measure> <xi:include href="../../Shared/basic_definitions/comr.xml" />
Rules are a specific type of measure. They do not return a numeric value like other measures, but the location within the source code where the rule was broken. Squore does not define any rule by itself, but requires a mapping between the rules defined in the external tools[2] that provide the compliance measure and internal concepts (and properties files).
An example of rule definition is provided below:
<Measure
measureId="R_NOGOTO"
type="RULE"
categories="SCALE_SEVERITY.REQUIRED;SCALE_PRIORITY.HIGH"
families="REQUIRED;ANALYSABILITY;MISRA;CF;STRP"
targetArtefactTypes="FUNCTION"
defaultValue="0" />The attributes allowed for the Measure
element of type rule are as follows:
measureId
is the unique identifier of the rule, as used in the properties files.
toolName
(optional, default: empty) is the name of the tool, e.g. FINDBUGS, SQuORE, CPPTEST that submitted this metric, to be displayed in the Findings tab. It is generally only specified when you are defining a metric as a rule that will trigger a finding.
toolVersion
(optional, default: empty) is the tool version displayed together with the toolName
in the Findings tab.
categories
defines the scale level returned by Squore when the rule is violated.
families
puts tags on the measure. A common tag is TAB, which displays the rule in the user interface.
targetArtefactTypes
is the type of artefact targeted by this definition.
For more information about artefact types, consult the section called “Artefact Types”.
defaultValue
sets the default value to be used if no value is found for this metric.
manual
(optional, default: false) is used when you want to define a rule that
can be added manually to an artefact in the artefact tree. Manual findings can be added by users with the required permissions via a context menu in the Artefact Tree.
Scales define grades and boundaries for measures, in order to translate them into more understandable information. The ScaleLevel sub-element defines the ranges in the scale.
<Scale scaleId="SCALE_EC">
<ScaleLevel levelId="UNKNOWN" bounds="];0[" rank="-1" />
<ScaleLevel levelId="LEVELA" bounds="[0;0]" rank="0" />
<ScaleLevel levelId="LEVELB" bounds="]0;1]" rank="1" />
<ScaleLevel levelId="LEVELC" bounds="]1;2]" rank="2" />
<ScaleLevel levelId="LEVELD" bounds="]2;3]" rank="3" />
<ScaleLevel levelId="LEVELE" bounds="]3;4]" rank="4" />
<ScaleLevel levelId="LEVELF" bounds="]4;5]" rank="5" />
<ScaleLevel levelId="LEVELG" bounds="]5;]" rank="6" />
</Scale>In this example, the scale SCALE_EC associates different levels to a measured value:
If the measured value is less than 0, the levelId is UNKNOWN with ranking -1.
If the measured value is exactly 0, the levelId is A with ranking 0.
If the measured value is between 0 (excluded) and 1 (included), the levelId is B with ranking 1.
If the measured value is between 1 (excluded) and 2 (included), the levelId is C with ranking 2.
If the measured value is between 2 (excluded) and 3 (included), the levelId is D with ranking 3.
If the measured value is between 3 (excluded) and 4 (included), the levelId is E with ranking 4.
If the measured value is between 4 (excluded) and 5 (included), the levelId is F with ranking 5.
If the measured value is more than 5 (excluded), the levelId is G with ranking 6.
The use of unions in scale bounds has been deprecated since Squore 16.0. You now need to use two distinct scale levels, as shown in the following example:
Old syntax:
<Scale scaleId="SCALE_EC2"> <ScaleLevel levelId="LEVEL_IN" bounds=" ]0;10[|]10;100[" rank="0"/> <ScaleLevel levelId="LEVEL_OUT" bounds="[10;10]" rank="1"/> </Scale>
Current syntax:
<Scale scaleId="SCALE_EC2"> <ScaleLevel levelId="LEVEL_IN_LOW" bounds=" ]0;10[" rank="0"/> <ScaleLevel levelId="LEVEL_OUT" bounds="[10;10]" rank="1"/> <ScaleLevel levelId="LEVEL_IN_HIGH" bounds=" ]10;100[" rank="0"/> </Scale>
Scales can be overridden for a specific artefact type, as shown below:
<Indicator indicatorId="VG" measureId="VG" scaleId="VG" targetArtefactTypes="CODE" />
<Scale scaleId="VG">
<ScaleLevel levelId="UNKNOWN" bounds="];0[" rank="-1" />
<ScaleLevel levelId="GREEN" bounds="[0;6]" rank="0" />
<ScaleLevel levelId="YELLOW" bounds="]6;10]" rank="1" />
<ScaleLevel levelId="RED" bounds="]10;[" rank="2" />
</Scale>
<Scale scaleId="VG" targetArtefactTypes="COBOL_PROGRAM">
<ScaleLevel levelId="UNKNOWN" bounds="];0[" rank="-1" />
<ScaleLevel levelId="GREEN" bounds="[0;10]" rank="0" />
<ScaleLevel levelId="YELLOW" bounds="]10;20]" rank="1" />
<ScaleLevel levelId="RED" bounds="]20;[" rank="2" />
</Scale>The scale VG applies to all artefacts of type CODE, however,
for artefacts of type COBOL_PROGRAM, the scale levels have different bounds than for other types (as
specified via the targetArtefactTypes
attribute).
You can use scale macros in order to avoid duplicating a scale and use parameters ({0}, {1}...) to define the scale level thresholds:
<ScaleMacro id="RGB">
<ScaleLevel levelId="UNKNOWN" bounds="];0[" rank="-1" />
<ScaleLevel levelId="GREEN" bounds="[0;{0}]" rank="0" />
<ScaleLevel levelId="YELLOW" bounds="]{0};{1}]" rank="1" />
<ScaleLevel levelId="RED" bounds="]{1};[" rank="2" />
</ScaleMacro>Scales defined by a macro and its parameters are then specified as shown below:
<Scale scaleId="VG" macro="RGB" vars="6;10" /> <Scale scaleId="VG_REVERSED" macro="RGB" vars="10;6" />
The UNKNOWN level receives special treatment when it comes to showing a trend:
When the rank goes from the UNKNOWN level to any other level, the trend is shown as:

When the rank goes from any level to UNKNOWN, the trend is shown as:

The Scale
element accepts the following attributes:
targetArtefactTypes
(optional) the specific artefacts that this scale applies to. If this attribute
is omitted, then the value of targetArtefactTypes
specified for the indicator using this scale is used.
macro
(optional) specifies the id of the ScaleMacro used to define this scale
vars
(optional) is a semicolon-separated list of parameters to pass to the ScaleMacro to define this scale
isDynamic
(optional, default: false) whether the scale levels are dynamic or not. Read more about the concept of dynamic scales in the section called “Dynamic Scales”.
Scale levels are defined using one or more ScaleLevel
sub-elements,
with the following attributes:
levelId
(mandatory) the unique identifier of the scale level.
bounds
(mandatory) the value limits for this scale level.
Infinite bounds can be specified by omitting the number, e.g.: [0;[ or [0;] for any null or positive number.
rank
(mandatory) the weight of the scale which is used when aggregating values.
The levelIds are then mapped to their language-specific attributes in a properties file.
For the previous example, the file PerformanceLevels_en.properties gives the following mapping:
LOP.LEVELA.MNEMO=A LOP.LEVELA.NAME=Level A LOP.LEVELA.COLOR=0,81,0 LOP.LEVELA.IMAGE=../Shared/Images/images/perfA.png LOP.LEVELA.ICON=../Shared/Images/icons/perfA.png
The trend icons (new, improved, deteriorated and stable) that appear in the artefact tree and the dashboard tables can also be customised in a properties file as shown below:
EVO.TREE_NEW.ICON=Description/new.png EVO.TREE_DOWN.ICON=Description/down.png EVO.TREE_UP.ICON=Description/up.png EVO.TREE_EQUAL.ICON=Description/equal.png EVO.TABLE_NEW.ICON=Description/new.png EVO.TABLE_DOWN.ICON=Description/down2.png EVO.TABLE_UP.ICON=Description/up2.png EVO.TABLE_EQUAL.ICON=Description/equal.png
Indicators associate a measure with a scale.
<Indicator
indicatorId="ROKR_REQ"
measureId="ROKR_REQ"
scaleId="SCALE_DECILE"
families="TAB"
displayTypes="VALUE;LEVEL" />The attributes allowed in the Indicator
tag are the
following:
indicatorId
(mandatory) the unique identifier of the indicator being defined.
measureId
(mandatory) the unique identifier of the measure to map.
scaleId
(mandatory) the unique identifier of the scale to be used for the measure.
targetArtefactTypes
(optional) is the type of artefact targeted by this indicator.
For more information about artefact types, consult the section called “Artefact Types”. If you do not define a target artefact type for an
indicator, then the types specifed for the measure or the scale associated with the indicator are used.
families
(optional) the families associated with the indicator.
displayTypes
(optional, default: empty) specifies which details
relative to the indicator should be displayed in the Indicator tree on the left of the dashboard. The accepted values are
LEVEL to display the level name of the indicator after its name
VALUE to display the actual value of the metric associated to the indicator after its name
displayedScale
(optional) allows displaying an alternate scale in the indicator details popup in
the Explorer instead of the real scale associated with the indicator. This is generally useful when you are using a
complicated scale internally but you want to show something simpler to your users instead (when using dynamic scales for example).
This attribute accepts any valid scale ID from your model.
displayedMeasure
(optional) allows displaying an alternate measure in the indicator details popup in
the Explorer instead of the real measure associated with the indicator. This is generally useful when you are using a
measure internally that would not make sense to end users but you want to show something simpler instead (when using dynamic scales for example).
This attribute accepts any valid measure ID from your model.
In order to quickly define an indicator using the same value for indicatorId
,
measureId
and scaleId
you can use this quick notation syntax:
<Indicator indicatorId="TEST_COVERAGE" />
Squore will automatically assume that measureId and scaleId for this indicator are also TEST_COVERAGE.
Advanced Examples
Defining a single indicator that uses different measures depending on the type of artefact:
<Indicator indicatorId="WEIGHTED_NCC" measureId="WEIGHTED_NCC" targetArtefactTypes="CLASSES;MODULES;CODE_SPECIFICATIONS" /> <Indicator indicatorId="WEIGHTED_NCC" measureId="WEIGHTED_NCC_DENSITY" targetArtefactTypes="PACKAGES;FILES" />
Defining a single indicator that uses different scales depending on the artefact type:
<Indicator indicatorId="COMPLEXITY" /> <Measure measureId="COMPLEXITY" targetArtefactTypes=";" defaultValue="-1"> <Computation targetArtefactTypes="CLASSES;MODULES;CODE_SPECIFICATIONS" result="..." /> <Computation targetArtefactTypes="PACKAGES;FILES" result="..." /> </Measure> <Scale scaleId="COMPLEXITY" macro="TRAFFIC_LIGHT" vars="5;30" targetArtefactTypes="CLASSES;MODULES;CODE_SPECIFICATIONS" /> <Scale scaleId="COMPLEXITY" macro="TRAFFIC_LIGHT" vars="20;200" targetArtefactTypes="PACKAGES;FILES" />
An indicator must be specified as the root indicator for a each artefact type. The root indicator is the top-level mark displayed next to an artefact in the artefact tree.
<RootIndicator
indicatorId="MAINTAINABILITY"
artefactTypes="APPLICATION;FILE;FUNCTION" />
indicatorId
the unique identifier of the indicator chosen as root.
artefactTypes
is the type of artefact for which this indicator is the root indicator. It is one or
more of APPLICATION, SOURCE_CODE, FOLDER, FILE, CLASS, PROGRAM, FUNCTION, or any other type defined for your project. Note that the indicator
must exist for all the types of artefacts specified.
A root indicator must be based on a derived measure, not a base measure. If the measure you want to use as an indicator is a base, add a dummy derived measure as shown below.
Before:
<Measure id="ROOT" targetArtefactTypes="TYPE" defaultValue="0" />
After:
<Measure id="ROOT" targetArtefactTypes="TYPE" defaultValue="0"> <Computation targetArtefactTypes="SOME_OTHER_TYPE" result="B.ROOT" /> </Measure>
In order to allow users to relax or exclude artefacts from the projects from the Artefact Tree, you need to reserve one measure that uses a special attribute used for relaxation and specify to which artefact types it applies.
The following is a basic example of how to allow users to relax folders and files in your model:
myModel/Analysis/Bundle.xml: <ArtefactType id="RELAXABLE" heirs="FOLDER;FILES" /> <Measure measureId="RELAX" targetArtefactTypes="RELAXABLE" defaultValue="0" usedForRelaxation="true" />
By adding these two lines in your model, you allow users whose role grant the View Drafts of Projects and Modify Artefacts privileges to use the relaxation mechanism. For more information about using artefact relaxation from the web UI, consult the Getting Started Guide or the online help.
Impact on computations
When an artefact is relaxed, its metrics are ignored when computing metrics for other artefacts. This makes sense for example when relaxing a folder full of third-party code, because you may not want the total number of software lines of code to include third-party code.
In other situations, it does not make
sense to exclude all metrics from relaxed artefacts: If you are analysing components of a system and aggregate
memory usage information up to the application level for example, third-party components for which you relax source code issues
should still be part of the total memory usage for the system. In the latter case, you can use the
continueOnRelaxed
attribute to indicate that some or all measures should be included
in computations even if the artefact has been relaxed. This is explained in the two examples below.
In the following code continueOnRelaxed
is set to true
for the metric used to mark artefacts as relaxed (usedForRelaxation
). As a result, all measures of the
relaxed artefact are included in computations for other artefacts:
<ArtefactType id="RELAXABLE" heirs="FOLDER;FILES" /> <Measure measureId="RELAX" targetArtefactTypes="RELAXABLE" usedForRelaxation="true" continueOnRelaxed="true" defaultValue="0" />
In the following code, continueOnRelaxed
is set to true at computation-level.
As a result, the measure MEMORY is included in computations
even when the artefact is relaxed. No other measures are included in computations for relaxed artefacts, since
continueOnRelaxed
is omitted from the definition of RELAX:
<ArtefactType id="RELAXABLE" heirs="FOLDER;FILES" /> <Measure measureId="RELAX" targetArtefactTypes="RELAXABLE" usedForRelaxation="true" defaultValue="0" /> <Measure measureId="MEMORY" defaultValue="0"> <Computation targetArtefactTypes="APPLICATION;FODLER" result="SUM FILE.MEMORY FROM DESCENDANTS" continueOnRelaxed="true"/> </Measure>
Only artefacts of type FOLDER and FILES should be relaxable. If you
need to find out if an artefact is relaxed in your model, you can use the IS_RELAXED_ARTEFACT() function
described in the section called “Conditional and Level-Related Functions”.
Squore allows you to define links between artefacts. The links are generally created by Data Providers in your model (see the section called “Creating your own Data Providers”), and are displayed automatically in tables on the dashboard, as shown below:
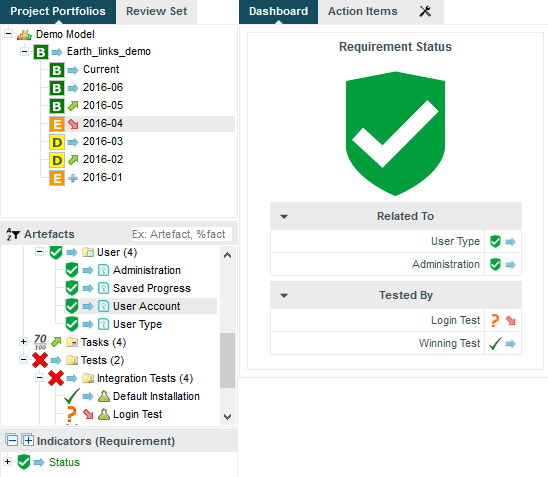
Links to related requirements and tests in the scorecard of a requirement
Links in the scorecard can be clicked to navigate to the target artefact directly.
For more information about advanced display options for links, consult the section called “Scorecard Tables”.
Links are declared in the analysis model using a Links
element, which accepts the following attributes:
id
(mandatory) is the unique identifier for the link type in your model
inArtefactTypes
(optional, default: any) is a list of possible artefact types that can generate inbound links for this type of link.
outArtefactTypes
(optional, default: any) is a list of possible artefact types that this type of link can link create outbound links to.
The links shown in the picture above can be defined as follows:
<Link id="TEST" inArtefactTypes="REQUIREMENT" outArtefactTypes="TEST_CASE" /> <Link id="RELATED_REQ" inArtefactTypes="REQUIREMENT" outArtefactTypes="REQUIREMENT" />
It is not strictly necessary to declare all your link types in the analysis model. The only case when this is necessary
is when you want to use a condition in the LINKS() function, which you can read about in the section called “Conditional and Level-Related Functions”.
Constants are used to resolve a symbol to a number. They are defined with the Constant
XML tag.
<Constant id="HIS_MET" value="12" />
Two attributes are required to define a constant:
A constant can then be used in a computation by prefixing it with C., e.g.:
<Computation
targetArtefactTypes="APPLICATION;FOLDER;FILE;CLASS;FUNCTION"
result="100*(1-(MET_KO/C.HIS_MET))" />A constant can also be used in a scale level. Note that in this kind of usage, the constant ID does note require a prefix, as shown below:
<ScaleLevel levelId="LEVELG" bounds="]5;]" rank="HIS_MET" />
Dynamic scales are scales whose levels use measures instead of absolute bounds. They are useful when one metric has a different meaning according to the context in which it is read. In software development for example, you may accept a certain amount of specification changes at one stage of the process, but completely want to prohibit it at another stage. This section takes you through an example that can be implemented easily in your model with the use of dynamic scales.
What we want to guarantee with our dynamic scale, is that during three different phases of development, our requirements stability indicator is evaluated differently, as represented below:
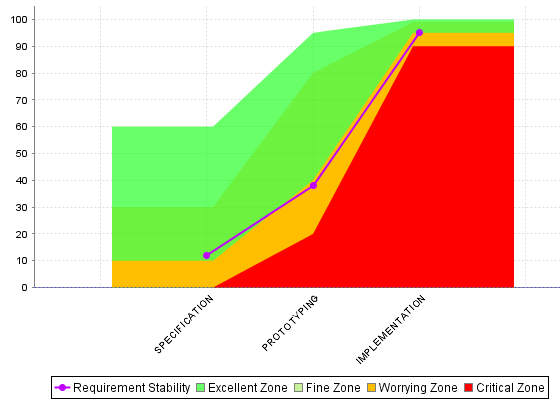
Requirement Stability by Development Phase.
The following is an example of a dynamic scale definition for a KPI that evaluates the stability of requirements as excellent, fine, worrying, critical or unknown:
<Scale scaleId="DYN_SCALE_REQ_STABILITY" isDynamic="true">
<ScaleLevel levelId="DYN_EXCELLENT" bounds="[APP(EXCELLENT_THRESHOLD);[" rank="0" />
<ScaleLevel levelId="DYN_FINE" bounds="[APP(FINE_THRESHOLD);APP(EXCELLENT_THRESHOLD)[" rank="1" />
<ScaleLevel levelId="DYN_WORRYING" bounds="[APP(WORRYING_THRESHOLD);APP(FINE_THRESHOLD)[" rank="2" />
<ScaleLevel levelId="DYN_CRITICAL" bounds="[APP(CRITICAL_THRESHOLD);APP(WORRYING_THRESHOLD)[" rank="3" />
<ScaleLevel levelId="DYN_UNKNOWN" bounds="];APP(CRITICAL_THRESHOLD)[" rank="4" />
</Scale>Compared with the examples of scales shown in the section called “Scales”, note
the use of the isDynamic
attribute and
how the bounds are expressed with measures instead of actual values.
The threshold measures can vary for each analysis and/or for each artefact type, and the scale may therefore be different as time goes by. There are two ways they could be set:
By using attributes at application levels so that users define the values of the thresholds manually.
By computing the thresholds during the analysis with IF(), CASE() or
other available functions described in the section called “Functions”
Here is an example setting the thresholds according to a PHASE attribute set by the user
before running an analysis (more information about attributes is available in the section called “Attributes”:
<!-- Attribute Definition in Wizard --> <tag type="multipleChoice" name="Development Phase: " measureId="PHASE" defaultValue="SPECIFICATION" displayType="radioButton" targetArtefactTypes="APPLICATION"> <value key="SPECIFICATION" value="1" /> <value key="PROTOTYPING" value="2" /> <value key="IMPLEMENTATION" value="3" /> </tag> <!-- Metrics Definition in Analysis Model --> <Measure measureId="PHASE" targetArtefactTypes="APPLICATION" defaultValue="0" /> <Constant id="PHASE_SPECIFICATION" value="1" /> <Constant id="PHASE_PROTOTYPING" value="2" /> <Constant id="PHASE_IMPLEMENTATION" value="3" /> <!-- Thresholds Computation in Analysis Model --> <Measure measureId="EXCELLENT_THRESHOLD"> <Computation targetArtefactTypes="APPLICATION" result="CASE(PHASE, C.PHASE_SPECIFICATION:60, C.PHASE_PROTOTYPING:95, C.PHASE_IMPLEMENTATION:100, DEFAULT:-1)"/> </Measure> <Measure measureId="FINE_THRESHOLD"> <Computation targetArtefactTypes="APPLICATION" result="CASE(PHASE, C.PHASE_SPECIFICATION:30, C.PHASE_PROTOTYPING:80, C.PHASE_IMPLEMENTATION:99, DEFAULT:-1)"/> </Measure> <Measure measureId="WORRYING_THRESHOLD"> <Computation targetArtefactTypes="APPLICATION" result="CASE(PHASE, C.PHASE_SPECIFICATION:10, C.PHASE_PROTOTYPING:40, C.PHASE_IMPLEMENTATION:95, DEFAULT:-1)"/> </Measure> <Measure measureId="CRITICAL_THRESHOLD"> <Computation targetArtefactTypes="APPLICATION" result="CASE(PHASE, C.PHASE_SPECIFICATION:0, C.PHASE_PROTOTYPING:20, C.PHASE_IMPLEMENTATION:90, DEFAULT:-1)"/> </Measure>
The final REQUIREMENTS_STABILITY indicator is associated with a static scale that uses the same ranks as the dynamic one,
and its value is assigned by retrieving the desired rank from the dynamic scale using the FIND_RANK() function:
<!-- Static scale to base the KPI on -->
<Scale scaleId="SCALE_REQ_STABILITY">
<ScaleLevel levelId="EXCELLENT" bounds="[0;0]" rank="0" />
<ScaleLevel levelId="FINE" bounds="[1;1]" rank="1" />
<ScaleLevel levelId="WORRYING" bounds="[2;2]" rank="2" />
<ScaleLevel levelId="CRITICAL" bounds="[3;3]" rank="3" />
<ScaleLevel levelId="UNKNOWN" bounds="[4;4]" rank="4" />
</Scale>
<!-- Indicator definition -->
<Indicator indicatorId="REQUIREMENTS_STABILITY"
measureId="REQ_STABILITY_RANK"
targetArtefactTypes="APPLICATION;FOLDER;FILE"
scaleId="SCALE_REQ_STABILITY" />
<!-- The base measure that holds the actual raw value of Requirement Stability -->
<Measure measureId="REQUIREMENTS_STABILITY_METRIC"
targetArtefactTypes="APPLICATION;FOLDER;FILE" defaultValue="0" />
<!-- A temporary measure to compute the rank of the metric on the dynamic scale -->
<Measure measureId="REQ_STABILITY_RANK">
<Computation stored="false" targetArtefactTypes="APPLICATION;FOLDER;FILE"
result="FIND_RANK(DYN_SCALE_REQ_STABILITY, REQUIREMENTS_STABILITY_METRIC)" />
</Measure>For more information about the FIND_RANK() function, refer to the section called “Functions”.
When using dynamic scales, the scale and measure computed for an indicator may not make sense for the end user. In this case, you may
want to change what the user sees via the use of the displayedScale
and displayedMeasure
attributes in your indicator definition. For more information about this syntax, consult the section called “Indicators”.
This chapter details the concept of the decision model, and the methods available for building an action plan in Squore.
A Decision Model defines how to build an Action Plan in Squore. The list of action items triggered during an analysis defines the to-do list that can be followed to improve the quality of a project.
There are two types of decision models available in Squore:
If you have a precise idea of which actions items should be part of your action plan for your model, you can define a list of tests to run against the metrics generated when running an analysis to build an action plan. This type of action plan is described in the section called “Trigger-Based Action Plans”.
If you prefer to build an action plan automatically based on the findings found during the analysis, you can let Squore build a prioritised action plan according to the categories of findings which are most important to you. This type of action plan is described in the section called “Dynamic Action Plans”.
It is currently not possible to configure a decition model that uses both manually-set triggers and dynamic findings prioritisation.
The easiest way to instruct Squore to build a dynamic action plan for your model based on the
findings generated during an analysis is to ensure that your model folder contains no Decision/Bundle.xml file.
A list of the Top 40 valuable actions will be created for the project. This list is shown to all users
in the Action Items tab of the Explorer.
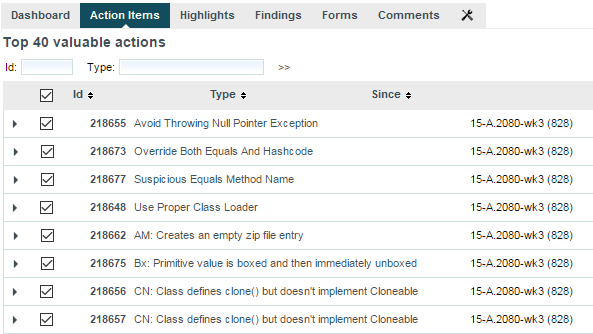
Part of the Top 40 valuable actions dynamically generated for a source code project
By default, action items are created based on findings in the project using these criteria:
Findings with the lowest remediation cost
Findings with the highest severity
Findings with the lowest number of occurrences
This can be specified in your Bundle.xml as follows:
$SQUORE_HOME/configuration/MyModelFolder/Decision/Bundle.xml:
<Bundle>
<FindingsActionPlan limit="40">
<CategoryCriterion type="COST" scaleId="SCALE_REMEDIATION"
preferenceLevel="MEDIUM"
excludeLevels="UNKNOWN;NONE" />
<CategoryCriterion type="BENEFIT" scaleId="SCALE_SEVERITY"
preferenceLevel="MEDIUM"
excludeLevels="UNKNOWN;INFORMATION" />
<OccurrencesCriterion type="COST" preferenceLevel="MEDIUM" />
</FindingsActionPlan>
</Bundle>Dynamic Action Plan Syntax
The FindingsActionPlan
element accepts the following attributes:
limit
(optional, default: 40) defines how many action items to generate
priorityScaleId
(optional, default: SC_DEFAULT_PLANNER_PRIORITY) defines the priority scale used
in the Action Items tab to distribute the action items. The default scale uses 20 levels to spread all the possible combinations of
remediation costs, severities and number of occurrences evenly. You can define your own scale with more or less levels and even or uneven
levels to distribute the combinations of possible action items.
There are three types of criteria that you can use to prioritise findings:
Each type of criterion accepts the following attributes:
scaleId
(mandatory, not supported for VariableCriterion)
is the scale to look up to build the criterion on.
indicatorId
(mandatory, only supported in VariableCriterion)
is the indicator to specify a VariableCriterion
type
(optional, default: COST)
defines which end of the scale to pull findings from in priority. Supported values are:
COST to get findings with the lowest rank on the scale turned into action items first. This makes sense on a remediation cost scale, where you want to fix findings with the lowest remediation cost first.
BENEFIT to get findings with the highest rank on the scale turned into action items first. This makes sense on a severity scale, where you want to fix findings with the highest severity first.
excludeLevels
(optional, default: none) allows excluding scale levels from
the criterion. This attribute allows a list of scale levels, as shown in the example above.
preferenceLevel
(optional, default: MEDIUM)
is used to weigh the criterion against the other criteria in the overall calculation of the action item's priority. Supported values are:
VERY_LOW
LOW
MEDIUM
HIGH
VERY_HIGH
Here is an example that expands on the default shown earlier to take into account the test coverage of artefacts and make sure that action items are generated mostly for artefacts with a high test coverage ratio. The scale used as well only contains five levels from P1 to P5 and will single out very high and very log priority items (the relevancy of an action item is a number between 0 and 100 that is measured against this scale to define the priority):
$SQUORE_HOME/configuration/MyModelFolder/Decision/Bundle.xml:
<Bundle>
<FindingsActionPlan limit="40" priorityScaleId="SCALE_LEVEL_FIVE">
<CategoryCriterion type="COST" scaleId="SCALE_REMEDIATION"
preferenceLevel="MEDIUM"
excludeLevels="UNKNOWN;NONE" />
<CategoryCriterion type="BENEFIT" scaleId="SCALE_SEVERITY"
preferenceLevel="MEDIUM"
excludeLevels="UNKNOWN;INFORMATION" />
<OccurrencesCriterion type="COST" preferenceLevel="MEDIUM" />
<VariableCriterion type="BENEFIT" preferenceLevel="VERY_HIGH"
indicatorId="TEST_COVERAGE" />
</FindingsActionPlan>
<Bundle>
Where SCALE_LEVEL_FIVE is:
<Scale scaleId="SCALE_LEVEL_FIVE">
<ScaleLevel levelId="P0" bounds="[0;5]" rank="0" />
<ScaleLevel levelId="P1" bounds="]5;15]" rank="1" />
<ScaleLevel levelId="P2" bounds="]15;65]" rank="2" />
<ScaleLevel levelId="P3" bounds="]65;85]" rank="3" />
<ScaleLevel levelId="P4" bounds="]85;95]" rank="4" />
<ScaleLevel levelId="P5" bounds="]95;100]" rank="5" />
</Scale>If you want to use a combination of metrics to trigger action plans instead of relying on prioritising findings, Squore allows building your own specification of triggers for action items. The following is an example of a Decision Bundle where an action item is based on specific triggers:
<?xml version="1.0" encoding="utf-8" standalone="yes"?>
<Bundle>
<DecisionCriteria>
<DecisionCriterion dcId="DR_FU_UNTESTABLE" categories=
"SCALE_PRIORITY.MEDIUM"
roles="DEVELOPER;PROJECT_MANAGER"
targetArtefactTypes="FUNCTION">
<Triggers>
<Trigger>
<Test expr="VG" bounds="[20;[" descrId="UNTESTABLE_VG"
p0="#{MEASURE.VG}" />
<Test expr="NEST" bounds="[4;[" descrId="UNTESTABLE_NEST"
p0="#{MEASURE.NEST}" />
<Test expr="NPAT" bounds="[800;[" descrId="UNTESTABLE_NPAT"
p0="#{MEASURE.NPAT}" />
</Trigger>
<Trigger>
<Test expr="VG" bounds="[50;[" descrId="UNTESTABLE_VG"
p0="#{MEASURE.VG}" />
</Trigger>
</Triggers>
</DecisionCriterion>
</DecisionCriteria>
</Bundle>A DecisionCriterion
is an action item definition.
At least one trigger
must be true to trigger the automatic generation
of an action item on an artefact whose type is defined in the targetArtefactTypes
attribute of a DecisionCriterion
. A trigger is true when all its tests evaluate to true.
When using the role
attribute for a DecisionCriterion
, you
limit the visibility of the Action Items defined to the roles listed only. If the attribute is not present, then
the action item is visible to all users who can view the project.
Remember that a decision criterion will evaluate its Triggers using OR, whereas a trigger will evaluate its Tests using AND.
Writing a Test
Writing a test, requires using the following mandatory attributes:
expr
is the expression of the computation, see Chapter 5, Computation Syntax for more details.
bounds
is the interval within which the computation result evaluates to true.
The syntax is the same as the one used for defining scaleLevel
bounds (see the section called “Scales”),
but you can also use some computations via the following syntax:
For constants: C.<constantId>
For measures: <measureId>
For application-level measures: APP(<measureId>)
As an example, the following bound definition is valid to trigger an action item:
bounds="[APP(LC);C.CST_X["
The following optional attributes may also be used:
Table of Contents
Computation formulae are used in two contexts:
Basic examples of Computations and Trigger are shown below:
<Measure measureId="CLSTAB_DEBT" defaultValue="0"> <Computation targetArtefactTypes="FILE;FOLDER;APPLICATION" result="SUM CLASS.I.STABILITY FROM DESCENDANTS" /> </Measure> <Trigger> <Test expr="COUNT RULE.OCCURRENCES FROM DESCENDANTS" bounds="[1;[" descrId="PRESENTATION_COMPOUND" /> </Trigger>
A computation is built on operands, i.e. any element defined in the model (rules, indicators, measures, etc...) used with operators and optionally restricted to a predefined scope.
There are two ways to write the formula used to compute the results, depending on the results you are trying to achieve:
The following sections will cover the use of operands and the syntax used for simple calculations and queries.
An operand is any element defined in the model, called with its unique identifier (ID).
Measures may be prefixed with B when a Base and a Derived measure share the same ID, and
you want to make sure that Squore uses the base measure in your syntax.
The following example shows a computation that adds and divides the TOPD (Operand Occurrences), TOPT (Operator Occurrences), DOPD (Distinct Operands), DOPT (Distinct Operators) measures.
<Computation targetArtefactTypes="FUNCTION" result="(TOPD+TOPT)/(DOPD+DOPT)" />
Rules have different attributes that can be called in expressions.
families attribute, e.g. WHERE FAMILY=REQUIRED.Below is an example of computation using rules attributes:
<Test expr="COUNT RULE.OCCURRENCES FROM DESCENDANTS WHERE FAMILY=CPRS" bounds="[10;[" descrId="PRESENTATION_CPRS" />
Indicators are prefixed with a I. The following example shows a computation which sums the values of the SDOC (Self-Descriptiveness), DFCX (Data Flow Complexity), and CFCX (Control Flow Complexity) indicators.
<Computation targetArtefactTypes="FUNCTION" result="I.SDOC+I.DFCX+I.CFCX" />
Examples of operands are: RULES.OCCURRENCES, FAMILY, MEASUREID, FUNCTION, PROGRAM.LEVEL, FUNCTION.I.HIS_LEVL, etc.
In order to compute results for the current artefact, the basic operators
+, -, * and /
allow to respectively add, subtract, multiply and divide the values of
two operands. Parentheses are allowed at any nesting level.
The following examples describe valid uses of the operators in Squore models. Note that spaces were added between operands to simplify reading the formulae, but they are not required.
Take the value of LC, subtract SLOC and add 10:
<Measure measureId="COMR" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="LC - SLOC + 10" /> </Measure>
Using both base and derived measures (B.SLOC and SLOC respectively)
in the same calculation:
<Measure measureId="COMR" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="LC - B.SLOC + (-04 - SLOC)" />
Multiplying operands:
<Measure measureId="COMR" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="LC * SLOC * 6.0" /> </Measure>
Using the opposite value of an operand:
<Measure measureId="COMR" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="0.1 * -LC + 2 * -SLOC * 3" /> </Measure>
Dividing values:
<Measure measureId="COMR" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="LC + 2 / 2" /> </Measure>
Using the ranking of a measure instead of its value:
<Measure measureId="COMR" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="I.LC + I.SLOC / 3.5" /> </Measure>
Using the ranking of the root indicator for the artefact:
<Measure measureId="COMR" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="RANK + LC" /> </Measure> or <Measure measureId="COMR" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="LEVEL + LC" /> </Measure>
Using the number of times the rule R_COMPOUNDIF was violated for the artefact:
<Measure measureId="COMR" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="R.R_COMPOUNDIF * 2" /> </Measure>
Note: If an erroneous formula is used, the measure will use the default value instead of the result of the computation:
<Measure measureId="COMR" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="LC / 0" /> </Measure>
You can use the operators MIN(param[,param,param...]), MAX(param[,param,param...]),
ABS(param),
and AVR(param[,param,param...]) if you need to determine the minimum, maximum, absolute or average
value in a set of parameters.
For more advanced calculations, the following functions are also available:
EXP(<Computation> value) to calculate the exponential of a value
LN(<Computation> value) to calculate the natural logarithm of a value
LOG(<Computation> value, <Computation> base) to calculate the logarithm of a value
POW(<Computation> value, <Computation> power) to calculate a power
SQRT(<Computation> value) to calculate a square root
ROUND(<Computation> value) to round a number to the nearest integer
FLOOR(<Computation> value) to round down a number to the nearest integer
CEIL(<Computation> value) to round up a number to the nearest integer
CENTROID(<Computation> value [| <computation> weight], ...) to calculate the centroid of comma-separated pairs of value|weight. If no weight is specified, it is set to 1.
FCENTROID(<Computation> min, <Computation> max, <Computation> value [| <computation> weight], ...) to calculate the filtered centroid of comma-separated pairs of value|weight. When using the FCENTROID() function, only the values within min and max are used to calculate a CENTROID(). To specify infinity as a bound, leave the value of min or max empty. If no values match the filter, the default value is returned.
FMIN(<Computation> min, <Computation> max, <Computation> value [, <Computation> value, <Computation> value...]) to calculate the filtered minimum of comma-separated values. When using the FMIN() function, only the values within min and max are used to calculate a MIN(). To specify infinity as a bound, leave the value of min or max empty. If no values match the filter, the default value is returned.
FMAX(<Computation> min, <Computation> max, <Computation> value [, <Computation> value, <Computation> value...]) to calculate the filtered maximum of comma-separated values. When using the FMAX() function, only the values within min and max are used to calculate a MAX(). To specify infinity as a bound, leave the value of min or max empty. If no values match the filter, the default value is returned.
FSUM(<Computation> min, <Computation> max, <Computation> value [, <Computation> value, <Computation> value...]) to calculate the filtered sum of comma-separated values. When using the FSUM() function, only the values within min and max are used to calculate a SUM(). To specify infinity as a bound, leave the value of min or max empty. If no values match the filter, the default value is returned.
Examples
Using a measure if it is above a threshold, else use the threshold:
<Measure measureId="EXAMPLE" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="MAX(10,VG)" /> </Measure>
Using the higher of two measures:
<Measure measureId="EXAMPLE" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="MAX(LC,SLOC)" /> </Measure>
Using lower of three indicators:
<Measure measureId="EXAMPLE" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="MIN(I.TESTABILITY, I.CHANGEABILITY, I.ANALISABILITY)" /> </Measure>
Example preventing division by 0:
<Measure measureId="EXAMPLE" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="LC / MAX(STAT, 1)" /> </Measure>
Example retrieving the variation of a measure:
<Measure measureId="EXAMPLE" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="ABS(DELTA_VALUE(LC))" /> </Measure>
Example using nested MIN and MAX functions:
<Measure measureId="EXAMPLE" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="MIN(MAX(SLOC+(BLANK/2),1000),MAX(LC,1000))+2" /> </Measure>
Calculating the average of three indicators:
<Measure measureId="EXAMPLE" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="AVR(I.TESTABILITY, I.CHANGEABILITY, I.ANALISABILITY)" /> </Measure>
Calculating the centroid of 3 with weight 3 and 2 with weight 100 (=2.03):
Note: this translates to (3x3 + 2x100) / (100+3)
<Measure measureId="MATH_CENTROID_3_3_2_100" defaultValue="0"> <Computation targetArtefactTypes="APPLICATION" result="CENTROID(3|3,2|100)"/> </Measure>
Calculating the filtered centroid of TESTABILITY/STABILITY/MAINTAINABILITY:
Given the scale:
level: UNKNOWN, rank: -1
level: LEVELA, rank: 0
level: LEVELB, rank: 1
level: LEVELC, rank: 2
and given that I.TESTABILITY is UNKNOWN, I.STABILITY is LEVELB, I.MAINTAINABILITY is LEVELC
<Measure measureId="MATH_FCENTROID" defaultValue="0"> <Computation targetArtefactTypes="APPLICATION" result="FCENTROID(0,,I.TESTABILITY|3,I.STABILITY|2,I.MAINTAINABILITY)"/> </Measure>
I.TESTABILITY is filtered out as it is not between the specified minimum and maximum.
The value is then computed as CENTROID(I.STABILITY|2,I.MAINTAINABILITY), which is (1x2 + 2) / (2+1).
Understanding filtered min, max and sum:
FMIN(,,-2,4,11) is equivalent to: FMIN(-Infinity,+Infinity,-2,4,11) is equivalent to: MIN(-2,4,11)
FMIN(0,10,-2,4,11) is equivalent to: MIN(4,11)
FMIN(0,1,-2,4,11) is equivalent to: MIN(), which evaluates to null and leads to using the default value of the measure and marking it in the indicator tree with the status ERROR.
FMIN(2,,1,I.LC) is equivalent to: FMIN(2,+Infinity,1,I.lC) is equivalent to: MIN(I.LC) resolves to: I.LC if LC >= 2, else default value
FSUM(,,1,2.5,2>1,3) is evaluated as: 1 + 2.5 + 1 + 3
FSUM(2,4,1,2.5,2>1,3) is evaluated as: 2.5 + 3
FSUM(6,,-1,I.LC,LC) resolves to: I.LC if >= 6 or LC if >= 6
More advanced decisions can be made when using the following conditional and level-related functions:
You can use the IF(cond,val_yes,val_no) function to assign different
values based on the result of a condition. Note that nested IF constructions are allowed, and an IF block can contain OR or AND operators.
A condition is simply a computation that returns 1 if true and 0 if false. For example,
result="SLOC>50"
returns 1 or 0 depending on the value of SLOC for the current artefact.
Use the CASE(measureId,case1:value1,case2:value2[,...][,DEFAULT:value]) function to
assign different values to a measure based on the value of another measure. A fallback can be specified
by using the DEFAULT case.
The NOT(computation) function returns 0 if the result of the computation
is greater than or equal to 1, or 1 otherwise.
The RANK(scale_id,level_id) function provides a way to retrieve rank values
from your model.
The FIND_RANK(scale_id,measure_id) function provides a way to retrieve a rank
from your model by passing a measure and a scale.
The APP(measure_id) function provides a way to retrieve the value of a measure
at application level from any artefact:
The PARENT(measure_id, [type]) and ANCESTOR(measure_id, [type]),
functions provide a way to get a measure value for an artefact's parent or ancestor containing this measure.
The concept is similar to that of the APP() function, but
PARENT() only checks the artefact's direct parent and ANCESTOR() goes up the
tree until finding an artefact (of the optionally specified type) that has the requested measure ID.
Both functions have an equivalent filtered function to limit the scope of the values included in the search, using the
syntax FPARENT(min,max,measure_id, [type]) and FANCESTOR(min,max,measure_id, [type]). Note
that if min or max are omitted, they are automatically replaced by -Infinity
and +Infinity respectively.
The IS_DP_OK(data_provider_name) function provides a way to find out
if a Data Provider was executed successfully or not during the analysis. If the data
provider was not executed or failed, the function returns 0. If the Data Provider was
executed successfully, then the function returns 1.
The DP_STATUS(data_provider_name) function provides finer information
about the execution status of a Data Provider than IS_DP_OK().
returns -1 if the DP was not run
returns 0 if the DP was successful
returns 1 if the DP returned some warnings
returns 2 if the DP reported errors
returns 3 if the DP stopped with a fatal error
The IS_ARTEFACT_TYPE(artefact_type) function provides a way to find out
if an artefact is of the type specified. If the artefact is of the type specified, the function returns 1,
else it returns 0.
IS_NEW_ARTEFACT() tests whether the artefact is new for the current version
of the project. It returns 1 if true, 0 if false.
The IS_RELAXED_ARTEFACT() function provides a way to find out if an artefact's relaxation status. It returns 1 if
an artefact is relaxed and 0 if it is not.
IS_NEW_FINDING() allows determining if a finding is new in the latest analysis or not.
It returns 1 if true, 0 if false.
The LINKS(<linkTypeId> [, OUT|IN|IN_OUT] [, CONDITION]) function returns the number of links for an artefact. It requires defining the type of link to consider (linkTypeId) and optionally allows to specify an extra parameter to refine which link directions to consider:
OUT counts only outbound links (links from this artefact to other artefacts)
IN counts only inbound links (links from other artefacts to this artefact)
IN_OUT counts all links for this artefact and is the default value if none is specified
The function also allows defining a condition to filter out unwanted links when counting. The condition is verified against the target artefacts according to the specified link direction. In order for the condition to be taken into account, the link type and its supported IN and OUT artefacts must be declared in the analysis model, see the section called “Artefact Links” for more details.
Examples
Set a measure to 6 if SLOC is above a threshold, else set it to 4:
<Measure measureId="EXAMPLE" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="2+IF(SLOC>50,4,2)" /> </Measure>
Set a measure to 6 if SLOC is above a value and below another one, else set it to 4:
<Measure measureId="EXAMPLE" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="2+IF(SLOC>50 AND SLOC<100,4,2)" /> </Measure>
A nested IF construction:
<Measure measureId="EXAMPLE" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="2+IF(I.LC>IF(SLOC>300,SLOC,MAX(250,300)),98,8)" /> </Measure>
Example using NOT:
<Measure measureId="OLD_LARGE_FILE" defaultValue="0"> <Computation targetArtefactTypes="FILE" result="NOT(IS_NEW_ARTEFACT() AND SLOC<500)" /> </Measure>
An example of CASE() statement (on the metric :
<Measure measureId="EASE_OF_USE" defaultValue="0"> <Computation targetArtefactTypes="APPLICATION" result="CASE(FEEDBACK,BAD:0,GOOD:50,EXCELLENT:80,DEFAULT:-1)" /> </Measure>
Retrieving rank values using RANK(), given the following scale:
<Scale scaleId="SCALE_LINE"> <ScaleLevel levelId="LEVELA" bounds="];10]" rank="0" /> <ScaleLevel levelId="LEVELB" bounds="]10;30]" rank="1" /> <ScaleLevel levelId="LEVELC" bounds="]30;60]" rank="2" /> <ScaleLevel levelId="LEVELD" bounds="]60;100]" rank="4" /> <ScaleLevel levelId="LEVELE" bounds="]100;[" rank="8" /> </Scale>
You can use the RANK function as follows to find the rank of LEVELD. The example below returns 4:
<Measure measureId="EXAMPLE" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="RANK(SCALE_LINE,LEVELD)" /> </Measure>
For more information about scales, refer to the section called “Scales”.
Using RANK is useful when combined with conditions. The examples below are equivalent:
<Measure measureId="EXAMPLE" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="IF(I.LC>4,1,0)" /> </Measure>
<Measure measureId="EXAMPLE" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="IF(I.LC>RANK(SCALE_LINE,LEVELD),1,0)" /> </Measure>
<Measure measureId="EXAMPLE" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="IF(I.LC>LEVELD,1,0)" /> </Measure>
In the last example, we use the short syntax for the RANK function: >LEVELD
is only valid when used after an indicator. The rank retrieved is the rank of level LEVELD for the scale
of the current artefact type for the indicator LC.
The FIND_RANK() function is mostly useful when using dynamic scales
(see the section called “Dynamic Scales”). The example below assigns to TEST_COVERAGE_RANK
the value of the rank for the value of COVERAGE on the scale DYN_SCALE_OK_KO:
<Measure measureId="OBJECTIVE" targetArtefactTypes="APPLICATION;FODLER;FILE;CLASS" defaultValue="0" />
<Measure measureId="COVERAGE" targetArtefactTypes="APPLICATION;FODLER;FILE;CLASS" defaultValue="0" />
<Scale scaleId="DYN_SCALE_OK_KO">
<ScaleLevel levelId="DYN_OK" bounds="[;APP(OBJECTIVE)]" rank="0" />
<ScaleLevel levelId="DYN_KO" bounds="[APP(OBJECTIVE);]" rank="1" />
</Scale>
<Scale scaleId="SCALE_OK_KO">
<ScaleLevel levelId="OK" bounds="[1;1]" rank="0" />
<ScaleLevel levelId="KO" bounds="[0;0]" rank="1" />
</Scale>
<Measure measureId="TEST_COVERAGE_RANK">
<Computation targetArtefactTypes="APPLICATION"
result="FIND_RANK(DYN_SCALE_OK_KO,COVERAGE)" />
</Measure>
<Indicator
indicatorId="TEST_COVERAGE"
measureId="TEST_COVERAGE_RANK"
scaleId="SCALE_OK_KO" />Compute the percentage of lines of code present in the current artefact
using the entire application as the reference, with APP():
<Measure measureId="EXAMPLE" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="(LC*100)/APP(LC)" /> </Measure>
Mark a method as risky if the parent class has changed, using PARENT():
<Measure measureId="RISKY" defaultValue="0"> <Computation targetArtefactTypes="FUNCTION" result="PARENT(CHANGED,CLASS)" /> </Measure>
Set an artefact as critical if one of its containing folder is critical:
<Measure measureId="IS_CRITICAL" defaultValue="0"> <Computation targetArtefactTypes="FOLDER;CLASS;FUNCTION" result="ANCESTOR(IS_CRITICAL,FOLDER)" /> </Measure>
Filtering with FPARENT():
IF(FPARENT(RANK(SCALE_LINE,LEVELG), RANK(SCALE_LINE,LEVELG), I.LC),1,2) => resolves as: IF(PARENT(I.LC)=RANK(SCALE_LINE,LEVELG),1,2) => return 1 if PARENT(I.LC) = LEVELG, otherwise 2
Filtering with FANCESTOR():
FANCESTOR(500,, LC, FOLDER) => returns LC for the first folder ancestor where LC >= 500
Find out if the Checkstyle Data Provider was executed successfully with IS_DP_OK:
<Measure measureId="RAN_CHECKSTYLE" defaultValue="0"> <Computation targetArtefactTypes="APPLICATION;FOLDER;FILE;FUNCTION" result="IS_DP_OK(Checkstyle)" /> </Measure>
Do something if the artefact is a CHANGE_REQUEST, with IS_ARTEFACT_TYPE:
<ArtefactType id="ISSUE" heirs="BUG;CHANGE_REQUEST;HOTLINE;REGRESSION" />
<Measure measureId="IS_CR" defaultValue="0">
<Computation targetArtefactTypes="ISSUE"
result="IS_ARTEFACT_TYPE("CHANGE_REQUEST")" />
</Measure>Defining a measure whose value is set to 1 when the artefact is new, else 0:
<Measure measureId="EXAMPLE" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="IS_NEW_ARTEFACT()" /> </Measure>
Using IS_NEW_ARTEFACT as a condition operator:
<Measure measureId="EXAMPLE" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="IF(IS_NEW_ARTEFACT(),3,4)" /> </Measure>
Note: IF(IS_NEW_ARTEFACT(),val_yes,val_no) is equivalent to IF(IS_NEW_ARTEFACT()>0,val_yes,val_no)
Counting the number of new findings in this analysis:
<Measure measureId="COUNT_NEW_FINDINGS" defaultValue="-1"> <Computation targetArtefactTypes="APPLICATION;FILE;FUNCTION" result="COUNT RULE.OCCURRENCES FROM TREE WHERE IS_NEW_FINDING()" /> </Measure>
Find the number of failing tests (link type: BLOCKS) for each requirement and requirement folder
<Measure measureId="NUM_FAILING_TESTS" defaultValue="-1"> <Computation targetArtefactTypes="REQUIREMENT" result="LINKS(BLOCKS,IN)" /> <Computation targetArtefactTypes="REQUIREMENT_FOLDER" result="SUM REQUIREMENT.NUM_FAILING_TESTS FROM TREE" /> </Measure>
Find the number of failing tests for each requirement, excluding failing tests on relaxed code
<Link id="BLOCKS" inArtefactTypes="CODE" outArtefactTypes="REQUIREMENT" /> <Measure measureId="NUM_FAILING_TESTS_COND" defaultValue="-1"> <Computation targetArtefactTypes="REQUIREMENT" result="LINKS(BLOCKS,IN, NOT(IS_RELAXED_ARTEFACT())" /> </Measure>
Temporal functions allow to retrieve and use values computed in the previous baseline. The available operators are:
PREVIOUS_VALUE(measureId) to get the previous value of a measure or indicator (measureId). This function returns 0 when no previous value can be found.
DELTA_VALUE(measureId) to use the computed difference between the current value of a measure or indicator (measureId) and its previous value. This function returns 0 if no delta can be calculated.
PREVIOUS_INFO(infoId) allows retrieving the value of some artefact information (infoId) in the previous version so it can be compared with the current artefact information (This is useful when combined with the EQUALS() or MATCHES() functions, as described in the section called “String Matching Functions”).
FIRST_VALUE(measureId [, <computation> min] [, <computation> max]) returns the first value ever assigned to a metric (measureId) in the current project, optionally within specific bounds (min, max).
AGGREGATE(aggregationType, measureId, [, <computation> minNb] [, <computation> maxNb] [, <computation> min] [, <computation> max])
returns the aggregated value of the previous values of a metric (measureId). You can optionally configure the minimun
and maximum (minNb, maxNb) number of valid data points to be aggregated, and specify bounds (min, max)
for the values to consider for aggregation. The aggregation type (aggregationType) is a mandatory parameter, and must be one
of MIN, MAX, OCC, AVG,
DEV, SUM, MED or MOD.
LEAST_SQUARE_FIT(<computation> degree, measureId, <computation> date, [, <computation> minNb] [, <computation> maxNb] [, <computation> min] [, <computation> max]) returns the interpolated or extrapolated value from the previous values of a metric (measureId) at a specific date (date). You can optionally configure the minimun
and maximum (minNb, maxNb) number of valid data points to be taken into account, and specify bounds (min, max)
for the values to consider for extrapolation. The date (date) and degree (degree) of the polynomial extrapolation are mandatory parameters.
Examples
Using the value of LC from the previous analysis:
<Measure measureId="EXAMPLE" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="PREVIOUS_VALUE(LC)" /> </Measure>
Obtaining the difference in ranking between two analyses for an artefact:
<Measure measureId="EXAMPLE" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="DELTA_VALUE(RANK)" /> </Measure>
Compute a delta of opened/closed bugs since the previous analysis:
<Measure measureId="SPRINT_PROGRESS" defaultValue="-1"> <Computation targetArtefactTypes="SPRINT" result="DELTA_VALUE(NB_OPEN_CR)" /> </Measure>
Compute a delta of opened/closed bugs since the beginning of a sprint:
<Measure measureId="SPRINT_PROGRESS" defaultValue="-1"> <Computation targetArtefactTypes="SPRINT" result="FIRST_VALUE(NB_OPEN_CR)-NB_OPEN_CR" /> </Measure>
Count the number of new issues reported based on the number of new issues opened daily:
<Measure measureId="NEW_ISSUES_TALLY" defaultValue="-1"> <Computation targetArtefactTypes="SPRINT" result="AGGREGATE(SUM, NEW_CR)" /> </Measure>
Compute the average number of issues opened daily:
<Measure measureId="ISSUE_DISCOVERY_RATE" defaultValue="-1"> <Computation targetArtefactTypes="SPRINT" result="AGGREGATE(AVG, NEW_CR)" /> </Measure>
You can use the following operators to work with dates in your model:
DATE(<year_param>, <month_param>, <day_param>) to convert year/month/day numbers to a date
DAYS(<param>) to pass a number as a number of days
TO_DAYS(<date_difference>) to evaluate the number of dates between two dates
TODAY() to retrieve today's date at midnight
NOW() to retrieve today's exact date and time at the time of the analysis
VERSION_DATE() to retrieve the version's date. By default, this is the same value
as the time of the analysis (NOW()), but users are allowed to specify a different date different
from the current one.
TRUNCATE_DATE(<date>, <unit>) returns a date truncated to the specified precision unit and
is useful when calculating date differences (see below for examples). The supported units are:
YEAR
MONTH
SEMI_MONTH
WEEK_SUNDAY (use when the first day of the week is Sunday)
WEEK_MONDAY (use when the first day of the week is Monday)
DAY
AM_PM
HOUR
MINUTE
SECOND
Note: Dates are computed and stored internally as the number of milliseconds since January 1st 1970. However, calculations involving dates are designed to work with a number of days, not hours or minutes.
Examples
Converting to the date 28th July 1979:
<Measure measureId="EXAMPLE" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="DATE(1979,07,28)" /> </Measure>
Converting to a date using measure IDs:
<Measure measureId="EXAMPLE" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="DATE(YEAR_START+2,MONTH_START+MONTHS_SPENT,TARGET_DAY)" /> </Measure>
Find the number of days since the start of the project (the project attribute PROJECT_START_DATE) until today
<Measure measureId="EXAMPLE" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="TO_DAYS(TODAY()-PROJECT_START_DATE)" /> </Measure>
Add 4 days to May 19th 2012 to obtain May 23rd 2012:
<Measure measureId="EXAMPLE" defaultValue="0"> <Computation targetArtefactTypes="FILE;FUNCTION;CLASS" result="DATE(2012,05,19)+DAYS(4)" /> </Measure>
Calculate whether an issue expires within a week of the analysis:
<Measure measureId="EXPIRES_THIS_WEEK" defaultValue="0"> <Computation targetArtefactTypes="BUG;CR" result="IF(EXPIRY_DATE - DAYS(7) < VERSION_DATE(),1,0)" /> </Measure>
Truncate a date down to year precision:
<!-- Sat, 28 Jul 1979 11:14:04 GMT --> <Constant id="EXACT_DATE" value="302008444000" /> <!-- Returns 283996800000 (aka: Mon, 01 Jan 1979 00:00:00 GMT) --> <Measure measureId="TRUNCATE_TO_YEAR" defaultValue="-1"> <Computation targetArtefactTypes="ISSUE" result="TRUNCATE_DATE(EXACT_DATE, YEAR)" /> </Measure>
Find out how much time it took to solve an issue. This example highlights how using TRUNCATE_DAYS() can bring more precision depending on how you want to handle periods under 24 hours as one day or two days.
<!-- Date opened: Sat, 28 Jul 1979 07:47:47 GMT --> <Constant id="TIME_OPENED" value="301996067000" /> <!-- Date closed 1: Sat, 28 Jul 1979 12:02:25 GMT --> <Constant id="TIME_CLOSED_1" value="302011345000" /> <!-- Date closed 2: Sun, 29 Jul 1979 04:56:04 GMT --> <Constant id="TIME_CLOSED_2" value="302072164000" /> <Measure measureId="TRUNCATE_TO_RETURN_ZERO" defaultValue="-1"> <Computation targetArtefactTypes="ISSUE" result="TRUNCATE_DATE(TIME_CLOSED_1, DAY) - TRUNCATE_DATE(TIME_OPENED, DAY)" /> </Measure> <Measure measureId="TRUNCATE_TO_RETURN_ONE" defaultValue="-1"> <Computation targetArtefactTypes="ISSUE" result="TRUNCATE_DATE(TIME_CLOSED_2, DAY) - TRUNCATE_DATE(TIME_OPENED, DAY)" /> </Measure> <Measure measureId="TO_DAYS_RETURNS_ONE" defaultValue="-1"> <Computation targetArtefactTypes="ISSUE" result="DAYS(TIME_CLOSED_1 - TIME_OPENED)" /> </Measure> <Measure measureId="TO_DAYS_RETURNS_ONE_ALSO" defaultValue="-1"> <Computation targetArtefactTypes="ISSUE" result="DAYS(TIME_CLOSED_2 - TIME_OPENED)" /> </Measure>
This section lists the functions you can use when you want to retrieve information related to milestones.
You can use keywords instead of using a milestone ID. You can retrieve information about the next, previous, first or last milestones in the project by using:
NEXT
NEXT+STEP
where STEP is a number indicating how many milestones to jump ahead
PREVIOUS
PREVIOUS-STEP
where STEP is a number indicating how many milestones to jump backward
FIRST
LAST
In all milestone functions, if no milestone ID and no keyword is specified, then NEXT is used by default.
All milestone functions accept a date parameter. The date is used to execute the function in that date context. If no date is specified, then the context used to execute the function is the analysis date.
HAS_MILESTONE([milestoneId or keyword] [, date])
checks if
a milestone with the specified milestoneId exists in the project.
The function returns 0 if no milestone is found, 1 if a milestone is found.
DATE_MILESTONE([milestoneId or keyword] [, date])
returns the date associated to a milestone.
GOAL(measureId [, milestoneId or keyword] [, date])
returns the goal for a metric at a milestone.
Examples
Find if we are at the last milestone of the project:
IS_LAST_MILESTONE=IF(HAS_MILESTONE(),0,1)
Find if the date for the milestone BETA_RELEASE has been modified between June 2015 and now:
DATE_HAS_SLIPPED=(DATE_MILESTONE(BETA_RELEASE)-DATE_MILESTONE(BETA_RELEASE, DATE(2015,06,01))) != 0
Find the goal for requirement stability set for the milestone PROTOTYPE as of June 2016:
REQ_STABILITY_GOAL=GOAL(REQ_STABILITY, PROTOTYPE, DATE(2016,06,01))
Find the delta between the goal for TEST between the previous and next milestones:
DELTA=GOAL(TEST) - GOAL(TEST, PREVIOUS)
Find the delta between the goal for TEST for the next milestone set for the previous analysis and now:
DELTA=GOAL(TEST) - GOAL(TEST, NEXT, VERSION_DATE(PREVIOUS))
Find the delta between the current value of TEST and the goal for TEST at the next milestone:
DELTA=GOAL(TEST) - TEST
Compute the date difference between the previous and next milestones:
MILESTONE_DURATION=DATE_MILESTONE(NEXT) - DATE_MILESTONE(PREVIOUS)
Find the date slip for the next milestone between now and the previous anlaysis:
DATE_SLIP=DATE_MILESTONE(NEXT) - DATE_MILESTONE(NEXT, VERSION_DATE(PREVIOUS))
Find the amount of time left until the next milestone:
DEADLINE=DATE_MILESTONE(NEXT) - VERSION_DATE()
In order to extract the specific information that is added to artefacts by various Data Providers, you can use the
INFO(info_tag) and ARTEFACT_NAME() functions. Both functions return a string containing the
information requested. You can then use these string matching functions in your computations:
EQUALS('string','string'[, forceIgnoreCase])
CONTAINS('string','string'[, forceIgnoreCase])
STARTS_WITH('string','string'[, forceIgnoreCase])
ENDS_WITH('string','string'[, forceIgnoreCase])
MATCHES('string','regexp'[, forceIgnoreCase])
forceIgnoreCase is an optional boolean
set to 1 by default. If you want to perform a case-sensitive search,
use 0, instead.
You can also retrieve the previous value of some artefact information using the PREVIOUS_INFO() function, as described in the section called “Temporal Functions”
Examples
The examples for these functions are based on an artefact with the following data:
<I n="LANGUAGES" v="Java, C#, C++, C"/> <I n="AUTHOR" v="gabriel"/> <I n="URL" v="http://www.my_url.com"/> [^] <I n="ONE_LANGUAGE" v="JaVa"/>
EQUALS()
EQUALS(INFO(AUTHOR), 'gabriel') => 1
EQUALS(INFO(LANGUAGES), 'Java, C#, C++, C', 0) => 1
STARTS_WITH()
STARTS_WITH(INFO(URL), 'HTTP') => 1
STARTS_WITH(INFO(URL), 'HTTPS') => 0
ENDS_WITH()
ENDS_WITH(INFO(URL), '.COM') => 1
ENDS_WITH(INFO(URL), '.COM', 0) => 0 (note the case-sensitive flag)
CONTAINS()
CONTAINS(INFO(LANGUAGES), 'C++') => 1
CONTAINS(INFO(LANGUAGES), 'Cobol') => 0
CONTAINS(INFO(LANGUAGES), INFO(ONE_LANGUAGE), 1) => 1
MATCHES()
MATCHES(INFO(LANGUAGES), 'J.*', 0) => 1
MATCHES(INFO(LANGUAGES), '.*(, C\+\+).*', 0) => 1
MATCHES(INFO(LANGUAGES), '.*(, C\+\+\+).*', 0) => 0
Queries allow to perform calculations on a set of values, optionally applying some conditions.
You can think of a query as an structured statement similar to:
[COMPUTE_VALUE] FROM [SCOPE] WHERE [CONDITION]
In this section, you will learn how to compute values, define a scope and write conditions for your queries.
Queries provide the following operators to compute values:
Returns the sum of values returned for a set.
The SUM of values [1, 3, 3, 3, 5, 6] is 21.
Return the maximum or minimum value of a set.
The MAX and MIN of values [1, 3, 3, 3, 5, 6] are 6 and 1 respectively.
Returns the mean of all the values returned for a set.
The AVR of values [1, 3, 3, 3, 5, 6] is 3.5.
Returns the product of all the values returned for a set.
The MUL of values [1, 3, 3, 3, 5, 6] is 810.
Counts the number of elements returned for a set.
The COUNT of values [1, 3, 3, 3, 5, 6] is 6.
The COUNT operator offers the following variations:
ARTEFACT_TYPE is one of
FOLDER, APPLICATION,
C_FILE, or other types (or aliases) defined in your model. Returns the number of rules. You can specify the ruleset to take into account by specifying a scope:
ALL is the entire ruleset for the model, ignoring whether rules are enabled or not
STANDARD is the model ruleset minus the rules that are deactivated by default
CUSTOMER is the ruleset as configured in the web interface using the Analysis Model Editor
PROJECT (default) is the ruleset as configured by the user when going through the project creation wizard
Returns the number of times a rule is violated (i.e. the number of findings). You can set a scope for the ruleset to take into account (see RULE above) and also limit the occurrences to a certain status:
ALL returns all findings irrespective of their relaxation status
OPENED (default) returns only findings that are not relaxed
RELAXED returns only relaxed findings
The scope of this tree-like hierarchy is defined as follows, relative to the current artefact, or node:
NODE and DESCENDANTNODE and CHILDREN.Defining a condition in your query means filtering out of the scope the results that do not meet
the condition. Several conditions can be added with the AND and OR operators,
and OR takes priority over AND. A condition consists of an operand,
a comparator, and a value. Note that parentheses are not allowed in the body of a condition. An example is shown below:
<Computation targetArtefactTypes="CODE" result="COUNT RULE FROM TREE WHERE HAS_OCCURRENCE() AND FAMILY=MATURITY" />
All operands described in the section called “Operands” are allowed. Operators allowed for
conditions are: =,!=, <,
>, <=
and >=. Note that XML does not allow using <
directly in an attribute, therefore you will need to insert it using an entity:
<.
If you are using queries to retrieve metrics from artefacts or to count artefacts, your conditions can use regular computation syntax and function. Refer to the section called “Operands”, the section called “Simple Calculation Syntax”and the section called “Functions” for more details.
If you are using queries to retrieve metrics for the number of rules or violations, use the syntax from this section.
HAS_OCCURRENCE([<findingStatus>], [<onlyRelaxedInSourceCode>]) allows finding if there are any violations of the specified rules in the specified scope. You can refine the results by specifying the status of the violations you are looking for:
OPEN (default) to find all violations except the ones that were relaxed
ALL to find all violations irrespective of their relaxation status
RELAXED to find all relaxed violations
RELAXED_DEROGATION to find violations with the Derogation relaxation status
RELAXED_LEGACY to find violations with the Legacy Code relaxation status
RELAXED_FALSE_POSITIVE to find violations with the False Positive relaxation status
Additionally, you can specify whether to find violations that were relaxed in the source code directly (as opposed to the web interface) by passing TRUE or in the source code or via the web interface by passing FALSE (default) as the second parameter.
Examples:
Find out if there are MISRA violations:
COUNT RULE FROM DESCENDANTS WHERE HAS_OCCURRENCE() AND FAMILY=MISRA
or:
COUNT RULE FROM DESCENDANTS WHERE HAS_OCCURRENCE(OPEN) AND FAMILY=MISRA
Find out if there is legacy code with relaxed critical violations:
COUNT RULE FROM DESCENDANTS WHERE HAS_OCCURRENCE(RELAXED_LEGACY)
Find out if the code was modified to relax violations:
COUNT RULE FROM DESCENDANTS WHERE HAS_OCCURRENCE(RELAXED, TRUE)
NBOCCURRENCES (=, <, >, <=, >=,!=) allows working with the number of occurrences of violations:
COUNT RULE FROM DESCENDANTS WHERE NBOCCURRENCES<10 COUNT RULE FROM DESCENDANTS WHERE NBOCCURRENCES>10 COUNT RULE FROM DESCENDANTS WHERE NBOCCURRENCES=1 COUNT RULE FROM DESCENDANTS WHERE NBOCCURRENCES!=1 COUNT RULE FROM DESCENDANTS WHERE NBOCCURRENCES<=1.0 COUNT RULE FROM DESCENDANTS WHERE NBOCCURRENCES>=1
NBOCCURRENCES is deprecated and should be replaced with HAS_OCCURRENCE() whenever possible.
CATEGORY (=, !=) allows working with scale levels (see the section called “Scales” for more information on scales):
COUNT RULE FROM DESCENDANTS WHERE CATEGORY=SCALE_PRIORITY.REQUIRED COUNT RULE.OCCURRENCES FROM DESCENDANTS WHERE CATEGORY!=SCALE_PRIORITY.REQUIRED
FAMILY (=, !=) allows working with the families set in your model for rules (see the section called “Rules” for more information on rules):
COUNT RULE FROM DESCENDANTS WHERE FAMILY=REQUIRED COUNT RULE FROM DESCENDANTS WHERE FAMILY!=REQUIRED
MEASUREID (=, !=) allows working with the ID of a measure you defined in your analysis model (see the section called “Measures” for more information on measures):
COUNT RULE FROM DESCENDANTS WHERE MEASUREID!=R_NOGOTO
IS_STATUS_FINDING(<findingStatus>, [<onlyRelaxedInSourceCode>]) allows specifying the status of the findings that should be taken into account in your query. The following statuses are supported:
OPEN (default) to find all violations except the ones that were relaxed
ALL to find all violations irrespective of their relaxation status
RELAXED to find all relaxed violations
RELAXED_DEROGATION to find violations with the Derogation relaxation status
RELAXED_LEGACY to find violations with the Legacy Code relaxation status
RELAXED_FALSE_POSITIVE to find violations with the False Positive relaxation status
Additionally, you can specify whether to find violations that were relaxed in the source code directly (as opposed to the web interface) by passing TRUE or in the source code or via the web interface by passing FALSE (default) as the second parameter.
You can combine conditions in a single query:
COUNT FILE FROM DESCENDANTS WHERE LEVEL!=LEVELC OR FAMILY=HIS AND B.LC>10
Since OR takes priority over AND,
this will be interpreted as:
(LEVEL!=LEVELC OR FAMILY=HIS) AND B.LC>10
The following examples are explained in details to help you understand how computations work.
Find the number of rules in the "required" family that were violated in the selected artefact and all its descendants:
COUNT RULE FROM TREE WHERE HAS_OCCURRENCE() AND FAMILY=REQUIRED
Find the number of violations of the R_COMPOUNDELSE rule in the children of the selected artefact:
COUNT RULE.OCCURRENCES FROM DESCENDANTS WHERE MEASUREID=R_COMPOUNDELSE
Find the number of relaxed violations of the R_COMPOUNDELSE rule in the children of the selected artefact:
COUNT RULE.OCCURRENCES(RELAXED) FROM DESCENDANTS WHERE MEASUREID=R_COMPOUNDELSE
Find the number of legacy-code-relaxed violations of the R_COMPOUNDELSE rule in the children of the selected artefact:
COUNT RULE.OCCURRENCES(RELAXED) FROM DESCENDANTS WHERE MEASUREID=R_COMPOUNDELSE AND IS_STATUS_FINDING(RELAXED_LEGACY)
Find the number of programs with a rating of LEVELG, starting from the children of the considered artefact:
COUNT PROGRAM FROM DESCENDANTS WHERE LEVEL=LEVELG
Find the number of rules in the MISRA family in the model:
COUNT RULE WHERE FAMILY=MISRA
Find the number of rules in the MISRA family in the model, ignoring all changes made in the Analysis Model Editor:
COUNT RULE(STANDARD) WHERE FAMILY=MISRA
Find the number of rules in the REQUIRED family that were violated in the selected artefact and all its descendants:
COUNT RULE FROM TREE WHERE HAS_OCCURRENCE() AND FAMILY=REQUIRED
Find the number of issues with the status "FIXED" created in the last 60 days:
COUNT ISSUE FROM TREE WHERE EQUALS(INFO('STATUS'), 'FIXED') AND DATE_SUBMITTED >= TODAY() - DAYS(60)Table of Contents
All dashboards available in Squore can be easily configured. Dashboards are specific to a model, and depend on the role of the user in the current project.
Each
model defined in the Squore
Configuration defines its own set of dashboards in the model's bundle
file,
located in
Squore_HOME/Configuration/models/MyModel/Dashboards/Bundle.xml
. The bundle uses a lot of XML inclusion for
convenience, but some elements can be easily
recognised:
<?xml version="1.0" encoding="UTF-8"?>
<roles xmlns:xi="http://www.w3.org/2001/XInclude">
<role name="DEFAULT">
<dashboard type="MODEL" nbColumns="2" factor="3">
<charts>
<xi:include href="rule_compliance_vs_complexity__size_quadrant.xml" />
<xi:include href="CodeCloning/size_vs_code_cloning_quadrant.xml" />
</charts>
<xi:include href="SQuORE_RiskIndex/project_summary_table.xml" />
</dashboard>
<dashboard type="APPLICATION" nbColumns="3" minSizeForLegend="2x1" template="1:3x1;2:2x2;3:1x2">
<scorecard>
<xi:include href="../../Shared/Analysis/key_performance_indicator.xml" />
<tables>
<xi:include href="MaintenancePerformance/maintenance_performance_table.xml" />
<xi:include href="ArtefactRating/artefact_table_oo.xml" />
<xi:include href="TechnicalDebt/exploded_technical_debt_table.xml" />
</tables>
</scorecard>
<charts>
<xi:include href="ControlFlowAnalysis/CyclomaticComplexity/complexity_trend.xml" />
<xi:include href="StabilityIndex/StabilityCChart.xml" />
<xi:include href="ArtefactRating/StatementStackedBar.xml" />
<xi:include href="LineCounting/LineCountHisto.xml" />
</charts>
</dashboard>
</role>
</roles>
There are two types of dashboards:
The Analysis Model Dashboard: a view that is activated when clicking the name of a model or a sub group in the Project Portfolios. This dashboard contains one or more charts and a table that displays information about all the projects in the Explorer for this model. This is described in the section called “Analysis Model Dashboards”.
The Artefact Dashboard: a view that is displayed when clicking an artefact in the Artefact Tree. This dashboard contains two sections: a score card and a charts area. This dashboard is described in the section called “Artefact Type Dashboards”.
This specific dashboard displays information relative to all projects analysed with the current analysis model or group of project. It consists of a list of charts and a table with all the projects using this analysis model in this group and some chosen values (columns) to ease comparison between them.
Analysis Model Dashboard
Its structure is as follows:
<dashboard type="MODEL" nbColumns="2" scoreGroups="true" indicatorId="PERFORMANCE" aggregationType="AVG" defaultWidthValue="500" defaultHeightValue="500"> <charts> ... </charts> <table id="PROJECT_SUMMARY" hideLastVersion="false" hideCreator="true" hideGroup="true" hideLevel="false"> ... </table> </dashboard>
The dashboard
element supports the following attributes:
type
(mandatory)
is the type of artefact that this dashboard definition applies to.
nbColumns
(optional, default: 3)
sets the number of columns used to display the charts on the dashboard.
defaultWidthValue
(optional, default: 400)
sets the default width of a maximised chart if not specified within the chart itself.
defaultHeightValue
(optional, default: 400)
sets the default height of a maximised chart if not specified within the chart itself.
factor
(optional, default: 1.5)
is the zoom factor for thumbnails on the dashboard. Factor 1 is equivalent to a thumbnail size of 100 pixels.
template
(optional, default: 1x1 for all charts)
allows changing the aspect ratio of charts in the dashboard, using the syntax "position:width x height;".
Note that the use of this attribute requires defining a value for the nbColumns
attribute.
For more details about dashboard templates, refer to the section called “Dashboard Templates”.
minSizeForLegend
(optional, default: no legends on thumbnails)
allows displaying chart legends on the thumbnails for charts whose ratio is above the specified minimum. By default,
no chart legends are displayed on thumbnails. If you want to force the legend to be displayed on thumbnails, specify for what chart
ratio the thumbnail will be generated. Charts have a ratio of 1x1 by default, so specify minSizeForLegend="1x1" to force legends for all charts. If you want to display legends for all charts that have a width that is twice their height,
specify minSizeForLegend="2x1".
If a chart has an attribute legend="false", then its legend will not be included on the thumbnail even if its ratio matches the one specified in minSizeForLegend.
In order to tell Squore to rate groups of project, you can use the following attributes for
the dashboard
element:
scoreGroups
(optional, default: false) turns the rating display on or off for groups of projects. When rating groups is disabled, you can use a group icon instead by defining it in a properties file (G.<group_name>.ICON=path/to/icon.ico).
indicatorId
(optional, default: LEVEL) is the indicator to use to rate the project group when
scoreGroups
is set to true.
aggregationType
(optional, default: AVG) is the aggregation method used to compute the indicator level
when scoreGroups
is set to true. The supported values allowed are:
MIN
MAX
OCC
AVG
DEV
SUM
MED
MOD
The charts area allows displaying a series charts. Only the following charts are supported at this level: Quadrant, Kiviat, Temporal Evolution Chart, Dial, Meter, Treemap, SQALE Pyramid.
The table area shows information about the projects analysed with the current model. Projects that do not belong to the portfolio are not shown.
The first column allows to check or uncheck the projects whose information
should be used to compute data on the charts. The information can be aggregated in the charts
in several ways using the aggregationType
attribute of a
measure
or indicator
element. At model-level,
aggregating has the effect of showing one line per project for each metric defined in the chart.
You can find out more about this attribute in the section called “Common Attributes for measure and indicator
”.
Other columns, showing specific information about the project, are defined as follows:
<table id="PROJECT_SUMMARY" hideLastVersion="false" hideCreator="true" hideGroup="true" hideLevel="false"> <column indicatorId="BUSINESS_VALUE" headerDisplayType="NAME" displayType="VALUE" "decimals="0" suffix=""/> <column indicatorId="QUALITY" headerDisplayType="NAME" displayType="VALUE" decimals="2" suffix="%"/> <column indicatorId="TECH_DEBT" headerDisplayType="NAME" displayType="VALUE" decimals="0" suffix=""/> <column indicatorId="TECH_DEBT_IDX" headerDisplayType="NAME" displayType="VALUE" decimals="2" suffix="/FUNC"/> <column indicatorId="SUMSLOC" headerDisplayType="NAME" displayType="VALUE" decimals="0" suffix=""/> </table>
The
column
sub-element has the following attributes:
indicatorId
is the unique identifier of the measure, indicator or textual information to be displayed.
headerDisplayType
(at model-level)
or
displayType
(at artefact-level)
(optional, default: MNEMONIC)
defines how the indicator is shown in the interface. The supported values are:
NAME
MNEMONIC
DESCRIPTION
displayOnlyIf
(optional) allows specifying a computation to evaluate whether or not to show the chart in the dashboard. If
the result of the computation is more than 0, then the chart is displayed. Consult Chapter 5, Computation Syntax for
more information about the supported computation syntax. Note that computations used in
displayOnlyIf
have a limited scope: they only apply to the current node in its current version.
This means that the functions like PREVIOUS_VALUE(), PREVIOUS_INFO(), DELTA_VALUE(), APP(), ANCESTOR(), PARENT() or
IS_DP_OK() cannot be used with displayOnlyIf
.
displayedValue
(optional)
allows overriding the indicator to display another measure instead.
The attribute takes a measure Id (displayedValue="SLOC").
displayType
(at model-level) or
displayValueType
(at artefact-level)
(optional, default: VALUE)
defines how the indicator's value is shown in the interface. It
may be one of:
NAME the level's name
MNEMONIC the level's mnemonic
RANK the level's rank
VALUE the measure's value
ICON the level's icon
DATE the measure value converted to date format
DATETIME the measure value converted to datetime format
TIME the measure value converted to time format
TEXT when the metric you are trying to display is textual information, as described in the section called “Using Textual Information From Artefacts”
PERCENT to automatically convert a value between 0 and 1 into a percentage (also appending '%' as a suffix)
For DATE,DATETIME and TIME, you can specify the required format using the dateStyle, timeStyle and datePattern attributes described below.
unknownValue
(optional, default: "?")
defines what text
to display if the level of the indicator is UNKNOWN or outside the specified dataBounds
. Set this to OFF
to use the old behaviour (which display the rank -1).
emptyValue
(optional, default: "-")
defines what text
to display if there is no value in the database for the specified metric, or if a date is not specified.
This is usually useful if a date has not been set yet manually in a form (and is therefore equal to 0), or if you have just added a
new metric to your model you want to display specific text for the versions of your project where this metric did
not exist yet.
dataBounds
(optional, default:[;[)
allows overriding the normal range of values that would trigger the display of the
unknownValue
text. This allows you to display the unknown value if the metric
associated with the indicator is not within the defined bounds.
dateStyle
(optional, default: DEFAULT): the date formatting style,
used when the displayType is one of DATE or DATETIME.
timeStyle
(optional, default: DEFAULT): the time formatting style,
used when the displayType is one of DATETIME or TIME. See above for available styles.
datePattern (formerly dateFormat)
(optional, default: empty): the date pattern, used when
the displayType is one of DATE,
DATETIME or TIME.
If this attribute is set, both dateStyle and timeStyle attributes are ignored. The date is formatted using the supplied pattern. Any format compatible with the Java Simple Date Format can be used. Refer to http://docs.oracle.com/javase/6/docs/api/java/text/SimpleDateFormat.html for more information.
decimals
(optional, default: 0) is the number of decimals places to be used for displaying values
decimals
(optional, default: 0) is the number of decimals places to be used for displaying values
roundingMode
(optional, default: HALF_EVEN)
defines the behaviour used for rounding the numerical values displayed. The supported values are:
CEILING to round towards positive infinity.
DOWN to round towards zero.
FLOOR to round towards negative infinity.
HALF_DOWN to round towards "nearest neighbour" unless both neighbours are equidistant, in which case round down.
HALF_EVEN to round towards the "nearest neighbour" unless both neighbours are equidistant, in which case, round towards the even neighbour.
HALF_UP to round towards "nearest neighbour" unless both neighbours are equidistant, in which case round up.
UP to round away from zero.
For more examples of rounding mode, consult http://docs.oracle.com/javase/6/docs/api/java/math/RoundingMode.html.
Dashboards for artefacts consist of two areas: the scorecard area and the charts area. When clicking the name of an analysis model instead of an artefact, then a special dashboard is used: the Analysis Model Dashboard.
The Squore Artefact Dashboard Areas
The type of the artefact targeted is specified in the definition of the dashboard. The number of columns used in the graphics area and the default width and height of graphics can optionally be set.
<dashboard type="APPLICATION" nbColumns="3" defaultWidthValue="500" defaultHeightValue="500" > <scorecard> ... </scorecard> <charts> ... </charts> </dashboard>
The dashboard
element supports the following sub-elements:
The dashboard
element supports the following attributes:
type
(mandatory)
is the type of artefact that this dashboard definition applies to.
nbColumns
(optional, default: 3)
sets the number of columns used to display the charts on the dashboard.
defaultWidthValue
(optional, default: 400)
sets the default width of a maximised chart if not specified within the chart itself.
defaultHeightValue
(optional, default: 400)
sets the default height of a maximised chart if not specified within the chart itself.
factor
(optional, default: 1.5)
is the zoom factor for thumbnails on the dashboard. Factor 1 is equivalent to a thumbnail size of 100 pixels.
template
(optional, default: 1x1 for all charts)
allows changing the aspect ratio of charts in the dashboard, using the syntax "position:width x height;".
Note that the use of this attribute requires defining a value for the nbColumns
attribute.
For more details about dashboard templates, refer to the section called “Dashboard Templates”.
minSizeForLegend
(optional, default: no legends on thumbnails)
allows displaying chart legends on the thumbnails for charts whose ratio is above the specified minimum. By default,
no chart legends are displayed on thumbnails. If you want to force the legend to be displayed on thumbnails, specify for what chart
ratio the thumbnail will be generated. Charts have a ratio of 1x1 by default, so specify minSizeForLegend="1x1" to force legends for all charts. If you want to display legends for all charts that have a width that is twice their height,
specify minSizeForLegend="2x1".
If a chart has an attribute legend="false", then its legend will not be included on the thumbnail even if its ratio matches the one specified in minSizeForLegend.
The scorecard shows a picture representing a chart (usually the artefact KPI) and a set of tables with further information. Each table has its own set of lines with various information. The structure used to define the scorecard is shown below:
<scorecard> <chart ... /> <tables> <table id="DECISION_MAKING" opened="true"> <line indicatorId="BUSINESS_VALUE" displayType="NAME" decimals="0" suffix="FP" /> ... </table> ... </tables> </scorecard>
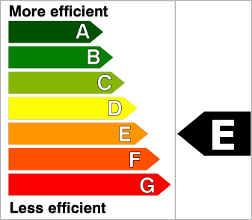
Key Performance Indicator
For more information about how to insert a KPI into the scorecard, refer to Key Performance Indicator.
There may be any number of tables below the KPI chart, and there may be any number of lines in each table.
A scorecard information table using 3 tables with respectively 10, 7, and 4 lines.
A scorecard table is defined using the following syntax:
<tables displayContext="false" hideLinks="ALL"> <table name="My Table Name" id="TABLE_ID" opened="true"> <line indicatorId="BUSINESS_VALUE" displayType="NAME" decimals="0" suffix="FP" emptyValue="-" exclude="TESTER" /> <line indicatorId="QUALITY" displayType="NAME" decimals="1" suffix="%" /> <line indicatorId="SI" displayType="NAME" decimals="1" suffix="%" /> </table> <table id="TABLE_ID"> ... </table> ... </tables>
The tables
element accepts the following attributes:
displayContext
(optional, default: false) allows to
automatically insert an Artefact context table containing
the current artefact's project, version and name, as shown below:

The artefact context table
The table name is not configurable.
hideLinks
allows managing the display of the
links tables in the scorecard. All links tables are shown by default. You can hide a table by setting the
value of the attribute to <LinkType>#<direction>,
where LinkType is the type of link between artefacts,
and direction is a choice of OUT or
IN, for example:
hideLinks="TEST_SPEC#OUT;TASK#IN".
If you want to hide all links tables in the scorecard, use hideLinks="ALL".
The name of the table can be configured using properties files, as
explained in the section called “Descriptions”. If you need more control over where links tables
are displayed in the scorecard, you can manually insert a links table using the linksTable
element, described later in this section.
The table
element accepts the following attributes:
id
(mandatory) is used to find the localised
version of the table name in a .properties file.
name
(optional, default: empty) allows
bypassing the search for a localised string
backgroundColor
(optional, default: WHITE for charts, GREY for tables) allows specifying a background colour for a chart or a table. [colour syntax]
opened
(optional, default: false) defines
whether a table is opened or collapsed by default
displayType
(optional, default: no default) defines the
displayType
to be used by all lines in this table. It can be overridden for
each line if necessary. For full details, consult the displayType reference for the line element.
displayOnlyIf
(optional) allows specifying a computation to evaluate whether or not to show the chart in the dashboard. If
the result of the computation is more than 0, then the chart is displayed. Consult Chapter 5, Computation Syntax for
more information about the supported computation syntax. Note that computations used in
displayOnlyIf
have a limited scope: they only apply to the current node in its current version.
This means that the functions like PREVIOUS_VALUE(), PREVIOUS_INFO(), DELTA_VALUE(), APP(), ANCESTOR(), PARENT() or
IS_DP_OK() cannot be used with displayOnlyIf
.
The line
element accepts the following attributes:
indicatorId
is the unique identifier of the measure, indicator or textual information to be displayed.
headerDisplayType
(at model-level)
or
displayType
(at artefact-level)
(optional, default: MNEMONIC)
defines how the indicator is shown in the interface. The supported values are:
NAME
MNEMONIC
DESCRIPTION
displayOnlyIf
(optional) allows specifying a computation to evaluate whether or not to show the chart in the dashboard. If
the result of the computation is more than 0, then the chart is displayed. Consult Chapter 5, Computation Syntax for
more information about the supported computation syntax. Note that computations used in
displayOnlyIf
have a limited scope: they only apply to the current node in its current version.
This means that the functions like PREVIOUS_VALUE(), PREVIOUS_INFO(), DELTA_VALUE(), APP(), ANCESTOR(), PARENT() or
IS_DP_OK() cannot be used with displayOnlyIf
.
displayedValue
(optional)
allows overriding the indicator to display another measure instead.
The attribute takes a measure Id (displayedValue="SLOC").
displayType
(at model-level) or
displayValueType
(at artefact-level)
(optional, default: VALUE)
defines how the indicator's value is shown in the interface. It
may be one of:
NAME the level's name
MNEMONIC the level's mnemonic
RANK the level's rank
VALUE the measure's value
ICON the level's icon
DATE the measure value converted to date format
DATETIME the measure value converted to datetime format
TIME the measure value converted to time format
TEXT when the metric you are trying to display is textual information, as described in the section called “Using Textual Information From Artefacts”
PERCENT to automatically convert a value between 0 and 1 into a percentage (also appending '%' as a suffix)
For DATE,DATETIME and TIME, you can specify the required format using the dateStyle, timeStyle and datePattern attributes described below.
unknownValue
(optional, default: "?")
defines what text
to display if the level of the indicator is UNKNOWN or outside the specified dataBounds
. Set this to OFF
to use the old behaviour (which display the rank -1).
emptyValue
(optional, default: "-")
defines what text
to display if there is no value in the database for the specified metric, or if a date is not specified.
This is usually useful if a date has not been set yet manually in a form (and is therefore equal to 0), or if you have just added a
new metric to your model you want to display specific text for the versions of your project where this metric did
not exist yet.
dataBounds
(optional, default:[;[)
allows overriding the normal range of values that would trigger the display of the
unknownValue
text. This allows you to display the unknown value if the metric
associated with the indicator is not within the defined bounds.
dateStyle
(optional, default: DEFAULT): the date formatting style,
used when the displayType is one of DATE or DATETIME.
timeStyle
(optional, default: DEFAULT): the time formatting style,
used when the displayType is one of DATETIME or TIME. See above for available styles.
datePattern (formerly dateFormat)
(optional, default: empty): the date pattern, used when
the displayType is one of DATE,
DATETIME or TIME.
If this attribute is set, both dateStyle and timeStyle attributes are ignored. The date is formatted using the supplied pattern. Any format compatible with the Java Simple Date Format can be used. Refer to http://docs.oracle.com/javase/6/docs/api/java/text/SimpleDateFormat.html for more information.
decimals
(optional, default: 0) is the number of decimals places to be used for displaying values
decimals
(optional, default: 0) is the number of decimals places to be used for displaying values
roundingMode
(optional, default: HALF_EVEN)
defines the behaviour used for rounding the numerical values displayed. The supported values are:
CEILING to round towards positive infinity.
DOWN to round towards zero.
FLOOR to round towards negative infinity.
HALF_DOWN to round towards "nearest neighbour" unless both neighbours are equidistant, in which case round down.
HALF_EVEN to round towards the "nearest neighbour" unless both neighbours are equidistant, in which case, round towards the even neighbour.
HALF_UP to round towards "nearest neighbour" unless both neighbours are equidistant, in which case round up.
UP to round away from zero.
For more examples of rounding mode, consult http://docs.oracle.com/javase/6/docs/api/java/math/RoundingMode.html.
The external links in the lines of the score card tables are generated automatically according to the metric that
the line displays. They will generally link to the list of findings that are used to compute
the metric. You can however override the URL and set your own external URL. In order to do this, ensure that the metric
MY_METRIC displayed in a table line has a
MY_METRIC.URL
property defined in a properties file in your model. For more information about properties files, consult the section called “Descriptions”.
The linksTable
element is used instead of table
to insert a links table,
and accepts the following attributes:
id
(mandatory) is used to find the localised
version of the table name in a .properties file.
type
(mandatory) is the id of the type of
links the table displays.
direction
(optional, default: OUT) defines the direction of
the links to display. Set it to OUT to show outbound links or
IN to display inbound links.
For more information about artefact links, consult the section called “Artefact Links”.
You can use dashboard templates to highlight some of the charts on your dashboard by changing their size in terms of grid slots they occupy. The following is an example template that uses 4 columns of charts with custom aspect ratios applied to the first three charts:
<?xml version="1.0" encoding="UTF-8"?>
<roles xmlns:xi="http://www.w3.org/2001/XInclude">
<role name="DEFAULT">
<dashboard nbColumns="4" type="APPLICATION" template="1:4x2;2:2x2;3:2x2">
(...)
<charts>
<xi:include href="chart1.xml" />
<xi:include href="chart2.xml" />
<xi:include href="chart3.xml" />
<xi:include href="chart4.xml" />
<xi:include href="chart5.xml" />
<xi:include href="chart6.xml" />
<xi:include href="chart7.xml" />
</charts>
</dashboard>
</role>
</roles>Note that you only need to specify custom dimensions for non-standard charts sizes using the syntax "position:width x height;", other charts will use a 1x1 grid slot by default.
Charts are displayed on the right hand side of the dashboard. They
are defined through
chart
elements as follows:
<charts> <chart id="CHART_ID" type="CHART_TYPE"> <indicator>INDICATOR_1</indicator> <indicator>INDICATOR_2</indicator> <indicator>INDICATOR_3</indicator> </chart> <chart id="CHART_ID"> ... </chart> ... </charts>
There are many types of charts, all referenced in this section. The best approach to finding the chart you want to use on your dashboard can be found by answering the following questions:
Should my chart display a trend or reflect the data for a single version of my project?
Is the information I want to display abut the current artefact or about its descendants?
Will my chart display one bit of information or combine several?
Is the information displayed by my chart quantitative or qualitative?
Answering these questions will lead you toward the type of chart you want to use. The table below shows the type of answer offered by each of the charts available in Squore:
Table 6.1. Charts for Single-Version Data Visualisation
| Current Artefact Data | Descendants of the Current Artefact | ||||||
| Quantitative Information | Qualitative Information | Quantitative Information | Qualitative Information | ||||
|
Single Dataset | Multiple Datasets |
Single Dataset | Multiple Datasets |
Single Dataset | Multiple Datasets |
Single Dataset | Multiple Datasets |
| N/A | |||||||
Table 6.2. Charts for Trend-Based Visualisation
| Current Artefact Data | Descendants of the Current Artefact | ||||||
| Quantitative Information | Qualitative Information | Quantitative Information | Qualitative Information | ||||
|
Single Dataset | Multiple Datasets |
Single Dataset | Multiple Datasets |
Single Dataset | Multiple Datasets |
Single Dataset | Multiple Datasets |
| N/A | N/A | N/A | N/A | N/A | |||
More information about charts and their configuration options can be found in Chapter 7, Charts Reference
Table of Contents
chart
measure and indicator
In this chapter, you can find all the configuration options available for the charts supported in Squore. The following sections will cover in details the different types of charts offered by Squore.
Although attributes may be different depending on the type of chart, some are common to all charts:
type
(mandatory) defines the type of chart, as listed
below.
id
(mandatory) is an unique identifier for the chart that can be used to add a localisable description in properties files.
name
(optional) is the display name of the chart on the dashboard. Note that the value of this attribute is used as a
fallback in case no translation is found for the chart's ID.
You should use C.CHART_ID.NAME=My Chart Name
in a properties file to define a chart's name for CHART_ID instead of using this attribute.
orientation
(optional, default: VERTICAL) allows defining the orientation of the chart. The allowed values are VERTICAL and HORIZONTAL.
backgroundColor
(optional, default: WHITE for charts, GREY for tables) allows specifying a background colour for a chart or a table. [colour syntax]
plotBackgroundColor
(optional, default: same value as backgroundColor
) sets the background of the plotting area of the chart to the specified colour. [colour syntax]
xMin, xMax
(optional, defaults to automatic values) allow defining the desired boundaries for the x-axis. This attribute
can be specified as a value or as a computation.
yMin, yMax
(optional, defaults to automatic values) allow defining the desired boundaries for the y-axis. This attribute
can be specified as a value or as a computation.
displayOnlyIf
(optional) allows specifying a computation to evaluate whether or not to show the chart in the dashboard. If
the result of the computation is more than 0, then the chart is displayed. Consult Chapter 5, Computation Syntax for
more information about the supported computation syntax. Note that computations used in
displayOnlyIf
have a limited scope: they only apply to the current node in its current version.
This means that the functions like PREVIOUS_VALUE(), PREVIOUS_INFO(), DELTA_VALUE(), APP(), ANCESTOR(), PARENT() or
IS_DP_OK() cannot be used with displayOnlyIf
.
exclude
(optional) allows specifying a list of roles that will not see the chart.
xLabel
(optional) overrides the default name given to the x axis for charts that use axes.
yLabel
(optional) overrides the default name given to the x axis for charts that use axes.
aggregate
(optional, only valid at model-level, default: false) specifies that the metrics shown on the chart are aggregated. The
aggregation type is defined for each measure with the aggregationType
,
as described in the section called “Common Attributes for measure and indicator
”.
legend
(optional, default: false for quadrants, true for other types of charts) allows specifying if the chart's legend is shown (true) or hidden (false).
Most charts use the measure
and indicator
elements to define
the metrics used in the chart. The attributes allowed for these element are:
label
(optional, default: the measure's name) defines or overrides the label used for the measure. Note that the chart thumbnail will always show the mnemonic no matter what the value of label
is.
color
(optional, default: the project's color, or a random color based on the artefact's name) defines the colour used to represent the measure in the chart. [colour syntax]
dataBounds
(optional, default: "];[") defines the range of values allowed to be displayed on the chart. You can use this attribute to exclude drawing an erroneous or non-representative value on a chart. This attribute is currently supported for the following charts: All Temporal Evolution charts, Quadrant, X/Y-Cloud, Histogram, Y-Cloud, Dial, Meter, Simple Pie and Optimised Pie.
[ and ] allow you to specify that a boundary value is included.
] and [ specify that the boundary value itself is excluded.
shape
(optional, default: CIRCLE) defines the shape used to represent a point on a chart. The allowed values are:
NONE
SQUARE
CIRCLE
DIAMOND
UP_TRIANGLE
DOWN_TRIANGLE
RIGHT_TRIANGLE
LEFT_TRIANGLE
HORIZONTAL_RECTANGLE
VERTICAL_RECTANGLE
HORIZONTAL_ELLIPSE
VERTICAL_ELLIPSE
stroke
(optional, default: SOLID) defines the type of line used join points. The allowed values are NONE, SOLID and DOTTED.
aggregationType
(optional, default: AVG in most charts, SUM in table charts) defines how the values for the
metrics on the chart are aggregated. The supported values are:
MIN
MAX
OCC
AVG
DEV
SUM
MED
MOD
weightMeasure
(optional, default: none) allows specifying how to weigh artefacts against each other in some charts (Simple Bar, Simple Pie and Simple Temporal Evolution Stacked Bar Chart). This is useful when you want to represent a percentage of artefacts in a chart but want the ratios to be based on a metric instead using the number of artefacts. Consider the example below where a chart shows child file artefacts and their rating the standard way (left), or weighted by lines of code per artefact (right, with weightMeasure="LC"):
Child file artefacts and their rating the standard way (left), or weighted by lines of code per artefact (right)
Attributes that are specific to certain charts only are documented in each chart's section.
All the chart attributes that allow specifying a colour (for a background, a series, markers and text) support the following syntax:
Some colours can also be used directly by name:
WHITE
LIGHT_GRAY
GRAY
DARK_GRAY
BLACK
RED
PINK
ORANGE
YELLOW
GREEN
MAGENTA
CYAN
BLUE
Using the colour's RGB value: Green is color="0,128,0" or color="rgb(0,128,0)"
Using the colour's integer value: Green is color="32768"
Using the colour's HTML code: Green is color="#008800"
When you do not explicitely specify a colour for an element, Squore automatically generates a set of consistent random colours used on the dashboard.
Scales levels also have associated colours so that they can be represented in the charts. The colour of each level of performance is defined in a .properties file (see the section called “Descriptions”, and the same syntax as the one explained above is supported.
Datasets are used to apply different rendering settings to different groups of measures in a chart. Each dataset can use its own axis configuration.
Two metrics styled with two different datasets in the same chart.
<chart type="TE" id="TEMPORAL_EVOLUTION_DOUBLE_AXIS_MISSING_VERSIONS_LINE"> <dataset renderer="LINE" rangeAxisId="AXIS_1"> <measure color="40,81,245" alpha="200" label="Source Line of Code">SLOC</measure> </dataset> <dataset renderer="BAR" rangeAxisId="AXIS_2"> <measure color="200,81,0" alpha="200" label="Line of Code">LC</measure> </dataset> <rangeAxis id="AXIS_1" label="SLOC (en KLOC)" color="40,81,245" /> <rangeAxis id="AXIS_2" label="LC" color="200,81,0" /> </chart>
The dataset
accepts the following attributes:
renderer
(optional, default: differs according to the type of chart) allows specifying the type of rendering. The allowed values are:
LINE to draw a line that joins points on the charts
STEP to draw a stepped line between points on the charts
BAR to draw a bar to represent each value
STACKEDBAR to stack bars on top of each other
STACKEDBAR100 to stack bars on top of each other as a ratio between 0 and 1. This works best with a numberFormat="PERCENT" for the left axis, as shown here.
AREA to fill the area below a line
STACKEDAREA to stack areas on top of each other
rangeAxisId
(optional) allows providing a reference to an axis configuration element
Chart axes can be defined using the rangeAxis
element, which accepts the following attributes:
id
(mandatory) The configuration identifier (referred to by a dataset
element)
label
(optional, default: the measure name) The label to be displayed on the axis
min
(optional, defaults to an automatic value) is the minimum boundary for the axis. This attribute can be specified as a value or as a computation.
max
(optional, defaults to an automatic value) is the maximum boundary for the axis. This attribute can be specified as a value or as a computation.
hideTickLabels
(optional, default: false) allows hiding values on vertical axes when set to true
inverted
(optional, default: false) reverses the order of values on the axis when set to true.
location
(optional, default: left for vertical charts, bottom for horizontal charts)
allows defining where around the chart the axis is drawn. Allowed values are: left,
right, bottom and top.
color
(optional, default: automatically assigned) sets the colour used to draw the scale. [colour syntax]
type
(optional, default: number) defines how the scale is represented on the axis.
Use number to display the numerical values or scale to plot the axis with the associated scale levels of an indicator.
scaleId
(mandatory if scale is specified) is the id of the indicator to be used
to plot the axis when using type="scale".
numberFormat
(optional, default: usually number) allows customising the number format
when using type="number". The accepted values are as follows:
NUMBER to display a number (formatted according to the browser's locale)
PERCENT to display a percentage
INTEGER to display a number with no decimals
any other text to specify a display pattern following Java's DecimalFormat, as described on http://docs.oracle.com/javase/6/docs/api/java/text/DecimalFormat.html
Charts display tooltips that can be customised using properties files for some charts.
If you are not familiar with how Squore uses properties files, refer to the section called “Descriptions” for more details.
The available parameters for the tooltips are:
p0: The value on the y-axis of the chart
p1: The value on the x-axis of the chart
p2: The current value, displayed as specified in the chart definiton (as a percentage or not)
p3: The percentage for the current value in the current bar (for bar charts)
p4: The current value, displayed in its alternate display method (i.e.: a percentage if p2 was specified to be displayed as a regular number, or a regular number if p2 was specified to be displayed as a percentage)
The default tooltip definition looks like this for most charts:
C.<CHART_ID>.TOOLTIP=({0}, {1}) = {2} ({4})The charts that support tooltip customisation and their default tooltip values are as follows:
Simple Bar {2} ({4})
Optimised Bar {2} ({4})
Stacked Bar Chart ({0}, {1}) = {2} ({4})
Temporal Optimised Stacked Bar Chart ({0}, {1}) = {2} ({4})
Simple Temporal Evolution Stacked Bar Chart ({0}, {1}) = {2} ({4})
In order to specify extra parameters for a chart, add a parameters
with an attribute describing what each parameter is, for example:
<chart> <parameters p5="MEASURE.SLOC" p6="MEASURE.LC"/> (...) </chart>
You can also override these parameters for each measure on an Optimised Bar chart by redefining each parameter as part of the measure
:
<chart type="OptimizedBar> <measure color="0,81,0" label="A" p5="MEASURE.CLOC">A_FILE</measure> <measure color="3,127,3" label="B" p5="INDICATOR.LEVEL">B_FILE</measure> </chart>
In both cases, your tooltip definition can be for example:
C.<CHART_ID>.TOOLTIP=({0}, {1}) = {2} ({4}) - with my extra param={5}Charts that include axes also allow the use of markers. Markers are coloured regions of the chart area that help put the displayed value into context. For example, you could display a line chart of the evolution of the main indicator for your project and use markers to visually associate the value of the indicator with its level, as shown below:
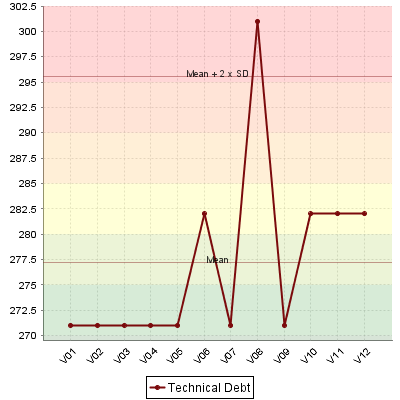
The evolution of an indicator within the levels of its associated scale, using markers to represent the different scale levels
<chart type="TemporalEvolution" renderer="LINE"
id="TEMPORAL_EVOLUTION_LINE_ID">
<measure color="123,10,12" label="Technical Debt">ROOT</measure>
<markers>
<marker fromScale="SCALE_TEST" isVertical="false" />
</markers>
</chart>Simpler markers can be drawn as vertical or horizontal lines, as shown below:
The evolution of an indicator within the levels of its associated scale, using markers to represent the different scale levels
<chart type="TE"
id="TE_LINE_MARKER_LINE"
byTime="true">
<measure color="0,81,0" label="Line of Code" shape="NONE">LC</measure>
<measure color="255,0,0" label="Mixed Line Of Code">MLOC</measure>
<measure color="123,10,12" label="Source Line Of Code" stroke="NONE">SLOC</measure>
<markers>
<marker value="3000" color="80,255,0" isVertical="false"
label="Average from last project"
isInterval="false" labelAnchor="TOP_LEFT" labelTextAnchor="BOTTOM_LEFT"
labelColor="#666666" />
<marker value="DATE(2014,03,15)" color="#ff0000" isVertical="true"
label="March 15th" isInterval="false" labelAnchor="TOP_RIGHT" labelTextAnchor="TOP_LEFT"
labelColor="#ff0000" stroke="DOTTED" labelFontSize="12" labelFontStyle="ITALIC" />
</markers>
</chart>There are five ways to include markers on a chart:
By using a scale ID to apply colouring to the entire background for all available scale levels. See the fromScale
attribute below.
By using an indicator ID to apply colouring to the entire background for all available scale levels associated to the indicator. See the fromIndicator
attribute below.
By specifying a metric to display its goal for each milestone in the project. See the fromMilestonesGoal
attribute below.
By requesting to display a marker for the dates of all milestones in the project. See the fromMilestones
attribute below.
By manually specifying the start and end values on the axes, and the colour of the marker you want. See the value
, endValue
and color
attributes below.
The marker
element has the following attributes:
fromScale
(optional, not compatible with value/endValue
) sets the scale to use to create a markers for each scale level using the
colour defined in the scale's properties.
fromIndicator
(optional) sets the indicator to use to retrieve a scale and create a markers for each scale level using the
colour defined in the scale's properties.
fromMilestonesGoal
(optional) draws markers for all of a metric's goals in the project. You can find an example in the section called “Milestone-Based Markers”.
fromMilestones
(optional) draws markers for all milestone dates in the project. You can find an example in the section called “Milestone-Based Markers”.
value
(optional, default: -infinity, cannot be combined with fromIndicator
, fromScale
,fromMilestonesGoal
, or fromMilestones
) sets the position on the axis to start drawing the marker from. You can specify an exact value, a percentage, or a compuration for this parameter.
endValue
(optional, default: infinity, cannot be combined with fromIndicator
, fromScale
,fromMilestonesGoal
, or fromMilestones
) sets the position on the axis to stop drawing the marker. You can specify an exact value, a percentage, or a compuration for this parameter.
isInterval
(optional, default: true, cannot be combined with fromIndicator
or
fromScale
) allows defining whether a marker covers an interval (true) or is simply a
line on the chart (false). When set to false, endValue
is ignored, and
the following extra parameters are available:
color
(optional, default: GREY, not compatible with fromIndicator
or fromScale
) is the colour code used to fill the marker region. [colour syntax]
alpha
(optional, default: 50) sets the opacity level (0 is transparent, 255 is fully
opaque).
isVertical
(optional, default: false)
specifies if the marker should be vertical (true) or horizontal
(false).
label
(optional, default: none) allows specifying a label for the marker.
labelColor
(optional, default: BLACK) allows specifying the color of the label text. [colour syntax]
labelFontSize
(optional, default: 9) defines the size of the label text.
labelFontStyle
(optional, default: PLAIN) defines the style of the label text. Supported values are:
PLAIN
BOLD
ITALIC
BOLD_ITALIC
labelAnchor
(optional, default: TOP_RIGHT if vertical, TOP_LEFT if horizontal)
defines the position of the label relative to the marker. The possible values are:
BOTTOM
BOTTOM_LEFT
BOTTOM_RIGHT
CENTER
LEFT
RIGHT
TOP
TOP_LEFT
TOP_RIGHT
labelTextAnchor
(optional, default: TOP_LEFT if vertical, BOTTOM_LEFT if horizontal)
defines the position of the text relative to the label. The possible values are:
BASELINE_CENTER
BASELINE_LEFT
BASELINE_RIGHT
BOTTOM_CENTER
BOTTOM_LEFT
BOTTOM_RIGHT
CENTER
CENTER_LEFT
CENTER_RIGHT
HALF_ASCENT_CENTER
HALF_ASCENT_LEFT
HALF_ASCENT_RIGHT
TOP_CENTER
TOP_LEFT
TOP_RIGHT
When working with charts that support displaying a timeline (usually a Temporal Evolution Chart
with an attribute byTime
set to true), the x-axis can be customised to display the level
of details that suits you best. The following attributes can be used:
timeInterval
(optional, default: MILLISECOND) displays only the last value available for the time period selected. This allows you to display a result trend for the past year where only the last of every month is drawn on the chart (onlyLast="12" timeInterval="MONTH"). The values allowed for this attribute are MILLISECOND, SECOND, MINUTE, HOUR, DAY, WEEK, MONTH, QUARTER and YEAR. Note that for Temporal Evolution Chart with a BAR renderer, this setting defines the width of the bar.
timeAxisByPeriod
(optional, default: false) allows labelling the x-axis with periods of time (true) instead of actual dates (false). The minor and major labels displayed are specified by the timePeriodMinorTick
and timePeriodMajorTick
attributes below.
timePeriodMinorTick
(optional, default: auto) defines the interval at which minor ticks are drawn on the chart. The values allowed are the same as for the timeInterval
attribute.
timePeriodMajorTick
(optional, default: auto) defines the interval at which major ticks are drawn on the chart. The values allowed are the same as for the timeInterval
attribute.
By default, the date used for each version is the actual date of when the analysis was run. However, you can override this date and specify the real date of an analysis in the UI using the Version Date field, or via the command line using the versionDate parameter. Refer to the Command Line Interface and the Online Help for more details.
You can display future or past versions on a chart using the forecast
element on a measure, as shown below.
Planned (future) versions on a Temporal Evolution Chart
<chart type="TemporalEvolution"
width="600" height="400"
renderer="BAR" id="TE_BAR_FORECAST">
<measure color="0,81,0" label="Lines of Code">LC
<forecast>
<version value="SLOC" timeValue="DATE(2016,06,30)" label="V7 forecast" />
<version value="600" timeValue="DATE(2016,07,31)" />
<estimatedVersion timeValue="DATE(2016,08,31)" />
<estimatedVersion timeValue="DATE(2016,09,30)" />
</forecast>
</measure>
</chart>The forecast points on the chart can be:
The forecast
element accepts the following attributes:
degree
(optional, default: 1) sets the degree
of the polynomial extrapolation used to compute estimated values at a specific date. Supported values are:
1 for linear
2 for quadratic
3 for cubic
minNb
(optional, default: 2) sets the minimum
number of past values to take into account to estimate future values
maxNb
(optional, default: 5) sets the maximum
number of past values to take into account to estimate future values
When using forecast
with dynamically estimated future values,
use the estimatedVersion
element with the following attributes:
When using forecast
with hard coded values for, use the
version
element with the following attributes:
value
(mandatory) is a computation valid for the current artefact type (same limitation as for displayOnlyIf
).
timeValue
(mandatory) is a computation valid for the current artefact type that is used to position the version on a time axis. The result has to be a number of milliseconds since January 1st 1970.
label
(optional, default: V(n+x)) is the label used to represent the
version on the chart.
Displaying estimates for dynamically for the next 6 months is more efficient with chart where values are plotted according to when they were created on a time axis (see the section called “Time Axis Configuration”) and can be done as shown in the following example:
A rolling 6-month projection chart
<chart type="TE" byTime="true" timeInterval="WEEK" width="600" height="400"
id="TEMPORAL_EVOLUTION_PROJECTION">
<measure label="Lines of Code" color="0,81,0">LC</measure>
<measure stroke="DOTTED" label="Lines of Code (forecast)" color="0,81,0">LC
<forecast>
<estimatedVersion timeValue="CURRENT_VERSION_DATE+DAYS(30)" />
<estimatedVersion timeValue="CURRENT_VERSION_DATE+DAYS(60)" />
<estimatedVersion timeValue="CURRENT_VERSION_DATE+DAYS(90)" />
<estimatedVersion timeValue="CURRENT_VERSION_DATE+DAYS(120)" />
<estimatedVersion timeValue="CURRENT_VERSION_DATE+DAYS(150)" />
<estimatedVersion timeValue="CURRENT_VERSION_DATE+DAYS(180)" />
</forecast>
</measure>
</chart>
CURRENT_VERSION_DATE is a metric defined in the analysis model as follows:
<Measure measureId="CURRENT_VERSION_DATE" defaultValue="-1"> <Computation targetArtefactTypes="FILES;CLASSES;MODULES;CODE_SPECIFICATIONS" result="VERSION_DATE()" /> </Measure>
On a Temporal Evolution Chart, you can render goals graphically by defining a starting point, an end date and a value
you want to reach. This is done using the goal
element on your chart, and replaces the
deprecated Temporal Evolution Line With Goal and Temporal Evolution Bar With Goal charts.
A Temporal Evolution Chart with an area that represents the goal for the metric LC
<chart type="TE" id="TE_LINE_WITH_GOAL_FIRST_VERSION_AREA" byTime="true">
<dataset renderer="AREA">
<goal color="#85B602" alpha="100" label="My Objective">
<forecast>
<firstMeasureVersion id="LC" />
<version value="8000" timeValue="DATE(2014,10,01)" />
</forecast>
</goal>
</dataset>
<dataset renderer="LINE">
<measure color="0,81,0" label="Line of Code">LC
<forecast>
<version value="SLOC" timeValue="DATE(2014,05,01)" label="V3" />
<version value="6666" timeValue="DATE(2014,06,01)" />
<version value="3333+4444" timeValue="DATE(2014,08,01)" />
</forecast>
</measure>
</dataset>
</chart>In the example above, the first dataset (rendered as an AREA
) is used for the goal, while the second
(rendered as a LINE
) is used for the display of the LC metric.
The goal
element supports the color
, label
and alpha
attributes as they are described in the section called “Common Attributes for measure and indicator
”.
It accepts a child forecast
element with one or more traditional version
elements
(as described in the section called “Displaying Planned Versions”), as well as an optional firstMeasureVersion
attribute
that will define the starting point to draw the goal. In the example above, the goal is rendered the first time that the metric LC has
a value and is drawn using the value of this metric at this point in time. The goal to reach is hard-coded to 8000 on October 1st 2014,
but you could use any metrics from you model to generate dynamic values.
Using goals, you can easily draw burn down charts for you agile projects.
A burn down chart of remaining tasks in a sprint
<chart type="TE" id="BURN_DOWN_CHART" byTime="TRUE" timeInterval="DAY">
<dataset renderer="STEP">
<measure color="RED" alpha="200" label="Remaining Tasks">NUM_TASKS</measure>
</dataset>
<dataset renderer="LINE">
<goal color="GREEN" alpha="100" label="Objective">
<forecast>
<firstMeasureVersion id="NUM_TASKS" />
<version value="0" timeValue="SPRINT_START + DAYS(C.SPRINT_LENGTH)" />
</forecast>
</goal>
</dataset>
</chart>In this example, we start drawing the diagonal when NUM_TASKS first has a value for the project, and set the objective to reach zero by dynamically computing the end of the sprint based on the sprint start date and a constant that defines the sprint length.
This section defines how you can integrate information about your project milestones into your charts. When you define milestones in your project (i.e. a series of goals for specific metrics at certain dates in the life of your project), you will be able to:
Display the goals defined for each milestone in your project
Display the changes made to the goals defined for each milestone
Display the date changes for your milestones
Show markers for milestone dates and goals
For more information about adding milestone management to your project, consult the section called “Project Milestones”.
If your project uses milestones, you can use the goal
element to display
all the expected values for a metric for each milestone in the project. In this case, you simply use the name of the metric whose goals
you want to display:
Temporal Evolution Chart displaying the goals for the metric LC for all milestones of the project
<chart type="TemporalEvolution" id="TEMPORAL_EVOLUTION_STACKEDBAR_BAR" timeInterval="WEEK">
<dataset renderer="STACKEDBAR">
<measure color="40,81,245" alpha="200" label="Source Line of Code">SLOC</measure>
<measure color="0,81,0" alpha="200" label="Line of Code">LC</measure>
</dataset>
<dataset renderer="BAR">
<goal color="#ff0000">LC</goal>
</dataset>
</chart>In the example above, compare the blue bars with the red bars to compare actual analyses (V1, V2) against the goals for each milestone in the project (M1, M2, M3, M4, M4b and M5) for the metric LC.
You can also request the goals as they were at a certain date with the versionDate
attribute and assign a weight
to the goal, allowing you to draw other lines based on a goal:
<chart type="TE"
id="TE_LINE_GOALS_ADVANCED" byTime="true">
<dataset renderer="LINE">
<measure color="0,81,0" label="Line of Code">LC</measure>
<goal color="ORANGE" versionDate="DATE(2014,03,01)" label="Old">LC</goal>
<goal color="BLUE" versionDate="DATE(2014,05,01)" label="Current">LC</goal>
<goal color="GREEN" shape="NONE" stroke="DOTTED" alpha="50" weight="1.5" label="Current 150%">LC</goal>
<goal color="GRAY" shape="NONE" stroke="DOTTED" alpha="50" weight="1.1" label="Current 110%">LC</goal>
<goal color="BLUE" shape="NONE" stroke="DOTTED" alpha="50" weight=".9" label="Current 90%">LC</goal>
<goal color="RED" shape="NONE" stroke="DOTTED" alpha="50" weight=".75" label="Current 75%">LC</goal>
</dataset>
</chart>In the chart above, you notice how the last 3 milestones have slipped and understand that the goals have been revised with higher expectations by observing the yellow and blue solid lines. The dotted lines can be used as guides to give you an idea of where 75%, 90%, 110% or 150% of your goal lies on the chart.
You can use the goalHistory
element in a chart if you want to track the changes made to your goals.
This is useful in a post mortem when you review deviations from your original goals.
Temporal Evolution Chart displaying the evolution of goals for each milestone of the project
<chart type="TE" id="TE_MILESTONES_GOAL_HISTORY" byTime="true"> <goalHistory>LC</goalHistory> <measure color="#005100">LC</measure> </chart>
The chart in the example above follows the LC metric and also displays the goals for the metric for each milestone in the project. By the second analysis, you can see that the goals for M4 and M5 have been revised, and that a new milestone called M4b has been introduced.
An optional milestone
attribute allows displaying information about one milestone instead of all milestones, as shown below:
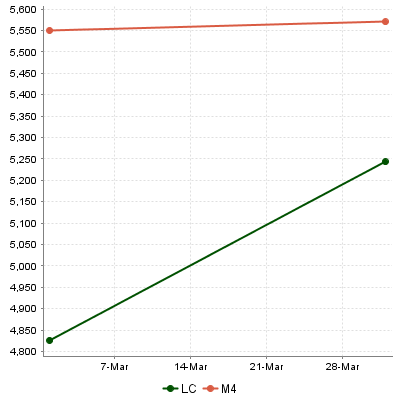
Temporal Evolution Chart displaying the evolution of the goal the M4 milestone
<chart type="TE" id="TE_MILESTONES_GOAL_HISTORY_SINGLE" byTime="true"> <goalHistory milestone="M4">LC</goalHistory> <measure color="#005100">LC</measure> </chart>
You can use keywords instead of using a milestone ID. You can retrieve information about the next, previous, first or last milestones in the project by using:
NEXT
NEXT+STEP
where STEP is a number indicating how many milestones to jump ahead
PREVIOUS
PREVIOUS-STEP
where STEP is a number indicating how many milestones to jump backward
FIRST
LAST
You can use the milestoneHistory
element in a chart if you want to track the date changes made
to your milestones.
Temporal Evolution Chart displaying changes in milestone dates for the project
<chart type="TE" id="TE_MILESTONES_HISTORY" byTime="true">
<dataset renderer="LINE" rangeAxisId="HIDDEN">
<milestoneHistory />
</dataset>
<rangeAxis id="HIDDEN" hideTickLabels="true" />
</chart>The chart in the example above shows the addition of a new M4b milestone and date changes for milestones M4 and M5 in the project, by the time of the second analysis.
An optional milestone
attribute allows displaying information about one milestone instead of all milestones, as shown below:
Temporal Evolution Chart displaying the date slip for the M4 milestone
<chart type="TE" id="TE_MILESTONES_HISTORY_SINGLE" byTime="true"> <milestoneHistory milestone="M4" /> <measure color="#005100">LC</measure> </chart>
You can use keywords instead of using a milestone ID. You can retrieve information about the next, previous, first or last milestones in the project by using:
NEXT
NEXT+STEP
where STEP is a number indicating how many milestones to jump ahead
PREVIOUS
PREVIOUS-STEP
where STEP is a number indicating how many milestones to jump backward
FIRST
LAST
You can use markers based on your milestones in your charts. The type of information you can display is:
Horizontal markers based on the value of the current goal for a specific metric
with
fromMilestonesGoal
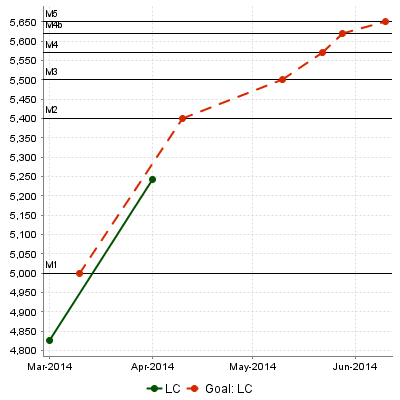
Temporal Evolution Chart displaying markers for the goals for the metric LC for each milestone
<chart type="TE" id="TE_MILESTONES_HORIZONTAL_MARKER" byTime="true">
<goal color="#D62700" stroke="DOTTED">LC</goal>
<measure color="#005100">LC</measure>
<markers>
<marker fromMilestonesGoal="LC" alpha="150" isVertical="false" />
</markers>
</chart>Vertical markers based on the dates of milestones in the project
with
fromMilestones
Temporal Evolution Chart displaying markers for the dates of all milestones in the project
<chart type="TE" id="TE_MILESTONES_VERTICAL_MARKER" byTime="true">
<goal color="#D62700" stroke="DOTTED">LC</goal>
<measure color="#005100">LC</measure>
<markers>
<marker fromMilestones="true" alpha="150" isVertical="true" />
</markers>
</chart>For more information about markers, consult the section called “Using Markers”. Note that in both cases, the marker labels are automatically set to the milestone names.
Some charts (Simple Pie and Simple Bar) support dynamically grouping target artefacts according to textual information
in a measure. In order to use this information, you do not use an indicator
or
measure
element but an info
element with the measure holding the
text information.
Here is a sample definition for a Simple Bar chart where each bar is labelled according to the textual information
held in the ASSIGNEE metric.
A Simple Bar chart using textual information from ISSUE child artefacts to dynamically display its bars.
You can also display textual information in tables, using the following syntax for example:
<table id="CR_INFO"> (...) <line indicatorId="ASSIGNEE" displayType="TEXT" /> (...) </table>
For more information about tables, consult the section called “Scorecard Tables” or the section called “Analysis Model Dashboards”.
The Optimised Pie chart is a pie chart that takes several measure as input. It simply displays a pie chart with the values previously computed.
Optimised Pie Chart
<chart type="OptimizedPie"
id="OPTIMIZED_PIE_ID"
decimals="2">
<measure label="Source">SLOC_ONLY</measure>
<measure label="Comment">CLOC_ONLY</measure>
<measure label="Mixed">MLOC</measure>
<measure color="239,228,176" label="Blank">BLAN</measure>
</chart>The Optimised Pie requires a minimum of two measure
elements and
supports the following attributes:
The Optimised Bar chart is a bar chart that takes several measure as input. It simply displays a bar chart with the values previously computed.
Optimised Bar Chart
<chart type="OptimizedBar"
id="OPTIMIZED_BAR_ID"
asPercentage="true">
<measure color="0,81,0" label="A">A_FILE</measure>
<measure color="3,127,3" label="B">B_FILE</measure>
<measure color="133,182,2" label="C">C_FILE</measure>
<measure color="255,255,0" label="D">D_FILE</measure>
<measure color="255,150,0" label="E">E_FILE</measure>
<measure color="255,80,0" label="F">F_FILE</measure>
<measure color="255,0,0" label="G">G_FILE</measure>
</chart>The Optimised Bar requires a minimum of two measure
elements and
supports the following attributes:
decimals
(optional, default: 0) is the number of decimals places to be used for displaying values
displayEmptyValue
(optional, default: true) specifies whether categories with no value or a value of 0 are included on the chart
asPercentage
(optional, default: false) specifies whether the values are displayed as real values or percentages
This special chart is used to represent the level of the selected artefact in reference to an indicator.
Key Performance Indicator
The following is an example of the syntax used for defining a KPI chart:
<chart type="KPI" id="KEY_PERFORMANCE_INDICATOR" indicatorId="MAINTAINABILITY" />
The following attributes are allowed for
the KPI
chart
tag:
indicatorId
is the reference to an
Indicator. See
the section called “Descriptions”
for more information about the
indicatorId
.
The Dial chart represents the value of the measure associated
to an indicator against a backdrop of the scale associated to this indicator. The Dial chart requires one
indicator
as a sub-element.
Dial Chart
<chart type="Dial" id="DIAL_LINEAR_ID" decimals="0" majorTickIncrement="8" minorTickCount="4"> <indicator>VALUE_LINEAR</indicator> </chart>
The Dial
chart
element may have the following attributes:
The majorTickIncrement
and minorTickCount
parameters only need to
be used if you want to completely control the appearance of the chart. Generally,
they can be omitted, as the defaults should be smart enough to show what you need.
You can control the bounds of the axis of this chart using the datBounds attributs on each metric,
as explained in the section called “Common Attributes for measure and indicator
”.
The indicator
element supports excluding
certain levels from the chart by using the
excludeLevels
attribute. For
example:
<indicator excludeLevels="LEVELA;LEVELB">LEVEL</indicator>
The Meter chart represents the value of the measure associated to an indicator against a backdrop of the scale associated to this indicator.
Meter Chart
<chart type="Meter" id="METER_ID" decimals="0" majorTickIncrement="400"> <indicator>VALUE_LINEAR</indicator> </chart>
The Meter
chart
element may have the following attributes:
The Meter chart takes only one
indicator
as a sub-element.
You can control the bounds of the axis of this chart using the datBounds attributs on each metric,
as explained in the section called “Common Attributes for measure and indicator
”.
The indicator
element supports excluding
certain levels from the chart by using the
excludeLevels
attribute. For
example:
<indicator excludeLevels="LEVELA;LEVELB">LEVEL</indicator>
The Kiviat chart displays three or more indicators in a radar-type chart.
Kiviat Chart
The Kiviat chart takes a set of at least three indicators as sub-elements.
<chart type="Kiviat" id="KIVIAT_ID" isInverted="true"> <indicator label="My testability" objective="LEVELC">TESTABILITY</indicator> <indicator objective="LEVELC">STABILITY</indicator> <indicator objective="LEVELC">CHANGEABILITY</indicator> <indicator objective="LEVELD">ANALYSABILITY</indicator> </chart>
The attributes allowed for the
chart
element are
the following:
The indicator
element accepts a specific, optional objective
attribute
that draws a dotted line at the specified level representing the objective line.
The objective attribute accepts:
A scale level (LEVELA)
An indicator ID (TESTABILITY). In this case, both indicators must use the same scale.
A computation (LC+100). The computed value is then used together with the scale of the indicator to define the level to display.
Note that only a scale level is accepted for Kiviat charts at analysis model level.
This chart represents the SQALE Pyramid, representing a minimum of two different measures or indicators as a matrix.
SQALE Pyramid Chart
<chart type="SQALEPyramid" id="MAINTAINABILITY_PYRAMID" decimals="0"> <measure label="My Testability" >TESTABILITY</measure> <measure>STABILITY</measure> <measure>CHANGEABILITY</measure> <measure>ANALYSABILITY</measure> </chart>
A typical Histogram that shows the repartition of a value for
the children
of the selected artefact It requires one measure
element.
Histogram Chart
<chart type="Histogram" id="HISTOGRAM_ID" targetArtefactTypes="FILE" nbBars="10" > <measure color="242,205,57" >SUMLC</measure> </chart>
The
chart
element may have the following attributes:
targetArtefactTypes
allows to filter descendants according to their type. You can use one or more types.
Concrete and abstract types are supported, so it is possible to use an alias, as described in the section called “Artefact Types”.
There are some limitations to what is supported:
Measures associated to an indicator must have the same measureId for all types and be of the same kind (base or derived)
For Stacked Bar Chart, Simple Temporal Evolution Stacked Bar Chart, Simple Pie and Simple Bar the scale associated to the indicator must be the same for be the same for all types
You can control the bounds of the axis of this chart using the datBounds attributs on each metric,
as explained in the section called “Common Attributes for measure and indicator
”.
The Y-Cloud chart is a visual representation of the values of a measure or indicator for the
children of the selected artefact. For each child of the requested type, a dot is drawn with the
value found for the selected measure. The chart requires one indicator
element.
Y-Cloud Chart
<chart type="YCloud" id="CLOUD_ID" targetArtefactTypes="FILE"> <indicator color="0,0,0" label="LC">LC</indicator> </chart>
The
chart
element may have the following attributes:
targetArtefactTypes
allows to filter descendants according to their type. You can use one or more types.
Concrete and abstract types are supported, so it is possible to use an alias, as described in the section called “Artefact Types”.
There are some limitations to what is supported:
Measures associated to an indicator must have the same measureId for all types and be of the same kind (base or derived)
For Stacked Bar Chart, Simple Temporal Evolution Stacked Bar Chart, Simple Pie and Simple Bar the scale associated to the indicator must be the same for be the same for all types
The Treemap offers a graphical representation of child artefacts as
a set of tiled rectangles.
The Treemap requires one measure
to
define the size of the tiles and accepts a colorFromIndicator
attribute to pick the colors of the tiles. Tiles are generated from largest to smallest,
and from top left to bottom right. Clicking a tile takes you to the dashboard
of the corresponding artefact.
Treemap
<chart id="TREEMAP" type="TreeMap" colorFromIndicator="MAINTAINABILITY" onlyDirectChildren="false" targetArtefactTypes="FOLDER"> <measure>SUMLC</measure> </chart>
This chart also accepts a
filterMeasure
element, which allows refining which
artefacts are included on the chart. When drawing a chart, Squore checks if the metric specified is within the defined bounds for the artefact,
in order to know if it should be included in or excluded from the chart.
You can use the filterMeasure
(with a mandatory
dataBounds
attribute) as follows:
<chart id="SOME_CHART" ...> <measure>METRIC_A</measure> <measure>METRIC_B</measure> <filterMeasure dataBounds="[50;100]">METRIC_C</filterMeasure> </chart>
In the example above, the chart will include the artefact only if METRIC_C is between 50 and 100.
Filtering artefacts on charts is not possible at model-level.
The chart
tag accepts the following attributes:
targetArtefactTypes
allows to filter descendants according to their type. You can use one or more types.
Concrete and abstract types are supported, so it is possible to use an alias, as described in the section called “Artefact Types”.
There are some limitations to what is supported:
Measures associated to an indicator must have the same measureId for all types and be of the same kind (base or derived)
For Stacked Bar Chart, Simple Temporal Evolution Stacked Bar Chart, Simple Pie and Simple Bar the scale associated to the indicator must be the same for be the same for all types
onlyDirectChildren
(optional, default: true) includes artefacts that are direct children of the current artefact
in the chart when set to true, or all descendants of the current artefact when set to false.
colorFromIndicator
(optional) uses an indicator's colour scale to assign a colour to each drawn tile.
defaultColor
(optional, default:RANDOM colour based on artefact name) uses an indicator's colour scale to assign a colour to each drawn tile. [colour syntax]
The Artefact Pie offers a graphical representation of the values of a specific measure
for each child artefact in a pie chart.
The Artefact Pie requires one measure
to
define the size of the pie slice and accepts a colorFromIndicator
attribute to pick the colors of the pie slices based on a scale. Clicking a pie slice
takes you to the dashboard of the corresponding artefact.
Artefact Pie
<chart id="ARTEFACT_PIE_FILE_DESCENDANTS" type="ArtefactPie" colorFromIndicator="MAINTAINABILITY" onlyDirectChildren="false" targetArtefactTypes="FILE"> <measure>SUMLC</measure> </chart>
This chart also accepts a
filterMeasure
element, which allows refining which
artefacts are included on the chart. When drawing a chart, Squore checks if the metric specified is within the defined bounds for the artefact,
in order to know if it should be included in or excluded from the chart.
You can use the filterMeasure
(with a mandatory
dataBounds
attribute) as follows:
<chart id="SOME_CHART" ...> <measure>METRIC_A</measure> <measure>METRIC_B</measure> <filterMeasure dataBounds="[50;100]">METRIC_C</filterMeasure> </chart>
In the example above, the chart will include the artefact only if METRIC_C is between 50 and 100.
Filtering artefacts on charts is not possible at model-level.
The chart
tag accepts the following attributes:
targetArtefactTypes
allows to filter descendants according to their type. You can use one or more types.
Concrete and abstract types are supported, so it is possible to use an alias, as described in the section called “Artefact Types”.
There are some limitations to what is supported:
Measures associated to an indicator must have the same measureId for all types and be of the same kind (base or derived)
For Stacked Bar Chart, Simple Temporal Evolution Stacked Bar Chart, Simple Pie and Simple Bar the scale associated to the indicator must be the same for be the same for all types
onlyDirectChildren
(optional, default: true) includes artefacts that are direct children of the current artefact
in the chart when set to true, or all descendants of the current artefact when set to false.
colorFromIndicator
(optional) uses an indicator's colour scale to assign a colour to each drawn pie slice.
The X/Y-Cloud chart is a visual representation of the values of two measures or indicators for the children of the selected artefact. For each child of the requested type, a dot is drawn with the value found for the selected measure.
X/Y-Cloud Chart
<chart type="XYCloud" id="XYCLOUD_ID" targetArtefactTypes="FILE" colorFromIndicator="COMPLEXITY" xLabel="Cyclomatic Complexity" yLabel="Non Conformity Count" showPolynomialRegression="true" coeff="1" colorFromIndicator="LEVEL" miniShapeWidth="4" shapeWidth="6" shape="CIRCLE"> <xmeasure>TESTABILITY</xmeasure> <ymeasure>STABILITY</ymeasure> </chart>
The
chart
element may have the following attributes:
targetArtefactTypes
allows to filter descendants according to their type. You can use one or more types.
Concrete and abstract types are supported, so it is possible to use an alias, as described in the section called “Artefact Types”.
There are some limitations to what is supported:
Measures associated to an indicator must have the same measureId for all types and be of the same kind (base or derived)
For Stacked Bar Chart, Simple Temporal Evolution Stacked Bar Chart, Simple Pie and Simple Bar the scale associated to the indicator must be the same for be the same for all types
showPolynomialRegression
(optional, default: true)
Whether the polynomial regression is drawn (true) or not drawn (false) on the chart.
coeff
(optional, default: 1)
the degree of the drawn polynomial. Supported values are:
1 for linear
2 for quadratic
3 for cubic
colorFromIndicator
(optional, default: none)
sets the colour of the dot to the colour of the level of the specified indicator.
shape
(optional, default: SQUARE)
defines the shape of the points on the chart. The supported values are:
SQUARE
CIRCLE
DIAMOND
UP_TRIANGLE
DOWN_TRIANGLE
RIGHT_TRIANGLE
LEFT_TRIANGLE
HORIZONTAL_RECTANGLE
VERTICAL_RECTANGLE
HORIZONTAL_ELLIPSE
VERTICAL_ELLIPSE
shapeWidth
(optional, default: 4.0)
defines the width of the point on the maximised chart.
miniShapeWidth
(optional, default: 2.0)
defines the width of the point on the chart thumbnail.
The chart takes one xmeasure
element
and one ymeasure
with the following attributes.
The Quadrant chart displays information about the descendants of the current artefact. Three measures are required to construct the chart: one for the X-axis, one for the Y-axis one for the size of the bubbles. The chart also allows to set markers to define coloured areas.
Quadrant Chart
<chart type="quadrant"
id="NON_CONFORMITY_DENSITY_VS_COMPLEXITY"
targetArtefactTypes="FILE"
xMin="0" xMax="50000"
yMin="0" yMax="100"
onlyDirectChildren="false" >
<xmeasure color="#FF56CA">SUMVG</xmeasure>
<ymeasure>NCD</ymeasure>
<zmeasure>FUNC</zmeasure>
<markers>
<marker value="100" color="255,50,0"
alpha="50" isVertical="false" />
<marker value="100" color="255,50,0"
alpha="50" isVertical="true" />
</markers>
</chart>
This chart also accepts a
filterMeasure
element, which allows refining which
artefacts are included on the chart. When drawing a chart, Squore checks if the metric specified is within the defined bounds for the artefact,
in order to know if it should be included in or excluded from the chart.
You can use the filterMeasure
(with a mandatory
dataBounds
attribute) as follows:
<chart id="SOME_CHART" ...> <measure>METRIC_A</measure> <measure>METRIC_B</measure> <filterMeasure dataBounds="[50;100]">METRIC_C</filterMeasure> </chart>
In the example above, the chart will include the artefact only if METRIC_C is between 50 and 100.
Filtering artefacts on charts is not possible at model-level.
The
chart
element may have the following attributes:
targetArtefactTypes
allows to filter descendants according to their type. You can use one or more types.
Concrete and abstract types are supported, so it is possible to use an alias, as described in the section called “Artefact Types”.
There are some limitations to what is supported:
Measures associated to an indicator must have the same measureId for all types and be of the same kind (base or derived)
For Stacked Bar Chart, Simple Temporal Evolution Stacked Bar Chart, Simple Pie and Simple Bar the scale associated to the indicator must be the same for be the same for all types
onlyDirectChildren
(optional, default: true) includes artefacts that are direct children of the current artefact
in the chart when set to true, or all descendants of the current artefact when set to false.
colorFromIndicator
(optional)
sets the colour of the bubble to the colour of the level of the specified indicator.
The Simple Pie chart presents the aggregation of the different ratings found in all the children of the selected artefact.
Simple Pie Chart
<chart type="SimplePie" id="SIMPLE_PIE_ID" targetArtefactTypes="FILE" decimals="2"> <indicator>LEVEL</indicator> </chart>
The Simple Pie
chart
element may have the following attributes:
targetArtefactTypes
allows to filter descendants according to their type. You can use one or more types.
Concrete and abstract types are supported, so it is possible to use an alias, as described in the section called “Artefact Types”.
There are some limitations to what is supported:
Measures associated to an indicator must have the same measureId for all types and be of the same kind (base or derived)
For Stacked Bar Chart, Simple Temporal Evolution Stacked Bar Chart, Simple Pie and Simple Bar the scale associated to the indicator must be the same for be the same for all types
displayEmptyValue
(optional, default: true) specifies whether categories with no value or a value of 0 are included on the chart
decimals
(optional, default: 0) is the number of decimals places to be used for displaying values
The Simple Pie chart takes only one
indicator
or info
as a sub-element.
For more details about how to use textual information, refer to the section called “Using Textual Information From Artefacts”
The indicator
element supports excluding
certain levels from the chart by using the
excludeLevels
attribute. For
example:
<indicator excludeLevels="LEVELA;LEVELB">LEVEL</indicator>
Note: This chart is equivalent to using an Optimised Pie Chart with the definition shown below. The pie chart is optimised because the measures it uses have already been computed during the analysis and do not need to be calculated on the fly.
<chart type="OptimizedPie" decimals="2" > <measure color="0,81,0" label="A">A_FILE</measure> <measure color="3,127,3" label="B">B_FILE</measure> <measure color="133,182,2" label="C">C_FILE</measure> <measure color="255,255,0" label="D">D_FILE</measure> <measure color="255,150,0" label="E">E_FILE</measure> <measure color="255,80,0" label="F">F_FILE</measure> <measure color="255,0,0" label="G">G_FILE</measure> </chart>
The Simple Bar chart presents the aggregation of the different ratings found in all the children of the selected artefact as a histogram.
Simple Bar Chart
<chart type="SimpleBar" id="SIMPLE_BAR_ID" targetArtefactTypes="FILE" decimals="2"> <indicator>LEVEL</indicator> </chart>
The Simple Bar
chart
element may have the following attributes:
targetArtefactTypes
allows to filter descendants according to their type. You can use one or more types.
Concrete and abstract types are supported, so it is possible to use an alias, as described in the section called “Artefact Types”.
There are some limitations to what is supported:
Measures associated to an indicator must have the same measureId for all types and be of the same kind (base or derived)
For Stacked Bar Chart, Simple Temporal Evolution Stacked Bar Chart, Simple Pie and Simple Bar the scale associated to the indicator must be the same for be the same for all types
decimals
(optional, default: 0) is the number of decimals places to be used for displaying values
displayEmptyValue
(optional, default: true) specifies whether categories with no value or a value of 0 are included on the chart
asPercentage
(optional, default: false) specifies whether the values are displayed as real values or percentages
The Simple Bar chart takes only one
indicator
or info
as a sub-element.
For more details about how to use textual information, refer to the section called “Using Textual Information From Artefacts”
The indicator
element supports hiding or excluding
certain levels from the chart by using the hideLevels
excludeLevels
attribute. The difference between
hiding and excluding a level is that hidden levels are taken into account when displaying percentages while
excluded levels are not. For example:
<indicator excludeLevels="UNKNOWN">LEVEL</indicator>
or
<indicator hideLevels="LEVELA;LEVELB">LEVEL</indicator>
The Stacked Bar crosses the performance levels of two indicators for the children of the selected artefact along two axes.
Stacked Bar chart
<chart type="StackedBar" id="STACKED_BAR_ID" targetArtefactTypes="FILE" > <indicator>TESTABILITY</indicator> <indicator>ANALISABILITY</indicator> </chart>
The
chart
element may have the following attributes:
targetArtefactTypes
allows to filter descendants according to their type. You can use one or more types.
Concrete and abstract types are supported, so it is possible to use an alias, as described in the section called “Artefact Types”.
There are some limitations to what is supported:
Measures associated to an indicator must have the same measureId for all types and be of the same kind (base or derived)
For Stacked Bar Chart, Simple Temporal Evolution Stacked Bar Chart, Simple Pie and Simple Bar the scale associated to the indicator must be the same for be the same for all types
asPercentage
(default: false) displays the values as percentages when set to true.
The chart support two indicator
elements.
The indicator
element supports hiding or excluding
certain levels from the chart by using the hideLevels
excludeLevels
attribute. The difference between
hiding and excluding a level is that hidden levels are taken into account when displaying percentages while
excluded levels are not. For example:
<indicator excludeLevels="UNKNOWN">LEVEL</indicator>
or
<indicator hideLevels="LEVELA;LEVELB">LEVEL</indicator>
The Artefact Series chart displays one or more metrics from descendent artefacts. The measure representation
is defined by a renderer
attribute (as explained in the section called “Datasets” ). The chart also allows clicking on an artefact to display its dashboard.
Artefact Series showing test statistics for child requirements
<chart type="ArtefactSeries" id="TEST_CODE_STATUS" targetArtefactTypes="FILE;REQUIREMENT" onlyDirectChildren="false" inverted="true" orderByMeasure="NUM_FAILING_TESTS" renderer="BAR" orientation="HORIZONTAL"> <measure color="#98AFC7" alpha="200">NUM_TESTS_CODE</measure> <measure color="#54C571" alpha="200">NUM_PASSING_TESTS</measure> <measure color="#DC381F" alpha="200">NUM_FAILING_TESTS</measure> </chart>
The Artefact Series can also be used to draw a stacked bar chart for child artefacts and include a line via the use of several datasets, as shown below:
An alternate representation of the same data in an Artefact Series chart
<chart type="ArtefactSeries" id="TEST_CODE_STATUS" targetArtefactTypes="FILE;REQUIREMENT" onlyDirectChildren="false" inverted="true" orderByMeasure="NUM_FAILING_TESTS" orientation="VERTICAL"> <dataset renderer="STACKEDBAR"> <measure color="#DC381F" alpha="200">NUM_FAILING_TESTS</measure> <measure color="#54C571" alpha="200">NUM_PASSING_TESTS</measure> </dataset> <dataset renderer="LINE" rangeAxis="TOTAL"> <measure color="#98AFC7" alpha="200">NUM_TESTS_CODE</measure> </dataset> <rangeAxis id="TOTAL" color="#98AFC7" hideTickLabels="false" min="0" location="left" type="number" numberFormat="INTEGER" /> </chart>
This chart also accepts a
filterMeasure
element, which allows refining which
artefacts are included on the chart. When drawing a chart, Squore checks if the metric specified is within the defined bounds for the artefact,
in order to know if it should be included in or excluded from the chart.
You can use the filterMeasure
(with a mandatory
dataBounds
attribute) as follows:
<chart id="SOME_CHART" ...> <measure>METRIC_A</measure> <measure>METRIC_B</measure> <filterMeasure dataBounds="[50;100]">METRIC_C</filterMeasure> </chart>
In the example above, the chart will include the artefact only if METRIC_C is between 50 and 100.
Filtering artefacts on charts is not possible at model-level.
The chart
element suports the following attributes:
targetArtefactTypes
allows to filter descendants according to their type. You can use one or more types.
Concrete and abstract types are supported, so it is possible to use an alias, as described in the section called “Artefact Types”.
There are some limitations to what is supported:
Measures associated to an indicator must have the same measureId for all types and be of the same kind (base or derived)
For Stacked Bar Chart, Simple Temporal Evolution Stacked Bar Chart, Simple Pie and Simple Bar the scale associated to the indicator must be the same for be the same for all types
onlyDirectChildren
(optional, default: true) includes artefacts that are direct children of the current artefact
in the chart when set to true, or all descendants of the current artefact when set to false.
renderer (optional, default: BAR)
allows setting a common renderer for all measures in te chart. This can be omitted and overridden for individual datasets, as explained in the section called “Datasets”.
orderByMeasure (optional, default: the first measure in the chart definition)
allows ordering the artefacts on the chart according to the specified measure.
inverted (optional, default: false)
allows reversing the default order of artefacts
You can specify as many measure
sub-elements as necessary for each artefact, using the syntax detailed in the section called “Common Attributes for measure and indicator
”.
The Temporal Evolution Chart shows the evolution of one or measures over time. The measure representation is defined
by a renderer
attribute (as explained in the section called “Datasets” for more details). It replaces the deprecated Temporal Evolution Bar and Temporal Evolution Line charts, and allows representing more than one data sets on the one chart.
Temporal Evolution Chart using an AREA renderer
<chart type="TemporalEvolution" id="TEMPORAL_EVOLUTION_AREA" width="400" height="400" onlyLast="5" renderer="AREA"> <measure color="40,81,245" label="Source Line of Code">SLOC</measure> <measure color="0,81,0" label="Line of Code">LC</measure> </chart>
The Temporal Evolution Chart can also be used to draw a bar chart or a line chart, as shown below:
Temporal Evolution Chart using a BAR renderer
<chart type="TemporalEvolution" id="TEMPORAL_EVOLUTION_BAR_ID" renderer="BAR"> <measure color="0,81,0" label="Technical Debt">TECH_DEBT</measure> </chart>
Temporal Evolution Chart using a LINE renderer
<chart type="TemporalEvolution" id="TEMPORAL_EVOLUTION_LINE_ID" renderer="LINE" isCChart="true" coeff="2" onlyLast="20"> <measure label="Maintainability">MAINTAINABILITY</measure> <measure color="0,81,0">TESTABILITY</measure> </chart>
The chart above is a normal Temporal Evolution Chart where the x-axis uses a regular gap between all versions and uses the version name as the label.
Below is an example of the difference in representation when using the x-axis as a chronological marker.
Temporal Evolution Chart with versions distributed evenly on the x-axis, using the version name as the label (left),
or distributed on the x-axis according to the date at which the analysis was carried out.
Labels on the x-axis do to not correspond to the version name this time. (right).
<chart type="TemporalEvolution" id="TEMPORAL_EVOLUTION_LINE_ID" renderer="LINE dateFormat="MMM d" byTime="true|false" isCChart="true" coeff="2" onlyLast="20"> <measure color="123,10,12" label="Source Line Of Code">SLOC</measure> </chart>
The
chart
element may have the following attributes:
isCChart (optional, default: false)
transforms the chart in a C-Chart if set to true. This draws three extra lines to the chart at the following values on the y-axis:
mean
mean + (coefficient * standard deviation)
mean - (coefficient * standard deviation)
coeff
(optional, default: 0)
sets the value of the coefficient used to draw the control lines either side of the mean line when
isCChart
is set to true.
onlyLast
(optional, default: no limit)
defines the number of versions to be displayed, starting from the
one that is currently selected.
byTime
(optional, default: false)
defines whether versions are placed on the x-axis according to their analysis date. When activating this mode,
you can use the advanced options for the x-axis defined in the section called “Time Axis Configuration”.
breakOnMissingData
(optional, default: false)
specifies whether the line is interrupted (true) when a value is missing.
timeMeasure
(optional) is the measure ID (of type DATE) to use as the analysis date for a chart where byTime
is true. If not specified, the real analysis date of the version is used.
displayDate
(optional, default: false)
for all charts that display information about several versions. When set to false,
the version name is displayed in the chart. When set to true, the version date is displayed instead.
dateFormat
(optional, default: yyMM) allows formatting the version date when displayDate is set to
true according to the Java Simple Date Format described at
http://docs.oracle.com/javase/6/docs/api/java/text/SimpleDateFormat.html.
dateStyle
(optional, default: DEFAULT): the date formatting style,
used when the displayType is one of DATE or DATETIME.
timeStyle
(optional, default: DEFAULT): the time formatting style,
used when the displayType is one of DATETIME or TIME. See above for available styles.
This chart represents the evolution of several measures across several versions. It takes a a minimum of two measures as elements. The labels on the bars can be displayed as values or a percentage, as shown below:
Temporal Optimised Stacked Bar Chart
Temporal Optimised Stacked Bar Chart using percentages
<chart type="OptimizedTemporalEvolutionStackedBar" id="OptimizedTemporalEvolutionStackedBar_BAR_ID" targetArtefactTypes="FILE" asPercentage="false"> <measure color="0,81,0" label="A">A_FILE</measure> <measure color="3,127,3" label="B">B_FILE</measure> <measure color="133,182,2" label="C">C_FILE</measure> <measure color="255,255,0" label="D">D_FILE</measure> <measure color="255,150,0" label="E">E_FILE</measure> <measure color="255,80,0" label="F">F_FILE</measure> <measure color="255,0,0" label="G">G_FILE</measure> </chart>
The
chart
element may have the following attributes:
targetArtefactTypes
allows to filter descendants according to their type. You can use one or more types.
Concrete and abstract types are supported, so it is possible to use an alias, as described in the section called “Artefact Types”.
There are some limitations to what is supported:
Measures associated to an indicator must have the same measureId for all types and be of the same kind (base or derived)
For Stacked Bar Chart, Simple Temporal Evolution Stacked Bar Chart, Simple Pie and Simple Bar the scale associated to the indicator must be the same for be the same for all types
asPercentage
(default: false) displays the values as percentages when set to true.
A chart that shows the evolution of one or more measures over time including an objective.
Temporal Evolution Line Chart Including Goal
<chart type="TELIGoal" id="TELIGOAL_ID" versionStart="V2" direction="down"> <target defaultValue="500" version="start" >INIT_TASKS</target> <nbStep defaultValue="5" ></nbStep> <measure color="0,109,126">LEFT_TASKS</measure> </chart>
The
chart
element may have the following attributes:
versionStart
(mandatory)
the first version present in the chart.
displayAllVersions
(optional, default: false)
defines whether values are shown on the chart for versions prior to versionStart
.
direction
(optional default: down)
is the direction of the Goal line (up or down). Up: From 0 to the target.
Down: From the target to 0.
target
(mandatory)
the measure used for draw the goal line with a default value and
an attribute if we get the current value or the value present in
the version specified by the versionStart attribute.
nbStep
(mandatory)
the measure used for draw the future versions with a default
value.
A chart that shows the evolution of one or more measures over time including an objective i.e. the different versions analysed by the Squore engine.
Temporal Evolution Bar Chart Including Goal
<chart type="TEBIGoal" id="NB_OPEN_TASKS_CHART" versionStart="V2" direction="down"> <target defaultValue="400" version="start" >NB_OPEN_TASKS</target> <nbStep defaultValue="30" >DAYS_LEFT</nbStep> <measure>NB_OPEN_TASKS</measure> </chart>
The
chart
element may have the following attributes:
versionStart
(mandatory)
the first version present in the chart.
displayAllVersions
(optional, default: false)
defines whether values are shown on the chart for versions prior to versionStart
.
direction
(optional default: down)
is the direction of the Goal line (up or down). Up: From 0 to the target.
Down: From the target to 0.
target
(mandatory)
the measure used for draw the goal line with a default value and
an attribute if we get the current value or the value present in
the version specified by the versionStart attribute.
nbStep
(mandatory)
the measure used for draw the future versions with a default
value.
This chart represents the evolution of an indicator across the versions. It takes a single indicator as sub element. The values displayed are calculated on the fly. It is therefore sometimes recommended to use an Temporal Optimised Stacked Bar Chart for performance reasons.
Simple Temporal Evolution Stacked Bar
Simple Temporal Evolution Stacked Bar (bars represented as percentages)
<chart type="SimpleTemporalEvolutionStackedBar" id="SimpleTemporalEvolutionStackedBar_BAR_ID" targetArtefactTypes="FILE" asPercentage="false"> <indicator>MAINTAINABILITY</indicator> </chart>
The
chart
element has the following attributes:
targetArtefactTypes
allows to filter descendants according to their type. You can use one or more types.
Concrete and abstract types are supported, so it is possible to use an alias, as described in the section called “Artefact Types”.
There are some limitations to what is supported:
Measures associated to an indicator must have the same measureId for all types and be of the same kind (base or derived)
For Stacked Bar Chart, Simple Temporal Evolution Stacked Bar Chart, Simple Pie and Simple Bar the scale associated to the indicator must be the same for be the same for all types
asPercentage
(optional, default: false)
indicates if the values should be displayed as percentages.
If the
asPercentage
attribute is set to true, the chart will look like this:
The indicator
element supports hiding or excluding
certain levels from the chart by using the hideLevels
excludeLevels
attribute. The difference between
hiding and excluding a level is that hidden levels are taken into account when displaying percentages while
excluded levels are not. For example:
<indicator excludeLevels="UNKNOWN">LEVEL</indicator>
or
<indicator hideLevels="LEVELA;LEVELB">LEVEL</indicator>
The Artefact Table allows displaying a list of child artefacts and one or more of their characteristics in table format, as shown below:
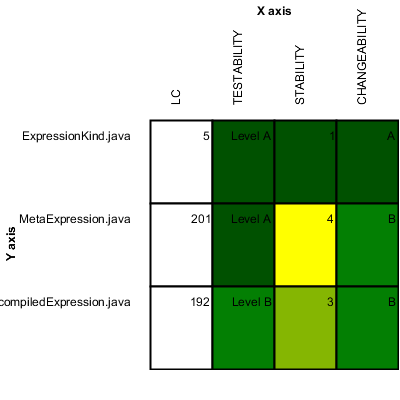
Artefact Table
<chart type="ArtefactTable"
id="ARTEFACT_TABLE_ID"
xLabel="X axis"
yLabel="Y axis"
onlyDirectChildren="true"
orderByMeasure="INDEX"
inverted="false"
targetArtefactTypes="FILE">
<indicator label="LC">LC</indicator>
<indicator displayValueType="NAME" colorFromScale="SCALE_COLOR">TESTABILITY</indicator>
<indicator displayValueType="RANK">STABILITY</indicator>
<indicator displayValueType="MNEMONIC">CHANGEABILITY</indicator>
</chart>In the example above, the indicators use different displayValueType
to show
all the supported values.
The Artefact Table
chart
element may have the following attributes:
targetArtefactTypes
allows to filter descendants according to their type. You can use one or more types.
Concrete and abstract types are supported, so it is possible to use an alias, as described in the section called “Artefact Types”.
onlyDirectChildren
(optional, default: true) includes artefacts that are direct children of the current artefact
in the chart when set to true, or all descendants of the current artefact when set to false.
orderByMeasure
(optional, alphabetical if omitted) allows sorting the list of artefacts according to
the value of the specified measure ID.
inverted
(optional, default: false) allows reversing the
sort order defined by the orderByMeasure
attribute.
The Artefact Table chart takes one or more
indicator
sub-elements, which can point to measures or indicators. Note that
the table cells are automatically coloured according to the corresponding scale level colour when the metric
displayed in the table is an indicator. This behaviour can be overridden by using the
colorFromScale
attribute, which takes a scale ID to apply colour from according to the
rank of the value displayed.
This chart also accepts a
filterMeasure
element, which allows refining which
artefacts are included on the chart. When drawing a chart, Squore checks if the metric specified is within the defined bounds for the artefact,
in order to know if it should be included in or excluded from the chart.
You can use the filterMeasure
(with a mandatory
dataBounds
attribute) as follows:
<chart id="SOME_CHART" ...> <measure>METRIC_A</measure> <measure>METRIC_B</measure> <filterMeasure dataBounds="[50;100]">METRIC_C</filterMeasure> </chart>
In the example above, the chart will include the artefact only if METRIC_C is between 50 and 100.
Filtering artefacts on charts is not possible at model-level.
In addition, you can add a row and column to aggregate the results found in each table row or column using the
row
or column
element. Each of these elements accepts the following
attributes:
aggregationType
(optional, default: AVG in most charts, SUM in table charts) defines how the values for the
metrics on the chart are aggregated. The supported values are:
MIN
MAX
OCC
AVG
DEV
SUM
MED
MOD
label
(mandatory)
is a string that is displayed as the legend of the row or column.
color
(optional, default: GREY)
is the fill colour for the row or column. [colour syntax]
colorFromScale
(optional, default: empty)
allows filling cells with a colour taken from a specific scale.
The Distribution Table is an matrix-like visualisation of two characteristics of an artefact's descendants
Distribution Table
<chart type="DistributionTable" id="DIST_TABLE_FIXED_COLOR" width="600" height="400" targetArtefactTypes="FILE" xLabel="Testability" yLabel="Number of Artefacts" topColor="255,255,153" bottomColor="153,204,255"> <indicator>ROOT</indicator> <indicator>ANALYSABILITY</indicator> <row aggregationType="SUM" label="Total Col" color="100,100,100" /> <column aggregationType="SUM" label="Total Line" color="100,100,100" /> </chart>
The Distribution Table
chart
element may have the following attributes:
targetArtefactTypes
allows to filter descendants according to their type. You can use one or more types.
Concrete and abstract types are supported, so it is possible to use an alias, as described in the section called “Artefact Types”.
color
(optional, default: WHITE)
is the colour used to fill all the cells in the table. An example
Distribution Table using color
is shown later in this section. [colour syntax]
Instead of using a single colour for the entire table, you can use
topColor
, middleColor
and bottomColor
to colour the top, middle and
bottom sections of the chart respectively in different colours, as in the main example above. [colour syntax]
colorFromScale
(optional, default: none)
is the colour scale used to fill the cells in the table according to the rank of each cell. An example
Distribution Table using colorFromScale
is shown later in this section.
If several colour attributes are found, they are applied in this order:
The Distribution Table chart takes two
indicator
sub-element that will be used to build a matrix of scale levels.
In addition, you can add a row and column to aggregate the results found in each table row or column using the
row
or column
element. Each of these elements accepts the following
attributes:
aggregationType
(optional, default: AVG in most charts, SUM in table charts) defines how the values for the
metrics on the chart are aggregated. The supported values are:
MIN
MAX
OCC
AVG
DEV
SUM
MED
MOD
label
(mandatory)
is a string that is displayed as the legend of the row or column.
color
(optional, default: GREY)
is the fill colour for the row or column. [colour syntax]
colorFromScale
(optional, default: empty)
allows filling cells with a colour taken from a specific scale.
Some simpler examples of Distribution Table charts can be found below:
Simple Distribution Table
<chart type="DistributionTable"
id="DIST_TABLE"
name="Distribution Table"
width="400"
height="400"
targetArtefactTypes="FILE"
xLabel="Testability"
yLabel="Number of Artefacts">
<indicator>ROOT</indicator>
<indicator>ANALYSABILITY</indicator>
</chart>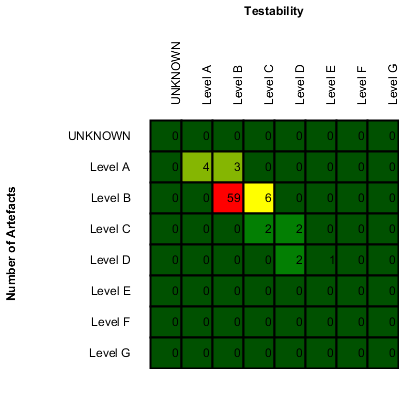
Distribution Table with cells coloured according to a scale
Chart: <chart type="DistributionTable" id="DIST_TABLE_SCALE_COLOR" name="Distribution Table Scale Color" width="400" height="400" targetArtefactTypes="FILE" xLabel="Testability" yLabel="Number of Artefacts" colorFromScale="SCALE_TEST_BASIC"> <indicator>ROOT</indicator> <indicator>ANALYSABILITY</indicator> </chart> Scale: <Scale scaleId="SCALE_TEST_BASIC"> <ScaleLevel levelId="LEVELA" bounds="];1]" rank="1" /> <ScaleLevel levelId="LEVELB" bounds="]1;2]" rank="2" /> <ScaleLevel levelId="LEVELC" bounds="]2;4]" rank="3" /> <ScaleLevel levelId="LEVELD" bounds="]4;8]" rank="4" /> <ScaleLevel levelId="LEVELE" bounds="]8;16]" rank="5" /> <ScaleLevel levelId="LEVELF" bounds="]16;32]" rank="6" /> <ScaleLevel levelId="LEVELG" bounds="]32;[" rank="7" /> </Scale>
Simple Distribution Table with red/green
Chart: <chart type="DistributionTable" id="DIST_TABLE_SCALE_COLOR_RED_GREEN" name="Distribution Table Scale Red/Green" width="400" height="400" targetArtefactTypes="FILE" xLabel="Testability" yLabel="Number of Artefacts" topColorFromScale="SCALE_GREEN" middleColorFromScale="SCALE_RED" bottomColorFromScale="SCALE_RED"> <indicator>ROOT</indicator> <indicator>ANALYSABILITY</indicator> </chart> Scales: <Scale scaleId="SCALE_GREEN"> <ScaleLevel levelId="BLANK" bounds="];1[" rank="-1" /> <ScaleLevel levelId="LEVELA" bounds="[1;[" rank="1" /> </Scale> <Scale scaleId="SCALE_RED"> <ScaleLevel levelId="BLANK" bounds="];1[" rank="-1" /> <ScaleLevel levelId="LEVELG" bounds="[1;[" rank="1" /> </Scale>
The Control Flow Chart is a graphical representation of the logical structure of a function using different-coloured shapes reflecting the type of logical break (if, while, switch...) in the code.
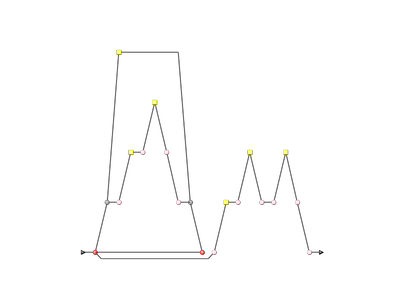
Control Flow Chart
<chart id="CONTROL_ID" type="ControlGraph"</chart>
The chart
for a Control Flow Chart does not accept any elements or attributes apart from the common ones.
The Source Code Viewer is a special chart-like placeholder on a dashboard that allows users to click it to view the source code of the current artefact.

Source Code Viewer
<chart id="SOURCE_CODE_ID" type="SourceCode"</chart>
The chart
for the Source Code Viewer does not accept any elements or attributes apart from the common ones.
The Scrum Board offers a graphical representation of the completion of your tasks for project monitoring. Each task is represented as a sticky note that displays the task ID and provides a link to the issue tracker to review the task.
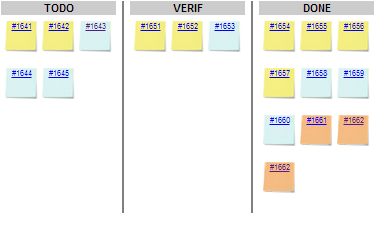
Scrum Board
<chart type="ScrumBoard" postitByColumn="3" header="SCALE_PARKING_LOT" prefixTaskLink="http://support.example.com/view.php?taskId=" > <rule color="255,0,0">EVO_TODO</rule> <rule>BUG_TODO</rule> <rule>BUG_INT_TODO</rule> <rule>EVO_VERIF</rule> <rule>BUG_VERIF</rule> <rule>BUG_INT_VERIF</rule> <rule>EVO_DONE</rule> <rule>BUG_DONE</rule> <rule>BUG_INT_DONE</rule> </chart>
The chart
tag accepts the following attributes:
The Scrum Board requires the following elements:
Table of Contents
Wizards provide the entry point for Squore users to create and edit
projects and meta-projects. A model can have one or more wizards, depending on
the options that a Squore administrator decides to display to end-users when they create projects.
This is achieved by editing the file Bundle.xml
located in the Wizards folder inside a particular model.
Creating or editing a project in Squore involves going through these three steps after selecting a wizard:
Note: When editing projects, the Data Provider Selection screen is shown or hidden depending on the ability of each Data Provider selected originally to accept new settings. When nothing can be changed, the step is skipped completely.
The syntax of a Bundle.xml file
offering one standard wizard and one meta-project wizard to the user is shown below:
<?xml version="1.0" encoding="UTF-8"?> <Bundle> <!-- attributes common to every wizard in this bundle --> <tags> <tag type="numericValue" name="Project Business Value" measureId="BV" suffix = "FP" defaultValue="0" /> </tags> <wizard wizardId="STD_PROJ" versionPattern="V#N1#" autoBaseline="false" users="demo;admin" groups="users" img="wizardicon.png"> <!-- attributes specific to this wizard --> <tags> <tag type="numericValue" name="Project Cost" measureId="COST" suffix = "M/M" defaultValue="0" /> </tags> <repositories all="true" hide="false"> <repository name="FROMPATH" checkedInUi="true"> <param name="path" value="/media/sources/" /> </repository> </repositories> <tools all="true"> <tool name="SQuORE" optional="false"> <param name="languages" value="cpp:.c,.C,.h,.H;java:.java;csharp:.cs;" availableChoices="cpp;java;csharp" /> </tool> <tool name="Antic_auto" optional="true" checkedInUI="true" projectStatusOnFailure="warning" /> </tools> </wizard> <wizard wizardId="STD_META_PROJECTS" projectsSelection="true" /> </Bundle>
In order for a wizard to appear in Squore, you need to define its ID, default version pattern and icon, and it will become available when clicking on the New Project... button. Note that the availability of a wizard can also be restricted to a set of users or groups. The rest of this chapter covers the settings available for each step of the project creation wizard.
The wizard
element accepts the following attributes:
wizardId
(mandatory) defines the ID of the wizard, used when creating projects from the command line
projectsSelection
(optional, default: false) defines whether a wizard shows a list of projects so that users can create a meta-project (true) or shows the list of Repository Connectors and Data Providers to create a regular project (false). For more information about meta-projects, see the section called “Project Selection in Meta-Projects”.
versionPattern
(optional) is the pattern to apply to define the version number when a new version is created
img
(mandatory) is the icon used in the web interface to display next to the wizards's name and description
autoBaseline
(optional, default: true) defines whether versions created using this wizard are by default baselines (true) or drafts (false). More information about baselines and drafts can be found in the Getting Started Guide.
users
(optional, no restriction if empty) is a semi-colon-separated list of users which are allowed to see the wizard
groups
(optional, no restriction if empty) is a semi-colon-separated list of Squore groups whose users are allowed to see the wizard
group
(optional, default: empty) defines a default display group for new projects. projects
that belong to the same group are shown in a common subfolder in the Project Portfolio.
hideRulesEdition
(optional, default: true) defines whether the Rules Edition step of the wizard is shown (false) or hidden (true) to users. This step allows users to modify the ruleset of the model to deactivate rules or change their default categories. More information about this feature can be found in the Getting Started Guide.
The users
and groups
attributes are only used to filter the list of
wizards in the web interface. This does not prevent users from creating projects using the wizard from the command line.
The versionPattern parameter allows specifying a pattern to create the version name automatically for every analysis. It supports the following syntax:
#N#: A number that is automatically incremented
#Nn#: A number that is automatically incremented using n digits
#Y2#: The current year in 2-digit format
#Y4#: The current year in 4-digit format
#M#: The current month in two digit format
#D#: The current day in two digit format
#H#: The current hour in 24 hour format
#MN#: The current minute in two digit format
#S#: The current second in two digit format
Any character other than # is allowed in the pattern. As an example, if you want to
produce versions labelled build-198.2013-07-28_13h07m (where 198 is an auto-incremented number and the date and time are the
timestamp of the project creation), you would use the pattern: build-#N3#.#Y4#-#M#-#D#_#H#h#MN#m
Users specify attributes in the first step project
creation or edition at project level. These attributes can also be used for
other artefact types and can be edited after building a project in the Forms tab of the Explorer.
You can define what information can enter when creating a project (or the default values offered to the users) by using the Tags section
of the wizard definition file. The attribute values specified by the user are passed just like measures passed by any other Data Provider.
The values are imported as base measures as long as the model contains a definition that uses the same measure ID.
<tags textAlign="RIGHT" valueAlign="LEFT">
<tag type="numericValue" name="Project Business Value"
group="Important Decision Criteria"
measureId="BV" suffix = "FP"
defaultValue="0" />
<tag type="booleanChoice" name="is Critical"
group="Important Decision Criteria" measureId="CRIT"
defaultValue="false" />
<tag type="multipleChoice" name="Status: " measureId="STATUS"
defaultValue="SNAPSHOT" displayType="radioButton">
<value key="SNAPSHOT" value="1" />
<value key="VALIDATION" value="2" />
<value key="RELEASE" value="3" />
</tag>
<tag type="multipleChoice" name="Department: "
measureId="DEPART" defaultValue="HR" displayType="comboBox">
<value key="ACCOUNT" value="1" />
<value key="HR" value="2" />
<value key="SALES" value="3" />
<value key="OTHER" value="4"/>
</tag>
<tag type="date" name="Sprint Start: " measureId="SPRINT_START"
defaultValue="TODAY" />
<tag type="date" name="Sprint End: " measureId="SPRINT_END"
defaultValue="2012/12/31" />
</tags>The image below shows how attributes defined in the wizard appear to a Squore user when creating a version of a project:
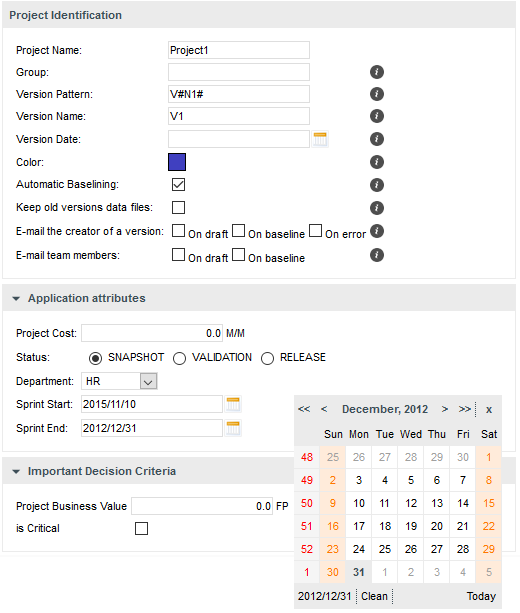
This other image shows how attributes defined in the wizard appear to a Squore user when in the Forms tab of the explorer:
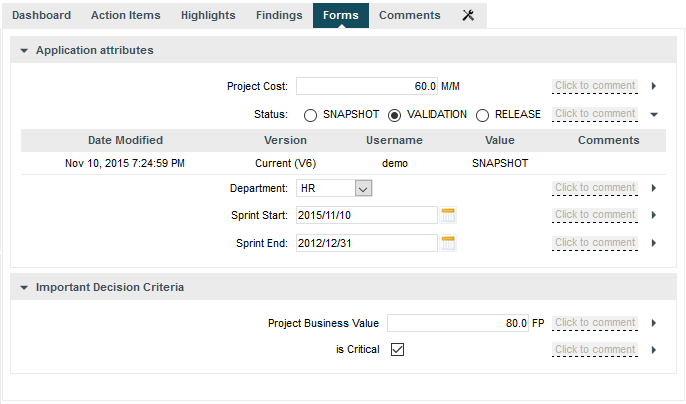
The tags
element is used to group several tag
sub-elements
and accepts the following attributes:
The tag
element accepts the following attributes:
type
(mandatory) defines the type of information accepted as value for this attribute.
The following values are accepted:
text for free text entry
numericValue for numbers
date for dates
booleanChoice for a boolean
multipleChoice for offering a selection as a list
displayType
(optional) allows specifying the display type in the Forms tab and
the project creation wizard. The following values are accepted:
comboBox for attributes of type multipleChoice
radioButton for attributes of type multipleChoice
input for attributes of type text
textarea for attributes of type text
name
(optional) is the label used to describe the attribute in the UI.measureId
(mandatory) is the ID of the measure that the value is passed to.suffix
(optional) is the label displayed after the value in the UI.defaultValue
(optional) is the default value of the attribute if not specified by
the user. In the case of a date, the value TODAY() can
be used to automatically use today's date as the default value.group
(optional) helps grouping various attributes by category visually in the Forms tab of the Explorer.targetArtefactTypes
(optional, default: APPLICATION) allows associating the attribute to other types of artefacts (more on this below).Note: A tag element can appear within a wizard element or at Bundle level.
In case two tag elements impacting the same measureId exist at both levels, the definition within the
wizard element overrides the one at Bundle-level.
All attributes described above are defined at application level. They are visible and editable when creating a project and in the Form tab of the Explorer if the project is in draft mode. It is possible to associate an attribute to any artefact type by using the targetArtefactTypes attribute, as shown below:
<tag group="Project Status" targetArtefactTypes="APPLICATION;SOURCE_CODE;DOCUMENTATION;FOLDER" type="booleanChoice" name="is tested?" measureId="TESTED" defaultValue="false" />
You may specify whether users can use any available Repository Connectors, which is the default one and
what the default values are for each Repository Connector using the repositories
element in your wizard definition . If you
want to allow any Repository Connector in Squore, do not specify any repositories
element, which is the equivalent of using:
<repositories all="true" hide="false" />
In order to restrict which Repository Connectors are available, use:
<repositories all="false" hide="false"> <repository name="FROMPATH" checkedInUI="true" > <param name="path" value="/media/sources" /> </repository> <repository name="FROMZIP" /> <repository name="SVN" /> </repositories>
The repository
element accepts the following attributes:
name (mandatory) is the name of the Repository Connector to be used.
It must corresponds to one of the Repository Connectors defined in your configuration
(by default under <SQUORE_HOME>/configuration/repositoryConnectors/[name]).
Note: Each repository element accepts name/value pairs as parameters in which you can override
the values defined in the Repository Connector's default configuration.
The following image illustrates how the configuration above is displayed in Squore:
You may specify whether all or some Data Providers are available, and provide their default settings when the project creation wizard runs.
Data Providers are specified using the tools
element. If you simply want to allow users to pick any Data Provider available in Squore, use:
<tools all="true" expandedInUI="true" />
In order to restrict which Data Providers are available, use:
<tools all="false" expandedInUI="true"> <tool name="SQuORE" optional="false" projectStatusOnFailure="warning" expandedInUI="true" checkedInUI="true" /> <tool name="CheckStyle" optional="true" projectStatusOnFailure="error" checkedInUI="true" /> <tool name="Findbugs_auto" optional="true" projectStatusOnFailure="ignore" checkedInUI="false"> <param name="Findbugs_auto::class_dir" value="/path/to/my/classes" /> </tool> </tools>
The tool
element accepts the following attributes:
name is the name of the Data Provider to be used.
It must corresponds to one of the Data Providers defined in your configuration
(by default under <SQUORE_HOME>/configuration/tools/[name]).
optional (true|false, default: false): When set to false the Data Provider is always included in the analysis, even when not explicitly called from the command line. It also prevents from unchecking it in the web interface. When set to true, the Data Provider is available but not automatically included in an analysis.
projectStatusOnWarning (ignore|warning|error, default: warning) specifies the status to give the analysis if the Data Provider execution finishes in WARN level.
projectStatusOnFailure (ignore|warning|error, default: warning) specifies the status to give the analysis if the Data Provider execution finishes in ERROR or FATAL level.
When set to ignore, the the project ends in the Created state.
When set to warning, the the project ends in the Warning state, which means that a draft is created (even if you required a baseline version to be created).
When set to error, the the project ends in the Error state, which means that no new version is created.
Note: Each tool element accepts name/value pairs as parameters in which you can override
the values defined in the Data Provider's default configuration.
The following image illustrates how the configuration above is displayed in Squore:
When you configure a wizard to create meta-projects, the Data Providers step of the wizard displays a screen that allows you to pick specific versions of existing projects to build a meta project.
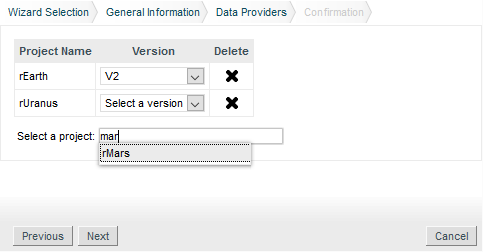
Type the name of a project to add it to your selection, and specify the version to include in your meta-project. There are no other configuration options available, the versions of the selected projects will be grouped in a new project, which will be rated as any other project in this model.
If the wizard definition includes the SQuORE Data Provider, users will be able to select the programming languages for the source code to be analysed.
The picture above shows the Data Provider settings for the Squan Sources Data Provider
defined by these lines in the wizard's Bundle.xml:
<tools> <tool name="SQuORE" optional="false"> <param name="languages" value="cpp:.c,.C,.h,.H;java:.java;csharp:.cs;" availableChoices="cpp;java;csharp"" /> </tool> </tools>
The language settings are defined using the following attributes:
availableChoices
defines the languages available for this wizard. The key must be one of the currently supported languages:
supported languages: ABAP, Ada, C, COBOL, C++, C#, Fortran 77, Fortran 90, Java, JavaScript, Lustre, PHP, PL/SQL, Python, T-SQL, Visual Basic .NET, XAML
corresponding keys: abap, ada, c, cobol, cpp, csharp, fortran77, fortran90, java, javascript, lustre, php, plsql, python, tsql, vbnet, xaml
value
defines the languages checked by default and their extensions when creating a new project, or used by default when not specified explicitly on the command line. One or more languages can be selected, so you can analyse projects containing source code in multiple languages.
You can also specify the list of default extensions for each language by using the
language:extension1,extension2; format. Here is an example of a full language specification:
<param name="languages"
value="c:.c,.h;cpp:.cpp,.h;java;csharp"
availableChoices="cpp;java;csharp" />Note: You can set the same extension for more than one language,
but you will not be able to run an analysis that contains two languages using the same extension.
In the example above, see .h is a valid extension for C and C++, but you will
not be able to select both C and C++ as part of the same project because of the extension clash.
Milestones and goals for your project can be configured in the Wizard Bundle. A milestone has a name, a date, and allows you to set a goal for one or more metric in your project. You can configure your wizard to allow users to create milestones and define goals from scratch, or you can define your company milestones and objectives to ensure that they are part of every project created with this wizard.
In order to add support for milestones to your model, configure your wizard to allow users to create milestones and goals:
<Bundle xmlns:xi="http://www.w3.org/2001/XInclude">
<wizard wizardId="DOC" versionPattern="v#N1#" img="../../Shared/Images/icons/faded.png">
<tools all="FALSE">
<tool name="project_data" optional="FALSE" checkedInUI="TRUE" />
<tool name="Squore" optional="TRUE" checkedInUI="TRUE">
<param name="scnode" value="TRUE" />
<param name="scnode_name" value="Code" />
</tool>
</tools>
<milestones canCreateMilestone="TRUE" canCreateGoal="TRUE">
<goals displayableFamilies="GOALS" />
</milestones>
</wizard>
</Bundle>The
milestones
element allows users to create milestones in
the project creation wizard (canCreateMilestone="TRUE") and also set goals (canCreateGoal="TRUE").
The goals can be set for metrics of the GOALS family only in this example (displayableFamilies="GOALS").
The result in the web UI is the following:
A project wizard allowing users to create milestones freely during an analysis
When creating a new project, a user decides to create a Specification Freeze milestone with one objective of 100 for the Requirement Status indicator. Other goals can be set, for the other metrics in the project that belong to the GOALS family: Risk Index, Task Progress, Test Result.
If you have company-wide milestones and objectives that need to be set for every project created with the wizard, you can specify the goals directly. Milestones can also be marked as mandatory or optional:
<Bundle xmlns:xi="http://www.w3.org/2001/XInclude">
<wizard wizardId="DOC_WITH_MILESTONES" versionPattern="v#N1#" img="../../Shared/Images/icons/faded.png">
<tools all="FALSE">
<tool name="project_data" optional="FALSE" checkedInUI="TRUE" />
<tool name="Squore" optional="TRUE" checkedInUI="TRUE">
<param name="scnode" value="TRUE" />
<param name="scnode_name" value="Code" />
</tool>
</tools>
<milestones canCreateMilestone="TRUE" canCreateGoal="TRUE">
<goals displayableFamilies="GOALS">
<goal measureId="RESULT" mandatory="TRUE" highestIsBest="FALSE" />
<goal measureId="STATUS" mandatory="TRUE" highestIsBest="TRUE" />
<goal measureId="PROGRESS" mandatory="TRUE" highestIsBest="TRUE" />
<goal measureId="RISK_INDEX" mandatory="TRUE" highestIsBest="FALSE" />
</goals>
<milestone id="REQUIREMENT_FREEZE" mandatory="TRUE">
<defaultGoal measureId="RESULT" value="0" />
<defaultGoal measureId="STATUS" value="1" />
<defaultGoal measureId="PROGRESS" value="30" />
<defaultGoal measureId="RISK_INDEX" value="1" />
</milestone>
<milestone id="INFRASTRUCTURE_FREEZE" mandatory="TRUE">
<defaultGoal measureId="RESULT" value="0" />
<defaultGoal measureId="STATUS" value="1" />
<defaultGoal measureId="PROGRESS" value="50" />
<defaultGoal measureId="RISK_INDEX" value="1" />
</milestone>
<milestone id="CODE_FREEZE" mandatory="TRUE">
<defaultGoal measureId="RESULT" value="0" />
<defaultGoal measureId="STATUS" value="1" />
<defaultGoal measureId="PROGRESS" value="90" />
<defaultGoal measureId="RISK_INDEX" value="0.5" />
</milestone>
<milestone id="BETA_RELEASE" mandatory="FALSE">
<defaultGoal measureId="RESULT" value="1" />
<defaultGoal measureId="STATUS" value="1" />
<defaultGoal measureId="PROGRESS" value="95" />
<defaultGoal measureId="RISK_INDEX" value="0.3" />
</milestone>
<milestone id="RELEASE" mandatory="TRUE">
<defaultGoal measureId="RESULT" value="1" />
<defaultGoal measureId="STATUS" value="1" />
<defaultGoal measureId="PROGRESS" value="100" />
<defaultGoal measureId="RISK_INDEX" value="0" />
</milestone>
</milestones>
</wizard>
</Bundle>When creating a new project, the predefined goals are filled in in the web interface, and you can still add a Beta Release milestone (using the default values specified in the wizard bundle) if needed by using the + icon:
A project wizard with preconfigured milestones and goals
The milestones
element accepts the following attributes:
canCreateMilestone
(optional, default: TRUE) defines if a button is available in the web UI to add new milestones
canCreateGoal
(optional, default: TRUE) defines if a button is available in the web UI to add new goals for milestones
hide
(optional, default: FALSE) allows hiding the milestones pane of the wizard in the web interface
The goals
element acceps the following attribute:
The goal
element allows preconfiguring your goals in the project and accepts the following attributes:
The milestone
element accepts the following attributes:
The defaultGoal
element accepts the following attributes:
For a complete example of how to use milestones in a Squore project, consult Appendix D, Milestones Tutorial.
Table of Contents
Each model described in the Squore Configuration defines a set of reports in
the bundle file under <SQUORE_HOME>/Configuration/models/MyModel/Reports/Bundle.xml.
These depend on the Analysis Model chosen, and the role of the currently logged-in user. Every report is
built upon two pieces: a Jasper Report template file, that defines how the report will be organised,
and its content: a set of charts and tabular data.
Here is an example configuration file for a report:
<?xml version="1.0" encoding="UTF-8"?>
<Bundle xmlns:xi="http://www.w3.org/2001/XInclude">
<SquoreReport
id="DR_DASHBOARD_REPORT"
templatePath="../../Shared/Reports/templates/template.jrxml" logo="header_image.png">
<Role name="DEFAULT;PROJECT_MANAGER;DEVELOPER">
<Report type="APPLICATION;FILE">
<Charts displayComments="true">
<xi:include href="../../Analysis/key_performance_indicator.xml"/>
<xi:include href="../../Analysis/Code/ISO9126_Maintainability/MaintainabilityKiviat.xml"/>
<xi:include href="../../Analysis/Code/TechnicalDebt/TechnicalDebtTrend.xml"/>
<xi:include href="../../Analysis/Code/ArtefactRating/FunctionOptimisedPie.xml"/>
</Charts>
<Tables>
<xi:include href="../Dashboards/tables/line_counting.xml" />
<xi:include href="../Dashboards/tables/dates.xml" />
<xi:include href="../Dashboards/tables/levels.xml" />
<xi:include href="../Dashboards/tables/displayed.xml" />
<xi:include href="../Dashboards/tables/ArtefactsTable.xml" />
</Tables>
<Data>
<Findings id="VIOLATIONS" />
<Findings id="PRACTICES" type="ALL_PRACTICE" />
<FindingOccurrences id="RELAXED_FINDINGS" relaxationState="RELAXED" />
<DefectReports id="WORST" />
<Artefacts id="RELAXED_ARTEFACTS" relaxationState="RELAXED" />
<Artefacts id="EXCLUDED_ARTEFACTS" relaxationState="EXCLUDED" />
</Data>
</Report>
</Role>
</SquoreReport>
</Bundle>A Bundle is composed of one or more SquoreReport
elements. Each
SquoreReport
is associated to a Jasper template file (a file with a .jrxml extension).
The attributes allowed for the SquoreReport
element are the following:
The following sections will take you through restricting your template to certain roles or artefact types, and
define which Charts
, Tables
and
Data
(action items and findings) are included in the report.
Squore uses Jasper Reports for its reports templates. A jasper template is an XML file with .jrxml extension. There are three levels of templates used in a Squore report:
The main formatting template, that defines the two main areas (charts and data), which allows to set a specific document template.
A template for the Action Items and Findings lists.
A template for displaying each row of the Action Items and Findings list.
The following generic attributes are available in a report template:
$P{application}: The name of the project.
$P{artefactName}: The name of the artefact
$P{artefactType}: The type of the artefact
$P{author}: The name of the user generating the report
$P{model}: The analysis model used
$P{version}: The name of the version
$P{versionDate}: The creation date of the version
The following attributes specific to charts can also be used:
$P{CHART_ID}: a unique identifier for the chart
$P{CHART_URL_0} to $P{CHART_URL_X}: used to resolve the path to chart [0] to [X]
$P{CHART_NAME_0} to $P{CHART_NAME_X}: used to resolve the name of chart [0] to [X]
Note: iReport is the official visual building tool edited by JasperSoft, the company behind Jasper Reports. Since the template file is written in XML, a simple text editor like Notepad++ can be used, for advanced users at least.
You can override the default header image in the report file by adding a logo
attribute in Bundle.xml, as shown below:
<SquoreReport id="DR_DASHBOARD_REPORT"
templatePath="../../Shared/Reports/templates/template.jrxml"
logo="../../Shared/Reports/templates/header_logo.png">The path to the header logo file is relative to the location of Bundle.xml.
For best results, use a header image with a ratio of 408 by 65 points.
In each SquoreReport
element, one or more Role
elements can be defined to specify what data is needed for this each of user. The only required attribute for the
Role
tag is name
, with a comma-separated list of roles.
If you want your template to be available to any logged-in user, specify the role name DEFAULT.
Each role contains one or mode Report
elements, each one with a
type
attribute that contains the target artefact type for the report template.
Charts
describes the chart elements that the report will display,
according to the template file definition.
The Charts
element has one or more chart
elements. The charts available
for reports are the same as the charts used for dashboards. See the section called “The Charts Area” for a complete
list of available charts. The ID attribute is needed to load generated images in templates. Note that you can choose
to include the chart's comments in the report by setting the displayComments
to
true.
Tables
describes the chart elements that the report will display,
according to the template file definition.
The Tables
element has one or more table
elements. You can
use the tables created for the dashboard or create a table that is not included in any dashboard.
Refer to the section called “Scorecard Tables” for a complete reference about tables.
The Data
element describes the action items (element: DefectReports
),
practices (element: Findings
), relaxed findings (element: FindingOccurrences
)
and artefacts (element: Artefacts
) that will
be included in the report, according to the template file definition.
The attributes allowed for the DefectReports
element are the following:
The attributes allowed for the Findings
element are the following:
Action Items and Findings are sorted in the same way as in the user interface, which you can customise for each model by following the procedure described in the section called “Sort Order for Action Items and Findings”.
The attributes allowed for the FindingOccurrences
element are the following:
id
is a unique identifier for the list of relaxed findings occurrences.
relaxationState
(mandatory) is the filter to apply to the findings occurrences list. The following
values are accepted, so you can generate the same lists as in the web interface:
RELAXED
RELAXED_DEROGATION
RELAXED_LEGACY
RELAXED_FALSE_POSITIVE
Findings occurrences are sorted by artefact path.
The attributes allowed for the Artefacts
element are the following:
Each model described in the Squore Configuration may define a set of
exports in the models/MODEL/Exports/Bundle.xml bundle file.
Exports available in the user interface depend on the role of the currently
logged-in user and the selection in the Project Portfolios and the Artefact Tree
views.
Here is an example of a bundle file:
<?xml version="1.0" encoding="UTF-8"?>
<Bundle>
<Role name="ADMINISTRATOR;PROJECT_MANAGER">
<Export type="MODEL">
<ExportScript name="Project Portfolio" script="${scriptDir}/sqexport.pl">
<arg value="-f" />
<arg value="${outputFile}" />
<arg value="versions" />
<arg value="-ml" />
<arg value="${idModel}" />
</ExportScript>
</Export>
<Export type="APPLICATION">
<ExportScript name="Functions with level G" script="${scriptDir}/sqexport.pl">
<arg value="-f" />
<arg value="${outputFile}" />
<arg value="artefacts" />
<arg value="-mR" />
<arg value="-T" />
<arg value="${types['FUNCTION']}" />
<arg value="-L" />
<arg value="LEVELG" />
<arg value="-u" />
<arg value="${idUser}" />
<arg value="${idModel}" />
</ExportScript>
</Export>
</Role>
</Bundle>
The default Squore configuration includes the following scripts by default. Each script is described in an appendix at the end of this manual.
The Bundle.xml file above contains some variables
that are replaced at runtime. The following is the list of variables that
can be used in the ExportScript
and
arg
XML elements.
Note that the ${outputFile} variable is mandatory.
Used to resolve the location of the addons directories on Squore Server, in
which the scripts/export-scripts subdirectory contains the default
scripts.
Used to resolve the location of the configuration directories on Squore Server,
in which the <MODEL_NAME>/Exports subdirectory contains
the scripts you added to the product.
The base URL of the Squore server.
The name of the output file where the export script writes to. The filename is guaranteed to be unique on each call.
The identifier of the logged in user.
The identifier of the model that is currently selected in the Project Portfolios.
The identifier of the application that is currently selected in the Project Portfolios.
The identifier of the version that is currently selected in the Project Portfolios.
The identifier of the artefact that is currently selected in the Artefact Tree.
This function resolves at runtime the type aliases of TYPENAME. That may be used to simplify bundles, as you may achieve the exact same thing by manually listing all types. The result is a coma separated list of types.
Table of Contents
The list of action items raised by Squore according to the triggers configured in your decision model can be exported out of Squore so it is reused and managed in any third-party application you use to track defects or issues. By default, Squore supports exporting in these formats:
This list can be expanded by adding custom export formats to your configuration.
Before making a new export available, you need to understand the information that is available to export. In order to see the full export, export action items from Squore using the XML export to dumps all the information available to an xml file. Creating a new format is as simple as creating a stylesheet to manipulate the contents of the full export to your liking.
Let's first look at what an export
configuration looks like. On Squore Server, go to <SQUORE_HOME>/Configuration/scripts/export.
Each export format is specified in its own folder. Each export format is defined by two files: transform.xsl
and export.properties. The file file transform.xsl is a stylesheet to define what information
gets exported, and the file export.properties defines the extension and charset of the export file.
Note: The export.properties file is optional. If omitted, Squore will create a file with a ".xml" extension using the UTF-8_BOM character set, as if using the file below:
charsetName = UTF-8_BOM extension = .xml
For more information about available charsets, consult http://docs.oracle.com/javase/6/docs/api/java/nio/charset/Charset.html
After you to define your stylesheet, create a new folder called MyCustomExport
in Squore's configuration folder and create the two definition files needed by saving your stylesheet as transform.xsl
and specifying the desired extension and charset for the report file . The new export format will be available in Squore the next time
you refresh your dashboard.
Table of Contents
The Highlights tab in Squore's Explorer is a flat list of artefacts in predefined categories for a model. These categories are defined in your model by including content in the highlights Bundle.xml file for your model. In this chapter, you will learn to understand the default highlights in the default models and will be able to consult the full reference for formatting a highlights bundle.
The default highlights bundle looks similar to this:
<Bundle>
<Role name="DEFAULT" preSelectedType="FUNCTION">
<Filters type="PACKAGES">
<TopArtefacts id="TOP_10_WORST_ARTEFACTS"
order="DESC" resultSize="10"/>
<TopDeltaArtefacts id="TOP_10_MOST_DETERIORATED_ARTEFACTS"
order="DESC" resultSize="10"/>
<TopDeltaArtefacts id="TOP_10_MOST_IMPROVED_ARTEFACTS"
order="ASC" resultSize="10"/>
<TopBorderlineArtefacts id="TOP_10_'BORDERLINE'_ARTEFACTS"
order="ASC" minLevel="LEVELC" resultSize="10"/>
<TopNewArtefacts id="ALL_NEW_ARTEFACTS"
order="DESC" resultSize="*"/>
<TopModifiedArtefacts id="ALL_MODIFIED_ARTEFACTS"
order="DESC" resultSize="*"/>
</Filters>
</Bundle>This results in the following flat lists being displayed in Squore:
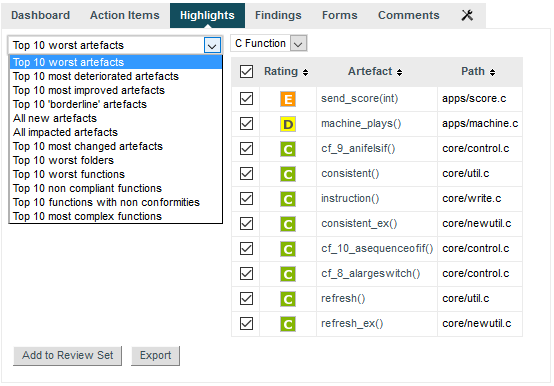
The Squore Default Highlight Categories
The top element of the highlights bundle consists of a Bundle
top element in which two elements are allowed:
Role
defines the user roles allowed to use the predefined highlight categories for this model using a
name
(mandatory) and the default artefact type selected in the UI using a
preSelectedType
(mandatory).
Filters
defines a list of highlight categories for certain types of artefact types, defined using the type
attribute.
There are several types of predefined highlights categories:
TopArtefacts
is used to retrieve artefacts with
the biggest value for a given measure.
TopDeltaArtefacts
is used to retrieve artefacts
with the biggest variation in the value of a given measure since an earlier version.
TopBorderlineArtefacts
is used to retrieve
artefacts that are closest to the upper limit of a given scale level, and therefore
most likely to be easy to improve with the smallest effort.
TopNewArtefacts
is used retrieve artefacts that
are new in the current version, sorted according to the value of a given measure.
TopModifiedArtefacts
is used to retrieve the artefacts
modified in the current version, sorted according to the value of a given measure.
TopArtefacts
allows the following attributes:
artefactTypes
(optional) defines the types of artefacts to filter on.
excludingTypes
(optional, default: none) lists the artefact types for which the metric should not be displayed. This allows refining the types entered in the main filter above.
measureId
(optional, default: the measureId associated with the root indicator) is the name of the measure Id to filter on.
order
(optional, default: ASC) is the sort order for the list according to the reference measure ID. Valid values are ASC and DESC.
altMeasureId
(optional, default: empty) is the second measure ID to use for sorting.
altOrder
(optional, default: empty) is the sort order for the second measure ID. Valid values are ASC and DESC.
resultSize
(mandatory) is the number of results to include in the list. Use 10 to display 10 artefacts or * to display all artefacts.
TopDeltaArtefacts
allows the following attributes:
artefactTypes
(optional) lists the types of artefacts to filter on.
measureId
(optional, default: LEVEL) is the name of the measure Id to filter on.
order
(mandatory) is the sort order for the list according to the reference measure ID. Valid values are ASC and DESC.
resultSize
(mandatory) is the number of results to include in the list. Use 10 to display 10 artefacts or * to display all artefacts.
TopBorderlineArtefacts
allows the following attributes:
artefactTypes
(optional) lists the types of artefacts to filter on.
indicatorId
(optional, default: LEVEL) is the name of the measure Id to filter on.
minLevel
(optional, default: empty) is The name of the rank to be used as the threshold for results. If you want to exclude artefacts above LEVELC, set minLevel to LEVELC.
order
(mandatory) is the sort order for the list according to the reference measure ID. Valid values are ASC and DESC.
resultSize
(mandatory) is the number of results to include in the list. Use 10 to display 10 artefacts or * to display all artefacts.
TopNewArtefacts
allows the following attributes:
artefactTypes
(optional) lists the types of artefacts to filter on.
measureId
(optional, default: LEVEL) is the name of the measure Id to filter on.
order
(mandatory) is the sort order for the list according to the reference measure ID. Valid values are ASC and DESC.
resultSize
(mandatory) is the number of results to include in the list. Use 10 to display 10 artefacts or * to display all artefacts.
TopModifiedArtefacts
allows the following attributes:
artefactTypes
(optional) is the types of artefacts to filter on.
order
(mandatory) is the sort order for the list according to the reference measure ID. Valid values are ASC and DESC.
resultSize
(mandatory) is the number of results to include in the list. Use 10 to display 10 artefacts or * to display all artefacts.
All highlights categories support the following nested elements, to customise output:
Column
allows the following attributes:
artefactTypes
(optional, default: the parent value of artefactTypes
) lists the artefact types for which the metric should be displayed. This allows refining the types entered in the main filter above.
excludingTypes
(optional, default: the parent value of excludingTypes
) lists the artefact types for which the metric should not be displayed. This allows refining the types entered in the main filter above.
headerDisplayType
(optional, default: NAME) is the label to display in the header. The supported values are:
NAME is the measure's name
MNEMONIC is the measure's mnemonic
displayType
(optional, default: VALUE) sets the value display type. The supported values are:
VALUE for the measure's numeric value
RANK for the indicator's rank
ICON for the indicator's rank icon
DATE for the measure's value, displayed as a UTC date
DATETIME for the measure's value, displayed as a UTC date and time
TIME for the measure's value, displayed as a UTC time
dateStyle
(optional, default: DEFAULT): the date formatting style,
used when the displayType is one of DATE or DATETIME.
timeStyle
(optional, default: DEFAULT): the time formatting style,
used when the displayType is one of DATETIME or TIME. See above for available styles.
datePattern (formerly dateFormat)
(optional, default: empty): the date pattern, used when
the displayType is one of DATE,
DATETIME or TIME.
If this attribute is set, both dateStyle and timeStyle attributes are ignored. The date is formatted using the supplied pattern. Any format compatible with the Java Simple Date Format can be used. Refer to http://docs.oracle.com/javase/6/docs/api/java/text/SimpleDateFormat.html for more information.
decimals
(optional, default: 2) sets the number of decimals, used when
the displayType is VALUE.
suffix
(optional, default: empty) is the text to display after the measure.
Either measureId
, infoId
or indicatorId
is required.
Note that all display related tags, except headerDisplayType
and displayType
are ignored when infoId
is used.
Where
allows the following attributes:
Either measureId
or infoId
is required.
Either value
or bounds
is required.
Note that bounds
is not supported if infoId
.
You can build interactive tutorials to help users understand which areas of Squore to focus on, or help them discover and reach new functionality. This chapter teaches you about the concepts behind the design of a tutorial in Squore and highlights how you can expand on the existing framework.
A tutorial explaining the purpose of the Project Portfolios.
Here are the key concepts you should understand about tutorials before reading further:
A tutorial is a series of steps that users follow in the web interface. Each step can highlight parts of the user interface, and display help text to make it obvious what to look at and why. Optionally, a step may allow users to interact with the web interface so they can try out the concept that is being explained by themselves before moving on to the next step of the tutorial.
Steps can be grouped in phases to make the flow of your tutorial more logical and perform actions before a step is executed.
Users launch tutorials from ? > Tutorials, which lists all the available tutorials in two sections: general-purpose tutorials, which apply to the application in general, and model-specific tutorials, which apply to a specific analysis model.
Like most other aspects of Squore, tutorials are fully localisable via the use of properties files.
Before you create your first tutorial, you must decide if it addresses general application
features or if it is specific to a model. Your choice impacts the location of the Bundle.xml file that will
reference your tutorial:
Application tutorials should be referenced in MyConfiguration/configuration/tutorials/Bundle.xml and
their properties must be located in MyConfiguration/configuration/models/Shared/Description/tutorial_en.properties
Model tutorials are referenced in MyConfiguration/configuration/models/MyModel/Tutorials/Bundle.xml and
their properties can be located in any .properties file included in the model's description bundle.
The tutorial selection popup showing general tutorials and model-specific tutorials.
Tutorials use an XML syntax where each help
element is a separate tutorial, made of
several item
elements used to highlight elements of the web interface and define help text to display
next to them. In order to control the flow of the tutorial and the display of elements, you can group items
in phase
elements, and perform pre-requisite actions to carry out before
an element is highlighted.
Here is a simple 4-step example in XML, followed by screenshots of each step:
<help id="DASHBOARD_TOUR" icon="dashboard_tour/icon.png">
<item element="DRILLDOWN" descrId="EXPLAIN_DRILLDOWN" />
<phase type="PROGRESSIVE" textPosition="RIGHT">
<item element="PORTFOLIO_TREE" descrId="EXPLAIN_PORTFOLIOS" maskColor="#2AA0D5"/>
<item element="ARTEFACT_TREE" descrId="EXPLAIN_ARTEFACT_TREE" maskColor="#FF193B" />
<item element="MEASURE_TREE" descrId="EXPLAIN_INDICATOR_TREE" maskColor="#B2AB09" />
</phase>
</help>
Step 1: Highlight and explain the drilldown panel
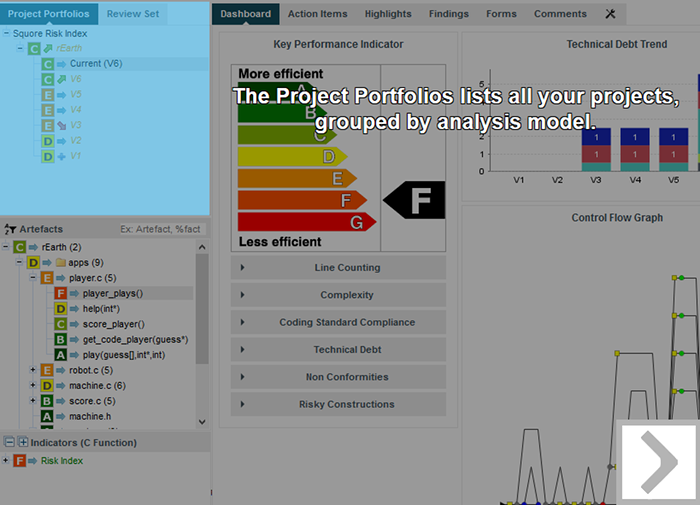
Step 2: Highlight and explain the Project Portfolios
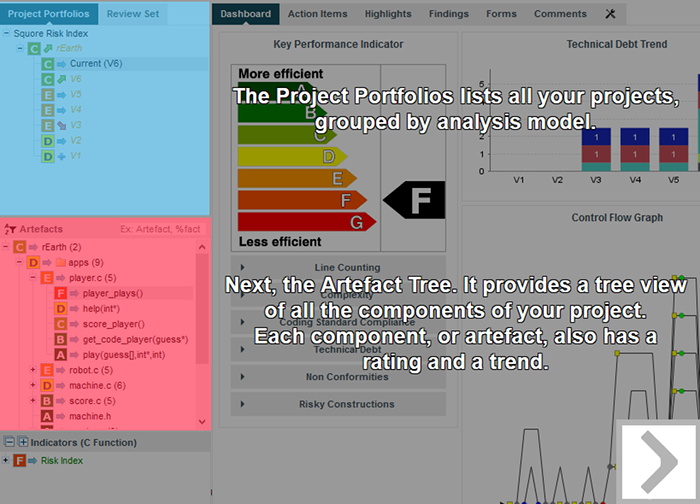
Step 3: Highlight and explain the Artefact Tree, keeping the previous element highlighted, since we are in a progressive phase
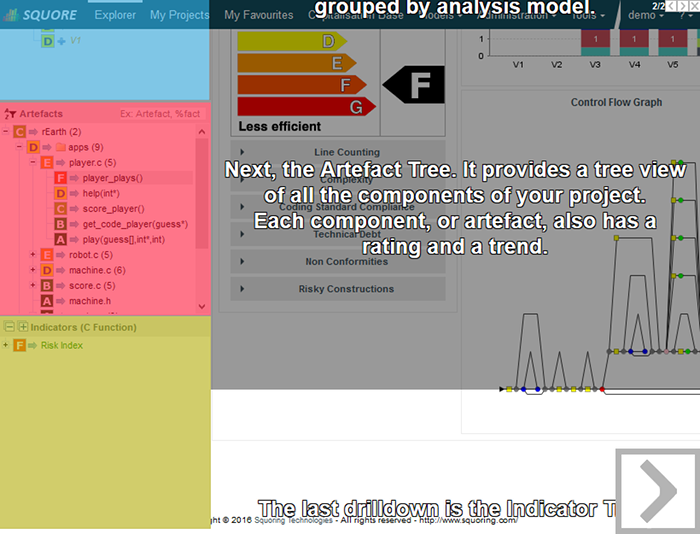
Step 4: Highlight and explain the Indicator Tree in the final step of the progressive phase of the tutorial
More information about the XML syntax you can use to create tutorials is explained in the section called “Tutorial Syntax Reference”.
Each tutorial in your bundle is bound by a help
element. The help
element supports
the following attributes:
id
(mandatory) is the internal ID of the tutorial, which you can use in a properties file to translate as needed (using TUTO.<id>.NAME and TUTO.<id>.DESCR) to display in the correct language in the Tutorials popup in the web interface.
icon
(optional, default: standard tutorial icon) is the path to the icon to display for this tutorial in the tutorial selection popup. The icon is relative to the location of Bundle.xml.
opacity
(optional, default: 0.4) is the opacity of the mask (the grey element that surrounds the highlighted element) for this tutorial. You can specify a value between 0 and 1 where 0 is transparent and 1 is completely opaque.
firstConnectionGroup
(optional, default: none) allows launching this tutorial automatically for users of the specified groups the first time that they log into Squore. This attribute accepts a semicolon-separated list of groups.
textPosition
(optional, default: EXTERNAL) is the location of the help text relative to the highlighted element. This attribute supports the following values:
INTERNAL to display the text inside the item
LEFT to display the text to the left of the item
RIGHT to display the text to the right of the item
EXTERNAL to display the text dynamically to the left or the right of the item, depending on where more space is available
TOP to display the text above the item
BOTTOM to display the text under the item
maskColor
(optional, default: transparent) is the colour of
the mask to display over the highlighted element. This attribute supports the colour syntax detailed in [colour syntax] .
maskOpacity
(optional, default:0.6) is the opacity of the mask over the highlighted element for this tutorial. You can specify a value between 0 and 1 where 0 is transparent and 1 is completely opaque.
textSize
(optional, default: 25) is the size of the help text displayed next to the highlighted element.
textColor
(optional, default: WHITE) is the colour of the help text displayed next to the highlighted element.
The help
element accepts one or more item
or
phase
elements. If you simply want to highlight items one at a time, add item
elements
directly in the help
. Using phase
elements is useful if you want to execute specific
actions or display several items at the same time.
The phase
element accepts the following attributes:
element
(optional, default: none) is the selector of the item to highlight when this phase starts. You can choose any element from the list of predefined selectors described in the section called “Element Selectors”.
param
(optional, default: none) is an optional parameter which you can pass to certain selectors. This parameter is generally used when you specify to highlight a specific chart, metric or artefact as opposed to the first element available. You can read more about the selectors that support parameters in the section called “Element Selectors”.
type
(optional, default: SEQUENTIAL) allows specifying the display behaviour of the child items of this phase. The supported values are:
SEQUENTIAL to highlight items one at a time
PARALLEL to highlight all items in this phase at the same time
PROGRESSIVE to highlight items in succession, retaining the previous highlight at each click
FREE to allow users to perform actions inside the highlighted item
The item
element accepts the following attributes:
element
(mandatory) is the selector of the item to highlight. You can choose any element from the list of predefined selectors described in the section called “Element Selectors”.
param
(optional, default: none) is an optional parameter which you can pass to certain selectors. This parameter is generally used when you specify to highlight a specific chart, metric or artefact as opposed to the first element available. You can read more about the selectors that support parameters in the section called “Element Selectors”.
descrId
(mandatory) is the ID of the help text to display for the highlighted element. Use this ID is used in your properties file to localise the tutorial.
linkId
(optional, default: none) allows creating a link to another tutorial. The value must be the name
of another tutorial defined in the same bundle. You can specify several links by separating them with a /.
You can use a preAction
element in a phase if you want to carry out an action before highlighting
a specific item. The preAction
element supports the following attributes:
action
(mandatory) is the action to perform. The supported actions are:
EXPAND_PORTFOLIO_TREE expands the Project Portfolios down to project level. This action accepts a project name as a parameter, otherwise it uses the first project available.
COLLAPSE_PORTFOLIO_TREE collapses the entire Project Portfolios
SELECT_MODEL selects a model in the Project Portfolios. This action accepts a model name as a parameter, otherwise it uses the first model available.
SELECT_PROJECT expands a project node in the Project Portfolios to show its list of versions and select the most recent one. This action accepts a project name and version as a parameter (e.g.: Earth/V6), otherwise it uses the first project available.
EXPAND_ARTEFACT_TREE expands the Artefact Tree. This action accepts the path to an artefact as a parameter (e.g.: Earth/apps/machine.c), otherwise it uses the first artefact available.
COLLAPSE_ARTEFACT_TREE collapses the entire Artefact Tree.
SELECT_ARTEFACT clicks an artefact in the Artefact Tree to show its dashboard
SELECT_ARTEFACT_LEAF clicks the first lowest-level artefact leaf in the Artefact Tree.
EXPAND_MEASURE_TREE expands the Indicator Tree. This action accepts the path to a metric as a parameter (e.g.: Maintainability/Analysability/Function Analysability), otherwise it uses the first available measure in the tree.
COLLAPSE_MEASURE_TREE collapses the entire Indicator Tree.
SELECT_WIZARD picks a wizard from the list of wizards available in the first step of the project creation wizard. This action requires a wizardId (e.g.: RISK) as a parameter.
RUN_PROJECT_CREATION clicks the Run button on the summary screen of the project creation wizard.
param
(optional, default: none) is an optional parameter you can pass to an action if it supports it.
clickIndicator
(optional, default: varies according to the action) allows showing or hiding the click indicator when the action is performed. This attribute supports the values TRUE and FALSE.
It is generally not necessary to specify any preAction
, since each element selector automatically places
the web interface in the right context to highlight the specified item. For example, if you specify that a tutorial should highlight the Findings
tab, the tutorial will open the Explorer and switch to the Findings tab automatically for the first project available. It is only necessary to use a
preAction
if you want a specific project or model to be selected before showing the Findings tab.
The table below lists the selectors that you can use in the
item
or phase
elements of your tutorials. when
a parameter is allowed, it is specified. If no parameter is specified, the first available item is usually
highlighted.
Table 12.1. Available element selectors for tutorials in Squore
| element | param | Highlighted Element |
|---|---|---|
| CUSTOM | The JQuery selector of the element of the Squore UI you want to highlight | - |
| BODY | - | the part of the window containing the Squore UI |
| TOP | - | the entire window |
| BREADCRUMBS | - | the breadcrumbs bar |
| MENU_BAR | - | the menu bar |
| MENU_BAR_HOME | - | the home button in the menu bar |
| MENU_BAR_EXPLORER | - | the Explorer button in the menu bar |
| MENU_BAR_MY_PROJECTS | - | the My Projects button in the menu bar |
| MENU_BAR_MY_FAVOURITES | - | the My Favourites button in the menu bar |
| MENU_BAR_CAPITALISE | - | the Capitalisation Base button in the menu bar |
| MENU_BAR_USER | - | the <username> in the menu bar |
| MENU_MODEL | - | the Models button in the menu bar |
| MENU_ADMIN | - | the Administration button in the menu bar |
| MENU_HELP | - | the ? in the menu bar |
| HOME_PAGE | - | the home page |
| HOME_WELCOME | - | the welcome text on the home page |
| HOME_USER | - | the user details section of the home page |
| HOME_WORK | - | the list of tasks available to users on the home page |
| HOME_HELP | - | the help section of the home page |
| HOME_PINNED | - | the list of pinned artefacts on the home page |
| HOME_HISTORY | - | the list of recently visited projects on the home page |
| HOME_EXPLORER | - | the link to the Explorer on the home page |
| HOME_PROJECTS | - | the link to My Projects on the home page |
| HOME_CAPITALISE | - | the link to the Capitalisation Base on the home page |
| SUB_MENU_MODEL | - | the entire Models menu |
| SUB_MENU_MODEL_ROW | a row ID | the specified option in the Models menu |
| SUB_MENU_MODEL_ROW_FIRST | - | the first option in the Models menu |
| SUB_MENU_ADMIN | - | the entire Administration menu |
| SUB_MENU_ADMIN_ROW | a row ID | the specified option in the Administration menu |
| SUB_MENU_ADMIN_ROW_FIRST | - | the first option in the Administration menu |
| SUB_MENU_HELP | - | the entire Help menu |
| SUB_MENU_HELP_ROW | a row ID | the specified option in the Help menu |
| SUB_MENU_HELP_ROW_FIRST | - | the first option available in the Help menu |
| TUTORIAL_POPUP | - | the tutorial selection popup |
| TUTORIAL_POPUP_MODEL | a model ID | the tutorials for the specified model in the tutorial selection popup |
| TUTORIAL_POPUP_MODEL_FIRST | - | the first model-specific tutorial available in the tutorial selection popup |
| TUTORIAL_POPUP_TUTORIAL_NAME | a tutorial's id
| the specified tutorial |
| TUTORIAL_POPUP_TUTORIAL_NAME_FIRST | - | the name
of the first available tutorial in the tutorial selection popup |
| TUTORIAL_POPUP_TUTORIAL_DESCR | a tutorial's id
| the description of the specified tutorial |
| TUTORIAL_POPUP_TUTORIAL_DESCR_FIRST | - | the description of the first available tutorial in the tutorial selection popup |
| EXPLORER | - | the Explorer |
| DRILLDOWN | - | the drilldown pane of the Explorer |
| EXPLORER_TAB | - | the right-hand panel of the Explorer |
| PORTFOLIO_TREE | - | the Project Portfolios |
| ARTEFACT_TREE | - | the Artefact Tree |
| MEASURE_TREE | - | the Indicator Tree |
| EXPLORER_HEADER | - | the Explorer tabs |
| PORTFOLIO_HEADER | - | the Project Portfolios tabs |
| ARTEFACT_TREE_SEARCH | - | the search box in the Artefact Tree |
| ARTEFACT_TREE_FILTER | - | the filter button in the Artefact Tree |
| REVIEW_SET | - | the Review Set |
| PORTFOLIO_TREE_PROJECT | a project name (Earth) or name and version (Earth/V3) | a project and its list of versions in the Project Portfolios |
| PORTFOLIO_TREE_PROJECT_FIRST | - | the first project in the Project Portfolios and its versions |
| MODEL_DASHBOARD | a model ID | the dashboard for the specified model |
| MODEL_CHARTS | a model ID | the charts section of the dashboard for specified model |
| MODEL_CHART_FIRST | a model ID | the first chart in the dashboard of the specified model |
| MODEL_TABLE | a model ID | the table section of the dashboard for the specified model |
| MODEL_TABLE_ROW_FIRST | a model ID | the first table row in the dashboard of the specified model |
| MODEL_CHART | a chart ID | the specified chart in the dashboard for the specified model |
| MODEL_TABLE_ROW | a project name (Earth) or name and version (Earth/V3) | the specified project in the dashboard for the specified model |
| MODEL_CHART_POPUP | a chart ID | the chart viewer with the specified model-level chart |
| MODEL_CHART_POPUP_GRAPH | a chart ID | The chart in the chart viewer |
| MODEL_CHART_POPUP_PREVIOUS_ARROW | a chart ID | the previous arrow in the chart viewer |
| MODEL_CHART_POPUP_NEXT_ARROW | a chart ID | the next arrow in the chart viewer |
| MODEL_CHART_POPUP_NAV_BAR | a chart ID | the carousel in the chart viewer |
| MODEL_CHART_POPUP_ASIDE | a chart ID | the right-hand panel of the chart viewer |
| MODEL_CHART_POPUP_ASIDE_HEAD | a chart ID | the tabs in the right hand panel of the chart viewer |
| MODEL_CHART_POPUP_DESCR | a chart ID | the description panel of the chart viewer |
| FILTER_POPUP | a project name (Earth) or name and version (Earth/V3) | the filter popup |
| FILTER_LEVEL | a project name (Earth) or name and version (Earth/V3) | the levels section of the filter popup |
| FILTER_TYPE | a project name (Earth) or name and version (Earth/V3) | the types section fo the filter popup |
| FILTER_EVOLUTION | a project name (Earth) or name and version (Earth/V3) | the evolution section of the filter popup |
| FILTER_STATUS | a project name (Earth) or name and version (Earth/V3) | the status section of the filter popup |
| ARTEFACT_TREE_LEAF | a project name (Earth) or name and version (Earth/V3) | a lowest-level artefact of a project int he artefact_tree; |
| MEASURE_TREE_LEAF | a project name (Earth) or name and version (Earth/V3) | a lowest-level metric in the Indicator Tree |
| DASHBOARD | a project name (Earth) or name and version (Earth/V3) | the dashboard for a project |
| SCORECARD | a project name (Earth) or name and version (Earth/V3) | the scorecard |
| KPI | a project name (Earth) or name and version (Earth/V3) | the KPI chart in the scorecard |
| CHARTS | a project name (Earth) or name and version (Earth/V3) | the charts section of the dashboard |
| TABLES | a project name (Earth) or name and version (Earth/V3) | the tables in the scorecard |
| CHART_FIRST | a project name (Earth) or name and version (Earth/V3) | the first chart in the dashboard |
| LINE | a project name (Earth) or name and version (Earth/V3) | a line in a table |
| CHART | a chart ID | the specified chart |
| CHART_FIRST | - | the first chart in the dashboard |
| TABLE | a table ID | a table in the scorecard |
| TABLE_FIRST | - | the first table in the scorecard |
| MEASURE_POPUP | a measure, indicator or info ID | the information popup for a metric |
| MEASURE_POPUP_CONTENT | a measure, indicator or info ID | the contents of the information popup for the metric |
| MEASURE_POPUP_LEVELS | a measure, indicator or info ID | the scale for the metric in the information popup |
| MEASURE_POPUP_ROW_FIRST | a measure, indicator or info ID | the first row in the information popup |
| MEASURE_POPUP_ROW | a row ID in the information popup | the specified row in the information popup |
| CHART_POPUP | a chart ID | the chart viewer |
| CHART_POPUP_GRAPH | a chart ID | the chart in the chart viewer |
| CHART_POPUP_COMPARE_OPTION | a chart ID | the compare mode button |
| CHART_POPUP_PREVIOUS_ARROW | a chart ID | the previous arrow in the chart viewer |
| CHART_POPUP_NEXT_ARROW | a chart ID | the next arrow in the chart viewer |
| CHART_POPUP_NAV_BAR | a chart ID | the carousel in the chart viewer |
| CHART_POPUP_ASIDE | a chart ID | the right-hand panel of the chart viewer |
| CHART_POPUP_ASIDE_HEAD | a chart ID | the tabs in the right hand panel of the chart viewer |
| CHART_POPUP_DESCR | a chart ID | the description panel of the chart viewer |
| CHART_POPUP_COMMENTS | a chart ID | the comments panel of the thart viewer |
| CHART_POPUP_FAVORITES | a chart ID | the favourites panel of the chart viewer |
| CHART_POPUP_COMPARATIVE_CHART | a version name | the older version of the chart in the chat viewer in compare mode |
| ACTION_ITEMS | a project name (Earth) or name and version (Earth/V3) | the Action Items tab of the Explorer |
| ACTION_ITEMS_TABLE | a project name (Earth) or name and version (Earth/V3) | the Action Items table |
| ACTION_ITEMS_TABLE_HEAD | a project name (Earth) or name and version (Earth/V3) | the Action Items table header |
| ACTION_ITEMS_TABLE_HEAD_CHECK | a project name (Earth) or name and version (Earth/V3) | the Action Items Select All checkbox |
| ACTION_ITEMS_ADD_REVIEW_SET | a project name (Earth) or name and version (Earth/V3) | the Action Items Add to review set button |
| ACTION_ITEMS_EXPORT_LIST | a project name (Earth) or name and version (Earth/V3) | the Action Items export formats |
| ACTION_ITEMS_EXPORT_BUTTON | a project name (Earth) or name and version (Earth/V3) | the Action Items export button |
| ACTION_ITEMS_SEARCH | a project name (Earth) or name and version (Earth/V3) | the Action Items filtering options |
| ACTION_ITEMS_ROW | a project name (Earth) or name and version (Earth/V3) | a single action item |
| ACTION_ITEMS_REASON | a project name (Earth) or name and version (Earth/V3) | a detailed action item |
| ACTION_ITEMS_ADVANCED_SEARCH | a project name (Earth) or name and version (Earth/V3) | the Action Items advanced filtering options |
| ACTION_ITEMS_ADVANCED_SEARCH_SELECT_FIRST | a project name (Earth) or name and version (Earth/V3) | the Action Items advanced filtering options with a selection applied |
| ACTION_ITEMS_ADVANCED_SEARCH_SELECT | The name of a list of the advanced search | the Action Items with the specified selection applied |
| HIGHLIGHTS | a project name (Earth) or name and version (Earth/V3) | the Highlights tab of the Explorer |
| HIGHLIGHTS_TABLE | a project name (Earth) or name and version (Earth/V3) | the Highlights table |
| HIGHLIGHTS_TABLE_HEAD | a project name (Earth) or name and version (Earth/V3) | the Highlights table header |
| HIGHLIGHTS_TABLE_HEAD_CHECK | a project name (Earth) or name and version (Earth/V3) | the Highlights table Select All checkbox |
| HIGHLIGHTS_SEARCH | a project name (Earth) or name and version (Earth/V3) | the Highlights options |
| HIGHLIGHTS_SEARCH_FILTER | a project name (Earth) or name and version (Earth/V3) | the Highlights categories list |
| HIGHLIGHTS_SEARCH_TYPE | a project name (Earth) or name and version (Earth/V3) | the Highlights artefact type list |
| HIGHLIGHTS_EXPORT_BUTTON | a project name (Earth) or name and version (Earth/V3) | the Highlights export button |
| HIGHLIGHTS_ADD_REVIEW_SET | a project name (Earth) or name and version (Earth/V3) | the Highlights Add to review set button |
| HIGHLIGHTS_ROW_FIRST | a project name (Earth) or name and version (Earth/V3) | the first row of Highlights in the table |
| FINDINGS | a project name (Earth) or name and version (Earth/V3) | the Findings tab of the Explorer |
| FINDINGS_TABLE | a project name (Earth) or name and version (Earth/V3) | the Findings table |
| FINDINGS_TABLE_HEAD | a project name (Earth) or name and version (Earth/V3) | the Findings table header |
| FINDINGS_SEARCH | a project name (Earth) or name and version (Earth/V3) | the Findings filtering controls |
| FINDINGS_RULE | a project name (Earth) or name and version (Earth/V3) | the Findings table |
| FINDINGS_ARTEFACT | a project name (Earth) or name and version (Earth/V3) | artefacts in the Findings table |
| FINDINGS_ROW_FIRST | a project name (Earth) or name and version (Earth/V3) | the first row in the Findings table |
| FINDINGS_ADVANCED_SEARCH | a project name (Earth) or name and version (Earth/V3) | advanced filtering options in the Findings table |
| FINDINGS_ADVANCED_SEARCH_SELECT_FIRST | a project name (Earth) or name and version (Earth/V3) | a selection in the advanced filtering options in the Findings table |
| FINDINGS_ADVANCED_SEARCH_SELECT | The name of a list of the advanced search | a selection in the advanced filtering options in the Findings table |
| REPORTS | a project name (Earth) or name and version (Earth/V3) | the Reports tab of the Explorer |
| REPORTS_REGION | a project name (Earth) or name and version (Earth/V3) | the Reports section |
| REPORTS_OPTIONS | a project name (Earth) or name and version (Earth/V3) | the Reports options |
| REPORTS_OPTION_TEMPLATE | a project name (Earth) or name and version (Earth/V3) | the available report templates |
| REPORTS_OPTION_FORMAT | a project name (Earth) or name and version (Earth/V3) | the available report formats |
| REPORTS_OPTION_SYNTHETIC_VIEW | a project name (Earth) or name and version (Earth/V3) | the synthetic report option |
| REPORTS_CREATE | a project name (Earth) or name and version (Earth/V3) | the Generate button button |
| EXPORT_REGION | a project name (Earth) or name and version (Earth/V3) | the Exports section |
| EXPORT_OPTIONS | a project name (Earth) or name and version (Earth/V3) | the Exports options |
| EXPORT_CREATE | a project name (Earth) or name and version (Earth/V3) | the Exports Create button |
| FORMS | a project name (Earth) or name and version (Earth/V3) | the Forms tab of the Explorer |
| FORMS_ATTRIBUTE | a project name (Earth) or name and version (Earth/V3) | a form attribute name |
| FORMS_ATTRIBUTE_FIELD | a project name (Earth) or name and version (Earth/V3) | a form attribujte value |
| FORMS_ATTRIBUTE_COMMENT | a project name (Earth) or name and version (Earth/V3) | a form attribute justification |
| FORMS_HISTORY | a project name (Earth) or name and version (Earth/V3) | a form value history |
| FORMS_BLOCK | a project name (Earth) or name and version (Earth/V3) | a form block |
| INDICATORS | a project name (Earth) or name and version (Earth/V3) | the Indicators tab of the Explorer |
| INDICATORS_TABLE | a project name (Earth) or name and version (Earth/V3) | the Indicators table |
| INDICATORS_TABLE_HEAD | a project name (Earth) or name and version (Earth/V3) | the Indicators table header |
| INDICATORS_ROW | a project name (Earth) or name and version (Earth/V3) | a row in the Indicators table |
| MEASURES | a project name (Earth) or name and version (Earth/V3) | the Measures tab of the Explorer |
| MEASURES_TABLE | a project name (Earth) or name and version (Earth/V3) | the Measures table |
| MEASURES_TABLE_HEAD | a project name (Earth) or name and version (Earth/V3) | the Measures table header |
| MEASURES_ROW | a project name (Earth) or name and version (Earth/V3) | a row in the Measures table |
| COMMENTS | a project name (Earth) or name and version (Earth/V3) | the Comments tab of the Explorer |
| COMMENTS_TABLE | a project name (Earth) or name and version (Earth/V3) | the Comments table |
| COMMENTS_TABLE_HEAD | a project name (Earth) or name and version (Earth/V3) | the Comments table header |
| COMMENTS_ROW | a project name (Earth) or name and version (Earth/V3) | a row in the Comments header |
| CREATE_PROJECT_BUTTON | - | the New Project... button on the My Projects page |
| WIZARD_PANEL | - | the list of wizards in the project creation wizard |
| WIZARD_ROW | a wizard ID | a wizard in the list of wizards in wizards in the project creation wizard |
| WIZARD_ROW_FIRST | - | the first wizard in the list of wizards in the project creation wizard |
| WIZARD_NEXT_BUTTON | - | the Next button on the first page of the project creation wizard |
| GENERAL_INFORMATION | - | the General Information section of the project creation wizard |
| PROJECT_IDENTIFICATION_BLOCK | - | the Project Identification section of the project creation wizard |
| GENERAL_INFO_BLOCK | - | the General Information section of the project creation wizard |
| GENERAL_INFO_ROW | - | a row in the General Information section of the project creation wizard |
| PROJECT_NEXT_BUTTON | - | the Next button on the second page of the project creation wizard |
| DP_PANEL | - | the Data Provider panel in the project creation wizard |
| DP_PANEL_BLOCK | - | the Data Provider panel block in the project creation wizard |
| DP_PANEL_ROW | - | a row in the Data Provider panel block in the project creation wizard |
| DP_PANEL_NEXT_BUTTON | - | the next button on the Data Provider page of the project creation wizard |
| CONFIRMATION_PANEL | - | the summary page of the project creation wizard |
| SUMMARY | - | the summary of parameters specified on the summary page of the project creation wizard |
| CONFIRMATION_PANEL_PARAMETERS | - | the project parameters in command line form |
| RUN_NEW_PROJECT_BUTTON | - | the Run button on the summary page of the project creation wizard |
If you do not find the selector for the element you want to highlight, you can use CUSTOM with your own JQuery selector as a parameter. You can use your browser's developer tools to inspect the web interface and extract the XPath of the element.
Advanced users can also expand on the list of available selectors, by overriding the default
list of selectors available in <SQUORE_HOME>/configuration/tutorials/aliasTuto.xml: Copy the file and place
it in the same relative location in your own configuration folder. You cannot create new actions,
but if an action exists for what you want to do, you can add your selector following the syntax:
<alias name="SELECTOR_ID" path="[JQuery selector with escaped ':' and '.']"/>
Table of Contents
Some configuration options are also available to tweak the Squore user interface.
These options need to be specified in a file called properties.xml located at
the root of your Configuration folder, or in various other Bundle.xml files.
This chapter describes these options and their effect on the user interface.
By default, the Explorer shows the following tabs for all users:

The default set of tabs in the Explorer, the tab displayed by default is the Dashboard tab.
Users can change the displayed tabs by clicking the Tab Manager icon right of the last tab. You can also define the
available tabs and their default state (shown, hidden, default) by editing properties.xml as shown below:
<!-- Active tabs --> <explorerTabs> <tab name="dashboard" default="true"/> <tab name="action-items" mandatory="true"/> <tab name="highlights"/> <tab name="findings"/> <tab name="reports" rendered="false"/> <tab name="attributes"/> <tab name="indicators" rendered="false"/> <tab name="measures" rendered="false"/> <tab name="annotations"/> </explorerTabs>
Each tab
element accepts the following parameters:
name
(mandatory) identifies the tab of the Explorer by name. The supported values are:
dashboard
action-items
highlights
findings
reports
attributes
indicators
measures
annotations
mandatory
(optional, default: false) removes the option to hide the tab from the web UI for all users.
default
(optional, default: false) makes the tab the default tab in Squore. Every link to a project or artefact that does not specifically request a target tab will open the Explorer with this tab active by default. Note that when set to true, the tab is automatically mandatory as well.
rendered
(optional, default: true) specifies whether the tab is shown (true) or hidden (false) by default. Hidden tabs can be shown by checking a box in the Tab Manager. Note that the value of this attribute is ignored if either default
or mandatory
is set to true.
You can use the help
option to add links that will appear in the Help menu in Squore
(? in the main toolbar), as shown below.
<?xml version="1.0" encoding="utf-8" standalone="yes"?>
<Bundle>
<!-- Customise the help links that appear in the right menu -->
<help label="OWASP 25" url="http://cwe.mitre.org/top25/" />
<help label="JBoss Wiki" url="http://www.jboss.org/jbosswiki"
profiles="ADMINISTRATOR;" />
</Bundle>The help
element accepts the following attributes:
A customised Help menu for a user with the ADMINISTRATOR profile.
If you wish to hide some of the models available in Squore, you can use the hideModel
option to prevent some folders under the models folder in the configuration from being read by
Squore, as shown below.
<?xml version="1.0" encoding="utf-8" standalone="yes"?> <Bundle> <!-- Hidden models --> <hideModel name="ISO9126_Maintainability_Xaml" /> </Bundle>
By default, Squore displays all versions of a project created with an earlier version of your model in orange.
The hideObsoleteModels
option allows disabling this behaviour, so that there is no warning
displayed for versions analysed with a different model.
<?xml version="1.0" encoding="utf-8" standalone="yes"?> <Bundle> <!-- Ignore model obsolescence (do not highlight versions analysed with an obsolete model) default=false --> <hideObsoleteModels value="true" /> </Bundle>
If it does not makes sense to display a specific measure in the Indicator Tree or the Model Viewer, you can hide it by editing the Properties bundle of a model. This is useful to remove confusion about how a measure is computed.
In order to hide a measure:
Edit the model's Properties/Bundle.xml.
Add a <hideMeasure targetArtefactTypes="" path="" > element.
Fill in the artefact types for which this measure is hidden (this is optional).
Specify the complete path of the measure to be hidden.
Below is an example of two hidden paths. The first one is only hidden at application level. The second one is always hidden.
configuration/models/[ModelFolder]/Properties/Bundle.xml:
<bundle> <!-- Hidden measures --> <hideMeasure targetArtefactTypes="APPLICATION" path="I.MAINTAINABILITY/I.ANALYSABILITY/I.FUANA_IDX" /> <hideMeasure path="I.MAINTAINABILITY/I.CHANGEABILITY/I.ROKR_CHAN/D.RKO_CHAN" /> </bundle>
Note that you should always use the precise notation path elements, with the I., B. or D. to avoid ambiguities.
Using the Properties bundle, you can define the list of categories available for edition in the Analysis Model Editor. By default,
all categories can be edited, but the rulesEdition
element allows you to explicitly limit the list to specific categories.
configuration/models/[ModelFolder]/Properties/Bundle.xml:
<Bundle> <!-- Restrict Analysis Model Editor categories to the list below --> <rulesEdition scales="CUSTOMER_SEVERITY;CUSTOMER_REMEDIATION;SCALE_SCHEDULE" /> </Bundle>
The rulesEdition
element takes a scale
attribute that acceps a semicolon-separated list
of scales to display for each rule in the Analysis Model Editor for this model.
You can define for each model the order that is used to sort items in the Action Items and Findings pages.
This is done by defining one or more scales and adding them to the Properties/Bundle.xml file using the
findingsTab
and actionItemsTab
options, as shown below:
configuration/models/[ModelFolder]/Properties/Bundle.xml: <bundle> <!-- sort order for columns --> <findingsTab orderBy="SCALE_PRIORITY;SCALE_SEVERITY" /> <actionItemsTab orderBy="SCALE_REMEDIATION;SCALE_SEVERITY" /> </bundle>
You can define for each model the columns that should be hidden in the Action Items and Findings pages.
This is done by defining one or more scales and adding them to the Properties/Bundle.xml file using the
findingsTab
and actionItemsTab
options, as shown below:
configuration/models/[ModelFolder]/Properties/Bundle.xml: <bundle> <!-- sort order for columns --> <findingsTab hideColumns="SCALE_PRIORITY;SCALE_SEVERITY" /> <actionItemsTab hideColumns="SCALE_REMEDIATION;SCALE_SEVERITY" /> </bundle>
The Findings tab can be customised to provide extra filters based on indicators in your model. You can see the difference in the filters available on the Findings tab in the images below:
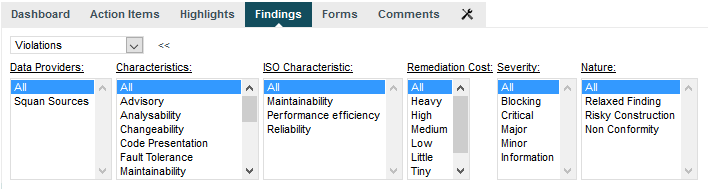
The default filters on the Findings tab

The Findings tab with advanced filters on the number of methods, test coverage and code stability index indicators
In order to configure the indicators that are used in the advanced filters, customise the Properties bundle for your model, as shown below:
configuration/models/[ModelFolder]/Properties/Bundle.xml: <bundle> <!-- Advanced Filtering --> <findingsTab artefactFilters="I.NOM;I.TEST_COVERAGE;I.SI" /> </bundle>
There are some limitations to what can be used for filtering:
The indicator used for filtering must use the same scale for all target artefact types.
Using an indicator that uses different measures for different artefact types can degrade performances.
If the indicator is not available for a type, all artefacts are filtered-out for this type.
If a finding involves multiple artefacts in different locations (e.g: cloning), both artefacts will always be shown if one of them matches the filter.
Squore uses a menus folder in its configuration so you can add functionality that will
be available in the user interface to run external tools. These external scripts are launched in Squore Server's context, and can
therefore benefit from Squore's authentication and permission mechanism. They are launched from the web interface via a Tools menu visible to the users whose profile grants access to the Use External Tools feature.
Each external tool is defined within its own sub-folder in menus and appears as a link in
the main Squore toolbar, as shown below:
A Tools menu containing an external tool to create a demo environment, and the associated page to configure and launch the script.
The menu in the image above was added using a form.xml and form_en.properties files.
Clicking the Execute button passes the user selections to a script called execute.tcl.
<SQUORE_HOME>/configuration/menus/CreateDemo/form.xml
<?xml version="1.0" encoding="UTF-8"?> <tags baseName="Generic" multiUsers="false" users="demo" groups="demo" image="earth.png"> <tag type="multipleChoice" key="demo" displayType="comboBox" defaultValue="TECH_DEBT"> <value key="ISO9126" /> <value key="RISK_INDEX_C" /> <value key="RISK_INDEX_JAVA" /> <value key="TECH_DEBT" /> </tag> <tag type="booleanChoice" key="create_users" defaultValue="false"/> <tag type="multipleChoice" key="useAccountCredentials" displayType="radioButton" defaultValue="USE_ACCOUNT_CREDENTIALS" credentialType="USE_ACCOUNT_CREDENTIALS"> <value key="NO_CREDENTIALS" /> <value key="USE_ACCOUNT_CREDENTIALS" /> <value key="PERSONAL_CREDENTIALS" /> </tag> <tag type="text" key="username" credentialType="LOGIN" /> <tag type="password" key="password" credentialType="PASSWORD" /> </tags>
<SQUORE_HOME>/configuration/menus/CreateDemo/form_en.properties
FORM.GENERAL.NAME=Create Demo FORM.GENERAL.DESCR=Menu to create sample projects for demo. FORM.GENERAL.URL=http://www.squoring.com/ TAG.demo.NAME=Demo: OPT.ISO9126C.NAME=ISO9126 -- C OPT.RISK_C.NAME=Risk Index -- C OPT.RISK_JAVA.NAME=Risk Index -- Java OPT.TD_JAVA.NAME=Technical Debt -- Java OPT.ISO9126.NAME=ISO9126 -- C OPT.RISK_INDEX_C.NAME=Risk Index -- C OPT.RISK_INDEX_JAVA.NAME=Risk Index -- Java OPT.TECH_DEBT.NAME=Technical Debt -- Java TAG.create_users.NAME=Create Demo Users TAG.useAccountCredentials.NAME= OPT.NO_CREDENTIALS.NAME=No credentials OPT.USE_ACCOUNT_CREDENTIALS.NAME=Use my Squore credentials OPT.PERSONAL_CREDENTIALS.NAME=Define credentials TAG.username.NAME=Username TAG.password.NAME=Password
<SQUORE_HOME>/configuration/menus/CreateDemo/execute.tcl
set create_users [set ${::toolName}::create_users]
set demo [set ${::toolName}::demo]
if {$create_users == "true"} {
create_user -name {Augustus Hill} -mail augustus.hill@domain.com -locale en augustus {1n/a5AsI5Rj6/m+MdX/tbCv9gSc=} [list admin users]
create_role HEAD_OF_DEPARTMENT
add_permission HEAD_OF_DEPARTMENT PROJECTS VIEW
}
switch $demo {
"ISO9126" {
#Earth
create_project --name=Earth "--versionDate=2016-01-14T01:00:00" --wizardId=ISO9126 --color=rgb(130,196,240) -t COST=60 -t BV=80 -r type=FROMPATH,path=$squore_home/samples/c/Earth/V1 -d type=SQuORE,languages=c
# Mars
create_project --subFoldersAsVersions=true --name=Mars "--versionDate=2016-01-17T01:00:00" --wizardId=ISO9126 --color=rgb(245,30,14) -t COST=50 -t BV=30 -r type=FROMPATH,path=$squore_home/samples/c/Mars -d type=SQuORE,languages=c
}
"RISK_INDEX_C" {
# Earth
create_project --name=rEarth --version=V1 "--versionDate=2016-01-14T01:00:00" --wizardId=RISK --color=rgb(130,196,240) -t COST=60 -t BV=80 -d type=CPPCheck,xml=$squore_home/samples/c/Earth/V1/cppcheck.xml -r type=FROMPATH,path=$squore_home/samples/c/Earth/V1
}
"RISK_INDEX_JAVA" {
create_project --name=rFreemind --version=0.9.0 "--versionDate=2013-06-15T01:00:00" --wizardId=RISK --color=rgb(130,196,240) -t COST=60 -t BV=80 -d type=CheckStyle,xml=$squore_home/samples/java/Freemind/0.9.0/checkstyle.xml -d type=PMD,xml=$squore_home/samples/java/Freemind/0.9.0/pmd.xml -r type=FROMPATH,path=$squore_home/samples/java/Freemind/0.9.0
}
"TECH_DEBT" {
create_project --password=augustus --teamUser=augustus,HEAD_OF_DEPARTMENT\;demo,HEAD_OF_DEPARTMENT --login=jenkins-bangalore --wizardId=TD --name=android-vlc-remote --version=0.5.3 -r type=FROMPATH,path=$squore_home/samples/java/android-vlc-remote/0.5.3/src "--versionDate=2013-06-15T01:00:00" -d type=CheckStyle,xml=$squore_home/samples/java/android-vlc-remote/0.5.3/checkstyle.xml -d type=PMD,xml=$squore_home/samples/java/android-vlc-remote/0.5.3/pmd.xml -t TEAMSIZE=6 -t IMPLEMENTED_REQ=75 -t PLANNED_REQ=100 -t AUJOURDHUI=2013/06/15 -t BASE_END_DATE=2013/10/30 -t ESTIMATED_DELAY=1 -t PERCENT_NEW_FEATURES=90 -t ELOC_PRODUCTIVITY_PER_DEV=20 -t PERCENT_MAINTENANCE=10 -t BV=50 -t COST=30 --color=rgb(214,23,205)
}
}The tags
element accepts the following attributes:
baseName
is the name of folder in Squore's addons folder that contains the executable tcl script. Set the value to Generic in order to
extend the generic framework that allows you to simply create users and projects.
multiUsers
defines whether only one running instance of the tool is allowed per user (true) or whether only one running instance at a time is allowed for the entire Squore Server (false).
users
: a semicolon-separated list of user logins. If specified, this
attribute limits the availability of the menu to the users explicitly listed.
groups
: a semicolon-separated list of user groups. If specified, this
attribute limits the availability of the menu to users belonging to the groups explicitly listed.
image
takes the path to an icon that is displayed next to the tool's name in the web interface
You can then add a series of tag
elements that follow the same specification as the one described in the section called “Attributes” to use as parameters on your custom page, with two extra types available:
decoration allows you to display an image followed by some text:
<tag type="decoration" image="custom-logo.png" style="width:500px"> This is the text that will be displayed next to the image. </tag>
file allows you choose a file to upload to the server:
<tag type="file" changeable="true" name="Upload this file: "
key="file" defaultValue="" acceptedTypes="xls,xlsx"/>The file is immediately uploaded on the server, and the TCL variable matching the specified key ($file
in the example above) is set to the absolute path of the uploaded file.
Consider the security implications of letting users upload arbitrary files to the server running Squore before using the file upload functionality.
Each tag
element accepts the attribute
required
(optional, default value: false), which allows marking the field as required and displays a red asterisk next to the field label.
The required
attribute is also valid in the form.xml files
you create for your custom Data Providers and Repository Connectors.
The following variables are injected in the script execute.tcl before execution:
outputDir: The directory associated with the menu.
tmpDir: The temporary directory associated with the menu
toolName: The name of the directory of the menu
toolBaseName: The name of the directory of the addons part of the menu
toolDir: The directory where the addons part of the menu can be found
toolkitDir: The directory where the Squore toolkit tcl scripts can be found
logFile: The name of the log file to use for displaying information
External Tools allow using several functions like create_project, which are covered in more details in Appendix B, External Tools Reference.
In models that integrate requirements, test cases or change requests as artefacts, it may be necessary to provide a link to view an artefact in the context of the application where it was created. This can be done in Squore by configuring the Source Code Viewer chart in the Dashboard to open links in an external applications. This section shows how you can configure external links using Jira as the target application.
Our model collects Jira issues and shows a minimal dashboard or the issue's status, assignee, priority, summary and description, as shown below:
The dashboard of a Jira issue in the Jenkins project
The Jira issue shown above is an artefact of type NEW_FEATURE. In order to
make the Source Code Viewer chart open the Jira issue in a browser, you simply need to create
a properties file in the sources folder of your configuration, whose name is the artefact type in
lower case.
<my_configuration_folder>/sources/new_feature.properties:
type=url
pattern=https://issues.jenkins-ci.org/browse/{0}
pattern.finding=https://issues.jenkins-ci.org/browse/{0}/activity?from={1}
p0=INFO(ISSUE_ID)
p1=INFO(ASSIGNEE)The syntax of this properties file is as follows:
type is the type of link to create. Only url is currently supported.
pattern is the URL pattern used to generate a link for the Source Code Viewer chart in the Dashboard. You are free to insert parameters in the URL as needed, as long as you declare them in the properties file.
pattern.findings is the URL pattern used to generate a link for artefacts on the Findings tab. This pattern also supports parameters.
p0, p1... pn are parameters that accept a computation that will return a string for the artefact. In the example above, ISSUE_ID and ASSIGNEE are two text metrics that exist for the NEW_FEATURE artefact type.
You can use the following computations:
INFO(measureId) to retrieve textual information from the current artefact
ARTEFACT_LOCATION() to retrieve the current artefact path
FINDING_LOCATION() to retrieve the precise location of the finding in the current artefact
Table of Contents
For more information on software engineering methods and metrics, you may check:
Jasper Reports home: jasperforge.org
iReport home: jasperforge.org/projects/ireport.
Reference Manual
Table of Contents
=======
= Csv =
=======
The Csv framework is used to import metrics or textual information and attach them to artefacts of type Application, File or Function. While parsing one or more input CSV files, if it finds the same metric for the same artefact several times, it will only use the last occurrence of the metric and ignore the previous ones. Note that the type of artefacts you can attach metrics to is limited to Application, File and Function artefacts. If you are working with File artefacts, you can let the Data Provider create the artefacts by itself if they do not exist already.
============
= form.xml =
============
You can customise form.xml to either:
- specify the path to a single CSV file to import
- specify a pattern to import all csv files matching this pattern in a directory
In order to import a single CSV file:
=====================================
<?xml version="1.0" encoding="UTF-8"?>
<tags baseName="Csv" needSources="true">
<tag type="text" key="csv" defaultValue="/path/to/mydata.csv" />
</tags>
Notes:
- The csv key is mandatory.
- Since Csv-based data providers commonly rely on artefacts created by Squan Sources, you can set the needSources attribute to force users to specify at least one repository connector when creating a project.
In order to import all files matching a pattern in a folder:
===========================================================
<?xml version="1.0" encoding="UTF-8"?>
<tags baseName="Csv" needSources="true">
<!-- Root directory containing Csv files to import-->
<tag type="text" key="dir" defaultValue="/path/to/mydata" />
<!-- Pattern that needs to be matched by a file name in order to import it-->
<tag type="text" key="ext" defaultValue="*.csv" />
<!-- search for files in sub-folders -->
<tag type="booleanChoice" defaultValue="true" key="sub" />
</tags>
Notes:
- The dir and ext keys are mandatory
- The sub key is optional (and its value set to false if not specified)
==============
= config.tcl =
==============
Sample config.tcl file:
=======================
# The separator used in the input CSV file
# Usually \t or ;
set Separator "\t"
# ArtefactLevel is one of:
# Application: to import data at application level
# File: to import data at file level. In this case ArtefactKey has to be set
# to the value of the header (key) of the column containing the file path
# in the input CSV file.
# Function : to import data at function level, in this case:
# ArtefactKey has to be set to the value of the header (key) of the column containing the path of the file
# FunctionKey has to be set to the value of the header (key) of the column containing the name and signature of the function
# Note that the values are case-sensitive.
set ArtefactLevel File
set ArtefactKey File
# The delimiter used in the input CSV file
# This is normally left empty, except when you know that some of the values in the CSV file
# contain the separator itself, for example:
# "A text containing ; the separator";no problem;end
# In this case, you need to set the delimiter to \" in order for the data provider to find 3 values instead of 4.
# To include the delimiter itself in a value, you need to escape it by duplicating it, for example:
# "A text containing "" the delimiter";no problemo;end
# Default: none
set ::Delimiter
# Should the File paths be case-insensitive?
# true or false (default)
# This is used when searching for a matching artefact in already-existing artefacts.
set PathsAreCaseInsensitive "false"
# Should file artefacts declared in the input CSV file be created automatically?
# true (default) or false
set CreateMissingFile "true"
# FileOrganisation defines the layout of the input CSV file and is one of:
# header::column: values are referenced from the column header
# header::line: NOT AVAILABLE
# alternate::line: lines are a sequence of {Key Value}
# alternate::column: columns are a sequence of {Key Value}
# There are more examples of possible CSV layouts later in this document
set FileOrganisation header::column
# Metric2Key contains a case-sensitive list of paired metric IDs:
# {MeasureID KeyName [Format]}
# where:
# - MeasureID is the id of the measure as defined in your analysis model
# - KeyName, depending on the FileOrganisation, is either the name of the column or the name
# in the cell preceding the value to import as found in the input CSV file
# - Format is the optional format of the data, the only accepted format
# is "text" to attach textual information to an artefact, for normal metrics omit this field
set Metric2Key {
{BRANCHES Branchs}
{VERSIONS Versions}
{CREATED Created}
{IDENTICAL Identical}
{ADDED Added}
{REMOV Removed}
{MODIF Modified}
{COMMENT Comment text}
}
==========================
= Sample CSV Input Files =
==========================
Example 1:
==========
FileOrganisation : header::column
ArtefactLevel : File
ArtefactKey : Path
Path Branchs Versions
./foo.c 15 105
./bar.c 12 58
Example 2:
==========
FileOrganisation : alternate::line
ArtefactLevel : File
ArtefactKey : Path
Path ./foo.c Branchs 15 Versions 105
Path ./bar.c Branchs 12 Versions 58
Example 3:
==========
FileOrganisation : header::column
ArtefactLevel : Application
ChangeRequest Corrected Open
27 15 11
Example 4:
==========
FileOrganisation : alternate::column
ArtefactLevel : Application
ChangeRequest 15
Corrected 11
Example 5:
==========
FileOrganisation : alternate::column
ArtefactLevel : File
ArtefactKey : Path
Path ./foo.c
Branchs 15
Versions 105
Path ./bar.c
Branchs 12
Versions 58
Example 6:
==========
FileOrganisation : header::column
ArtefactLevel : Function
ArtefactKey : Path
FunctionKey : Name
Path Name Decisions Tested
./foo.c end_game(int*,int*) 15 3
./bar.c bar(char) 12 6
Working With Paths:
===================
- Path seperators are unified: you do not need to worry about handling differences between Windows and Linux
- With the option PathsAreCaseInsensitive, case is ignored when searching for files in the Squore internal data
- Paths known by Squore are relative paths starting at the root of what was specified in the repository connector durign the analysis. This relative path is the one used to match with a path in a csv file.
Here is a valid example of file matching:
1. You provide C:\A\B\C\D as the root folder in a repository connector
2. C:\A\B\C\D contains E\e.c then Squore will know E/e.c as a file
3. You provide a csv file produced on linux and containing
/tmp/X/Y/E/e.c as path, then Squore will be able to match it with the known file.
Squore uses the longest possible match.
In case of conflict, no file is found and a message is sent to the log.
===========
= CsvPerl =
===========
The CsvPerl framework offers the same functionality as Csv, but instead of dealing with the raw input files directly, it allows you to run a perl script to modify them and produce a CSV file with the expected input format for the Csv framework.
============
= form.xml =
============
In your form.xml, specify the input parameters you need for your Data Provider.
Our example will use two parameters: a path to a CSV file and another text parameter:
<?xml version="1.0" encoding="UTF-8"?>
<tags baseName="CsvPerl" needSources="true">
<tag type="text" key="csv" defaultValue="/path/to/csv" />
<tag type="text" key="param" defaultValue="MyValue" />
</tags>
- Since Csv-based data providers commonly rely on artefacts created by Squan Sources, you can set the needSources attribute to force users to specify at least one repository connector when creating a project.
==============
= config.tcl =
==============
Refer to the description of config.tcl for the Csv framework.
For CsvPerl one more option is possible:
# The variable NeedSources is used to request the perl script to be executed once for each
# repository node of the project. In that case an additional parameter is sent to the
# perl script (see below for its position)
#set ::NeedSources 1
==========================
= Sample CSV Input Files =
==========================
Refer to the examples for the Csv framework.
===============
= Perl Script =
===============
The perl scipt will receive as arguments:
- all parameters defined in form.xml (as -${key} $value)
- the input directory to process (only if ::NeedSources is set to 1 in the config.tcl file)
- the location of the output directory where temporary files can be generated
- the full path of the csv file to be generated
For the form.xml we created earlier in this document, the command line will be:
perl <configuration_folder>/tools/CustomDP/CustomDP.pl -csv /path/to/csv -param MyValue <output_folder> <output_folder>/CustomDP.csv
Example of perl script:
======================
#!/usr/bin/perl
use strict;
use warnings;
$|=1 ;
($csvKey, $csvValue, $paramKey, $paramValue, $output_folder, $output_csv) = @ARGV;
# Parse input CSV file
# ...
# Write results to CSV
open(CSVFILE, ">" . ${output_csv}) || die "perl: can not write: $!\n";
binmode(CSVFILE, ":utf8");
print CSVFILE "ChangeRequest;15";
close CSVFILE;
exit 0;===========
= Generic =
===========
The Generic framework is the most flexible Data Provider framework, since it allows attaching metrics, findings, textual information and links to artefacts. If the artefacts do not exist in your project, they will be created automatically. It takes one or more CSV files as input (one per type of information you want to import) and works with any type of artefact.
============
= form.xml =
============
In form.xml, allow users to specify the path to a CSV file for each type of data you want to import.
You can set needSources to true or false, depending on whether or not you want to require the use of a repository connector when your custom Data Provider is used.
Example of form.xml file:
=========================
<?xml version="1.0" encoding="UTF-8"?>
<tags baseName="Generic" needSources="false">
<!-- Path to CSV file containing Metrics data -->
<tag type="text" key="csv" defaultValue="mydata.csv" />
<!-- Path to CSV file containing Findings data: -->
<tag type="text" key="fdg" defaultValue="mydata_fdg.csv" />
<!-- Path to CSV file containing Information data: -->
<tag type="text" key="inf" defaultValue="mydata_inf.csv" />
<!-- Path to CSV file containing Links data: -->
<tag type="text" key="lnk" defaultValue="mydata_lnk.csv" />
</tags>
Note: All tags are optional. You only need to specify the tag element for the type of data you want to import with your custom Data Provider.
==============
= config.tcl =
==============
Sample config.tcl file:
=======================
# The separator used in the input csv files
# Usually \t or ; or ,
# In our example below, a space is used.
set Separator " "
# The path separator in an artefact's path
# in the input CSV file.
# Note that artefact is spellt with an "i"
# and not an "e" in this option.
set ArtifactPathSeparator "/"
# If the data provider needs to specify a different toolName (optional)
set SpecifyToolName 1
# Metric2Key contains a case-sensitive list of paired metric IDs:
# {MeasureID KeyName [Format]}
# where:
# - MeasureID is the id of the measure as defined in your analysis model
# - KeyName is the name in the cell preceding the value to import as found in the input CSV file
# - Format is the optional format of the data, the only accepted format
# is "text" to attach textual information to an artefact. Note that the same result can also
# be achieved with Info2Key (see below). For normal metrics omit this field.
set Metric2Key {
{CHANGES Changed}
}
# Finding2Key contains a case-sensitive list of paired rule IDs:
# {FindingID KeyName}
# where:
# - FindingID is the id of the rule as defined in your analysis model
# - KeyName is the name in the finding name in the input CSV file
set Finding2Key {
{R_NOTLINKED NotLinked}
}
# Info2Key contains a case-sensitive list of paired info IDs:
# {InfoID KeyName}
# where:
# - InfoID is the id of the textual information as defiend in your analysis model
# - KeyName is the name of the information name in the input CSV file
set Info2Key
{SPECIAL_LABEL Label}
}
# Ignore findings for artefacts that are not part of the project (orphan findings)
# When set to 1, the findings are ignored
# When set to 0, the findings are imported and attached to the APPLICATION node
# (default: 1)
set IgnoreIfArtefactNotFound 1
# For findings of a type that is not in your ruleset, set a default rule ID.
# The value for this parameter must be a valid rule ID from your analysys model.
# (default: empty)
set UnknownRuleId UNKNOWN_RULE
# Save the total count of orphan findings as a metric at application level
# Specify the ID of the metric to use in your analysys model
# to store the information
# (default: empty)
set OrphanArteCountId NB_ORPHANS
# Save the total count of unknown rules as a metric at application level
# Specify the ID of the metric to use in your analysys model
# to store the information
# (default: empty)
set OrphanRulesCountId NB_UNKNOWN_RULES
# Save the list of unknown rule IDs as textual information at application level
# Specify the ID of the metric to use in your analysys model
# to store the information
# (default: empty)
set OrphanRulesListId UNKNOWN_RULES_INFO
====================
= CSV File Format =
====================
All the examples listed below assume the use of the following config.tcl:
set Separator ","
set ArtifactPathSeparator "/"
set Metric2Key {
{CHANGES Changed}
}
set Finding2Key {
{R_NOTLINKED NotLinked}
}
set Info2Key
{SPECIAL_LABEL Label}
}
Layout for Metrics File:
========================
==> artefact_type artefact_path (Key Value)*
When the parent artefact type is not given it defaults to <artefact_type>_FOLDER.
Example:
REQ_MODULE,Requirements/Module
REQUIREMENT,Requirements/Module/My_Req,Changed,1
will produce the following artefact tree:
Application
Requirements (type: REQ_MODULE_FOLDER)
Module (type: REQ_MODULE)
My_Req : (type: REQUIREMENT) with 1 metric CHANGES = 1
Note: the key "Changed" is mapped to the metric "CHANGES", as specified by the Metric2Key parameter, so that it matches what is expected by the model.
Layout for Findings File:
=========================
==> artefact_type artefact_path key message
When the parent artefact type is not given it defaults to <artefact_type>_FOLDER.
Example:
REQ_MODULE,Requirements/Module
REQUIREMENT,Requirements/Module/My_Req,NotLinked,A Requiremement should always been linked
will produce the following artefact tree:
Application
Requirements (type: REQ_MODULE_FOLDER)
Module (type: REQ_MODULE)
My_Req (type: REQUIREMENT) with 1 finding R_NOTLINKED whose description is "A Requiremement should always been linked"
Note: the key "NotLinked" is mapped to the finding "R_NOTLINKED", as specified by the Finding2Key parameter, so that it matches what is expected by the model.
Layout for Textual Information File:
====================================
==> artefact_type artefact_path label value
When the parent artefact type is not given it defaults to <artefact_type>_FOLDER.
Example:
REQ_MODULE,Requirements/Module
REQUIREMENT,Requirements/Module/My_Req,Label,This is the label of the req
will produce the following artefact tree:
Application
Requirements (type: REQ_MODULE_FOLDER)
Module (type: REQ_MODULE)
My_Req (type: REQUIREMENT) with 1 information of type SPECIAL_LABEL whose content is "This is the label of the req"
Note: the label "Label" is mapped to the finding "SPECIAL_LABEL", as specified by the Info2Key parameter, so that it matches what is expected by the model.
Layout for Links File:
======================
==> artefact_type artefact_path dest_artefact_type dest_artefact_path link_type
When the parent artefact type is not given it defaults to <artefact_type>_FOLDER
Example:
REQ_MODULE Requirements/Module
TEST_MODULE Tests/Module
REQUIREMENT Requirements/Module/My_Req TEST Tests/Module/My_test TESTED_BY
will produce the following artefact tree:
Application
Requirements (type: REQ_MODULE_FOLDER)
Module (type: REQ_MODULE)
My_Req (type: REQUIREMENT) ------>
Tests (type: TEST_MODULE_FOLDER) |
Module (type: TEST_MODULE) |
My_Test (type: TEST) <------------+ link (type: TESTED_BY)
The TESTED_BY relationship is created with My_Req as source of the link and My_test as the destination
CSV file organisation when SpecifyToolName is set to 1
======================================================
When the variable SpecifyToolName is set to 1 (or true) a column has to be added
at the beginning of each line in each csv file. This column can be empty or filled with a different toolName.
Example:
,REQ_MODULE,Requirements/Module
MyReqChecker,REQUIREMENT,Requirements/Module/My_Req Label,This is the label of the req
The finding of type Label will be set as reported by the tool "MyReqChecker".===============
= GenericPerl =
===============
The GenericPerl framework is an extension of the Generic framework that starts by running a perl script in order to generate the metrics, findings, information and links files. It is useful if you have an input file whose format needs to be converted to match the one expected by the Generic framework, or if you need to retrieve and modify information exported from a web service on your network.
============
= form.xml =
============
In your form.xml, specify the input parameters you need for your Data Provider.
Our example will use two parameters: a path to a CSV file and another text parameter:
<?xml version="1.0" encoding="UTF-8"?>
<tags baseName="CsvPerl" needSources="false">
<tag type="text" key="csv" defaultValue="/path/to/csv" />
<tag type="text" key="param" defaultValue="MyValue" />
</tags>
==============
= config.tcl =
==============
Refer to the description of config.tcl for the Generic framework for the basic options.
Additionally, the following options are available for the GenericPerl framework, in order to know which type of information your custom Data Provider should try to import.
# If the data provider needs to specify a different toolName (optional)
#set SpecifyToolName 1
# Set to 1 to import metrics csv file, 0 otherwise
# ImportMetrics
# When set to 1, your custom Data Provider (CustomDP) will try to import
# metrics from a file called CustomDP.mtr.csv that your perl script
# should generate according to the expected format described in the
# documentation of the Generic framework.
set ImportMetrics 1
# ImportInfos
# When set to 1, your custom Data Provider (CustomDP) will try to import
# textual information from a file called CustomDP.inf.csv that your perl script
# should generate according to the expected format described in the
# documentation of the Generic framework.
set ImportInfos 0
# ImportFindings
# When set to 1, your custom Data Provider (CustomDP) will try to import
# findings from a file called CustomDP.fdg.csv that your perl script
# should generate according to the expected format described in the
# documentation of the Generic framework.
set ImportFindings 1
# ImportLinks
# When set to 1, your custom Data Provider (CustomDP) will try to import
# artefact links from a file called CustomDP.lnk.csv that your perl script
# should generate according to the expected format described in the
# documentation of the Generic framework.
set ImportLinks 0
# Ignore findings for artefacts that are not part of the project (orphan findings)
# When set to 1, the findings are ignored
# When set to 0, the findings are imported and attached to the APPLICATION node
# (default: 1)
set IgnoreIfArtefactNotFound 1
# For findings of a type that is not in your ruleset, set a default rule ID.
# The value for this parameter must be a valid rule ID from your analysys model.
# (default: empty)
set UnknownRuleId UNKNOWN_RULE
# Save the total count of orphan findings as a metric at application level
# Specify the ID of the metric to use in your analysys model
# to store the information
# (default: empty)
set OrphanArteCountId NB_ORPHANS
# Save the total count of unknown rules as a metric at application level
# Specify the ID of the metric to use in your analysys model
# to store the information
# (default: empty)
set OrphanRulesCountId NB_UNKNOWN_RULES
# Save the list of unknown rule IDs as textual information at application level
# Specify the ID of the metric to use in your analysys model
# to store the information
# (default: empty)
set OrphanRulesListId UNKNOWN_RULES_INFO
====================
= CSV File Format =
====================
Refer to the examples in the Generic framework.
===============
= Perl Script =
===============
The perl scipt will receive as arguments:
- all parameters defined in form.xml (as -${key} $value)
- the location of the output directory where temporary files can be generated
- the full path of the metric csv file to be generated (if ImportMetrics is set to 1 in config.tcl)
- the full path of the findings csv file to be generated (if ImportFindings is set to 1 in config.tcl)
- the full path of the textual information csv file to be generated (if ImportInfos is set to 1 in config.tcl)
- the full path of the links csv file to be generated (if ImportLinks is set to 1 in config.tcl)
- the full path to the output directory used by this data provider in the previous analysis
For the form.xml and config.tcl we created earlier in this document, the command line will be:
perl <configuration_folder>/tools/CustomDP/CustomDP.pl -csv /path/to/csv -param MyValue <output_folder> <output_folder>/CustomDP.mtr.csv <output_folder>/CustomDP.fdg.csv <previous_output_folder>
Example of perl script:
======================
#!/usr/bin/perl
use strict;
use warnings;
$|=1 ;
($csvKey, $csvValue, $paramKey, $paramValue, $output_folder, $output_metrics_csv, $output_findings_csv, $prev_data_dir) = @ARGV;
# Parse input CSV file
# ...
# Write metrics to CSV
open(METRICS_FILE, ">" . ${output_metrics_csv}) || die "perl: can not write: $!\n";
binmode(METRICS_FILE, ":utf8");
print METRICS_FILE "REQUIREMENTS;Requirements/All_Requirements;NB_REQ;15";
close METRICS_FILE;
# Write findings to CSV
open(FINDINGS_FILE, ">" . ${output_findings_csv}) || die "perl: can not write: $!\n";
binmode(FINDINGS_FILE, ":utf8");
print FINDINGS_FILE "REQUIREMENTS;Requirements/All_Requirements;R_LOW_REQS;\"The minimum number of requirement should be at least 25.\"";
close FINDINGS_FILE;
exit 0;================
= FindingsPerl =
================
The FindingsPerl framework is used to import findings and attach them to existing artefacts. Optionally, if an artefact cannot be found in your project, the finding can be attached to the root node of the project instead. When launching a Data Provider based on the FindingsPerl framework, a perl script is run first. This perl script is used to generate a CSV file with the expected format which will then be parsed by the framework.
============
= form.xml =
============
In your form.xml, specify the input parameters you need for your Data Provider.
Our example will use two parameters: a path to a CSV file and another text parameter:
<?xml version="1.0" encoding="UTF-8"?>
<tags baseName="CsvPerl" needSources="true">
<tag type="text" key="csv" defaultValue="/path/to/csv" />
<tag type="text" key="param" defaultValue="MyValue" />
</tags>
- Since FindingsPerl-based data providers commonly rely on artefacts created by Squan Sources, you can set the needSources attribute to force users to specify at least one repository connector when creating a project.
==============
= config.tcl =
==============
Sample config.tcl file:
=======================
# The separator to be used in the generated CSV file
# Usually \t or ;
set Separator ";"
# Should the perl script execcuted once for each repository node of the project ?
# 1 or 0 (default)
# If true an additional parameter is sent to the
# perl script (see below for its position)
set ::NeedSources 0
# Should the violated rules definitions be generated?
# true or false (default)
# This creates a ruleset file with rules that are not already
# part of your analysis model so you can review it and add
# the rules manually if needed.
set generateRulesDefinitions false
# Should the File paths be case-insensitive?
# true or false (default)
# This is used when searching for a matching artefact in already-existing artefacts.
set PathsAreCaseInsensitive false
# Should file artefacts declared in the input CSV file be created automatically?
# true (default) or false
set CreateMissingFile true
# Ignore findings for artefacts that are not part of the project (orphan findings)
# When set to 0, the findings are imported and attached to the APPLICATION node instead of the real artefact
# When set to 1, the findings are not imported at all
# (default: 0)
set IgnoreIfArtefactNotFound 0
# For findings of a type that is not in your ruleset, set a default rule ID.
# The value for this parameter must be a valid rule ID from your analysis model.
# (default: empty)
set UnknownRuleId UNKNOWN_RULE
# Save the total count of orphan findings as a metric at application level
# Specify the ID of the metric to use in your analysys model
# to store the information
# (default: empty)
set OrphanArteCountId NB_ORPHANS
# Save the total count of unknown rules as a metric at application level
# Specify the ID of the metric to use in your analysys model
# to store the information
# (default: empty)
set OrphanRulesCountId NB_UNKNOWN_RULES
# Save the list of unknown rule IDs as textual information at application level
# Specify the ID of the metric to use in your analysys model
# to store the information
# (default: empty)
set OrphanRulesListId UNKNOWN_RULES_INFO
# The tool version to specify in the generated rules definitions
# The default value is ""
# Note that the toolName is the name of the folder you created
# for your custom Data Provider
set ToolVersion ""
# FileOrganisation defines the layout of the CSV file that is produced by your perl script:
# header::column: values are referenced from the column header
# header::line: NOT AVAILABLE
# alternate::line: NOT AVAILABLE
# alternate::column: NOT AVAILABLE
set FileOrganisation header::column
# In order to attach a finding to an artefact of type FILE:
# - Tool (optional) if present it overrides the name of the tool providing the finding
# - Path has to be the path of the file
# - Type has to be set to FILE
# - Line can be either empty or the line in the file where the finding is located
# Rule is the rule identifier, can be used as is or translated using Rule2Key
# Descr is the description message, which can be empty
#
# In order to attach a finding to an artefact of type FUNCTION:
# - Tool (optional) if present it overrides the name of the tool providing the finding
# - Path has to be the path of the file containing the function
# - Type has to be FUNCTION
# - If line is an integer, the system will try to find an artefact function
# at the given line of the file
# - If no Line or Line is not an integer, Name is used to find an artefact in
# the given file having name and signature as found in this column.
# (Line and Name are optional columns)
# Rule2Key contains a case-sensitive list of paired rule IDs:
# {RuleID KeyName}
# where:
# - RuleID is the id of the rule as defined in your analysis model
# - KeyName is the rule ID as written by your perl script in the produced CSV file
# Note: Rules that are not mapped keep their original name. The list of unmapped rules is in the log file generated by your Data Provider.
set Rule2Key {
{ ExtractedRuleID_1 MappedRuleId_1 }
{ ExtractedRuleID_2 MappedRuleId_2 }
}
====================
= CSV File Format =
====================
According to the options defined earlier in config.tcl, a valid csv file would be:
Path;Type;Line;Name;Rule;Descr
/src/project/module1/f1.c;FILE;12;;R1;Rule R1 is violated because variable v1
/src/project/module1/f1.c;FUNCTION;202;;R4;Rule R4 is violated because function f1
/src/project/module2/f2.c;FUNCTION;42;;R1;Rule R1 is violated because variable v2
/src/project/module2/f2.c;FUNCTION;;skip_line(int);R1;Rule R1 is violated because variable v2
Working With Paths:
===================
- Path seperators are unified: you do not need to worry about handling differences between Windows and Linux
- With the option PathsAreCaseInsensitive, case is ignored when searching for files in the Squore internal data
- Paths known by Squore are relative paths starting at the root of what was specified in the repository connector durign the analysis. This relative path is the one used to match with a path in a csv file.
Here is a valid example of file matching:
1. You provide C:\A\B\C\D as the root folder in a repository connector
2. C:\A\B\C\D contains E\e.c then Squore will know E/e.c as a file
3. You provide a csv file produced on linux and containing
/tmp/X/Y/E/e.c as path, then Squore will be able to match it with the known file.
Squore uses the longest possible match.
In case of conflict, no file is found and a message is sent to the log.
===============
= Perl Script =
===============
The perl scipt will receive as arguments:
- all parameters defined in form.xml (as -${key} $value)
- the input directory to process (only if ::NeedSources is set to 1)
- the location of the output directory where temporary files can be generated
- the full path of the findings csv file to be generated
For the form.xml and config.tcl we created earlier in this document, the command line will be:
perl <configuration_folder>/tools/CustomDP/CustomDP.pl -csv /path/to/csv -param MyValue <output_folder> <output_folder>/CustomDP.fdg.csv <output_folder>/CustomDP.fdg.csv
Example of perl script:
======================
#!/usr/bin/perl
use strict;
use warnings;
$|=1 ;
($csvKey, $csvValue, $paramKey, $paramValue, $output_folder, $output_csv) = @ARGV;
# Parse input CSV file
# ...
# Write results to CSV
open(CSVFILE, ">" . ${output_csv}) || die "perl: can not write: $!\n";
binmode(CSVFILE, ":utf8");
print CSVFILE "Path;Type;Line;Name;Rule;Descr";
print CSVFILE "/src/project/module1/f1.c;FILE;12;;R1;Rule R1 is violated because variable v1";
close CSVFILE;
exit 0;================
= ExcelMetrics =
================
The ExcelMetrics framework is used to extract information from one or more Microsoft Excel files (.xls or .xslx). A detailed configuration file allows defining how the Excel document should be read and what information should be extracted. This framework allows importing metrics, findings and textual information to existing artefacts or artefacts that will be created by the Data Provider.
============
= form.xml =
============
You can customise form.xml to either:
- specify the path to a single Excel file to import
- specify a pattern to import all Excel files matching this pattern in a directory
In order to import a single Excel file:
=====================================
<?xml version="1.0" encoding="UTF-8"?>
<tags baseName="ExcelMetrics" needSources="false">
<tag type="text" key="excel" defaultValue="/path/to/mydata.xslx" />
</tags>
Notes:
- The excel key is mandatory.
In order to import all files matching a patter in a folder:
===========================================================
<?xml version="1.0" encoding="UTF-8"?>
<tags baseName="ExcelMetrics" needSources="false">
<!-- Root directory containing Excel files to import-->
<tag type="text" key="dir" defaultValue="/path/to/mydata" />
<!-- Pattern that needs to be matched by a file name in order to import it-->
<tag type="text" key="ext" defaultValue="*.xlsx" />
<!-- search for files in sub-folders -->
<tag type="booleanChoice" defaultValue="true" key="sub" />
</tags>
Notes:
- The dir and ext keys are mandatory
- The sub key is optional (and its value set to false if not specified)
==============
= config.tcl =
==============
Sample config.tcl file:
=======================
# The separator to be used in the generated csv file
# Usually \t or ; or ,
set Separator ";"
# The path separator in an artefact's path
# in the generated CSV file.
set ArtefactPathSeparator "/"
# Ignore findings for artefacts that are not part of the project (orphan findings)
# When set to 1, the findings are ignored
# When set to 0, the findings are imported and attached to the APPLICATION node
# (default: 1)
set IgnoreIfArtefactNotFound 1
# For findings of a type that is not in your ruleset, set a default rule ID.
# The value for this parameter must be a valid rule ID from your analysys model.
# (default: empty)
set UnknownRuleId UNKNOWN_RULE
# Save the total count of orphan findings as a metric at application level
# Specify the ID of the metric to use in your analysys model
# to store the information
# (default: empty)
set OrphanArteCountId NB_ORPHANS
# Save the total count of unknown rules as a metric at application level
# Specify the ID of the metric to use in your analysys model
# to store the information
# (default: empty)
set OrphanRulesCountId NB_UNKNOWN_RULES
# Save the list of unknown rule IDs as textual information at application level
# Specify the ID of the metric to use in your analysys model
# to store the information
# (default: empty)
set OrphanRulesListId UNKNOWN_RULES_INFO
# The list of the Excel sheets to read, each sheet has the number of the first line to read
# A Perl regexp pattern can be used instead of the name of the sheet (the first sheet matching
# the pattern will be considered)
set Sheets {{Baselines 5} {ChangeNotes 5}}
# ######################
# # COMMON DEFINITIONS #
# ######################
#
# - <value> is a list of column specifications whose values will be concatened. When no column name is present, the
# text is taken as it appears. Optional sheet name can be added (with ! char to separate from the column name)
# Examples:
# - {C:} the value will be the value in column C on the current row
# - {C: B:} the value will be the concatenation of values found in column C and B of the current row
# - {Deliveries} the value will be Deliveries
# - {BJ: " - " BL:} the value will be the concatenation of value found in column BJ,
# string " - " and the value found in column BL fo the current row
# - {OtherSheet!C:} the value will be the value in column C from the sheet OtherSheet on the current row
#
# - <condition> is a list of conditions. An empty condition is always true. A condition is a column name followed by colon,
# optionally followed by a perl regexp. Optional sheet name can be added (with ! char to separate from the column name)
# Examples:
# - {B:} the value in column B must be empty on the current row
# - {B:.+} the value in column B can not be empty on the current row
# - {B:R_.+} the value in column B is a word starting by R_ on the current row
# - {A: B:.+ C:R_.+} the value in column A must be empty and the value in column B must contain something and
# the column C contains a word starting with R_ on the current row
# - {OtherSheet!B:.+} the value in column B from sheet OtherSheet on the current row can not be empty.
# #############
# # ARTEFACTS #
# #############
# The variable is a list of artefact hierarchy specification:
# {ArtefactHierarchySpec1 ArtefactHierarchySpec2 ... ArtefactHierarchySpecN}
# where each ArtefactHierarchySpecx is a list of ArtefactSpec
#
# An ArtefactSpec is a list of items, each item being:
# {<(sheetName!)?artefactType> <conditions> <name> <parentType>? <parentName>?}
# where:
# - <(sheetName!)?artefactType>: allows specifying the type. Optional sheetName can be added (with ! char to separate from the type) to limit
# the artefact search in one specific sheet. When Sheets are given with regexp, the same regexp has to be used
# for the sheetName.
# If the type is followed by a question mark (?), this level of artefact is optional.
# If the type is followed by a plus char (+), this level is repeatable on the next row
# - <condition>: see COMMON DEFINITIONS
# - <value>: the name of the artefact to build, see COMMON DEFINITIONS
#
# - <parentType>: This element is optional. When present, it means that the current element will be attached to a parent having this type
# - <parentValue>: This is a list like <value> to build the name of the artefact of type <parentType>. If such artefact is not found,
# the current artefact does not match
#
# Note: to add metrics at application level, specify an APPLICATION artefact which will match only one line:
# e.g. {APPLICATION {A:.+} {}} will recognize as application the line having column A not empty.
set ArtefactsSpecs {
{
{DELIVERY {} {Deliveries}}
{RELEASE {E:.+} {E:}}
{SPRINT {O:SW_Software} {Q:}}
}
{
{DELIVERY {} {Deliveries}}
{RELEASE {O:SY_System} {Q:}}
}
{
{WP {BL:.+ AF:.+} {BJ: " - " BL:} SPRINT {AF:}}
{ChangeNotes!TASK {D:(added|changed|unchanged) T:imes} {W: AD:}}
}
{
{WP {} {{Unplanned imes}} SPRINT {AF:}}
{TASK {BL: D:(added|changed|unchanged) T:imes W:.+} {W: AD:}}
}
}
# ###########
# # METRICS #
# ###########
# Specification of metrics to be retreived
# This is a list where each element is:
# {<artefactTypeList> <metricId> <condition> <value> <format>}
# Where:
# - <artefactTypeList>: the list of artefact types for which the metric has to be used
# each element of the list is (sheetName!)?artefactType where sheetName is used
# to restrict search to only one sheet. sheetName is optional.
# - <metricId>: the name of the MeasureId to be injected into Squore, as defined in your analysis model
# - <confition>: see COMMON DEFINITIONS above. This is the condition for the metric to be generated.
# - <value> : see COMMON DEFINITIONS above. This is the value for the metric (can be built from multi column)
# - <format> : optional, defaults to NUMBER
# Possible format are:
# * DATE_FR, DATE_EN for date stored as string
# * DATE for cell formatted as date
# * NUMBER_FR, NUMBER_EN for number stored as string
# * NUMBER for cell formatted as number
# * LINES for counting the number of text lines in a cell
# - <formatPattern> : optional
# Only used by the LINES format.
# This is a pattern (can contain perl regexp) used to filter lines to count
set MetricsSpecs {
{{RELEASE SPRINT} TIMESTAMP {} {A:} DATE_EN}
{{RELEASE SPRINT} DATE_ACTUAL_RELEASE {} {S:} DATE_EN}
{{RELEASE SPRINT} DATE_FINISH {} {T:} DATE_EN}
{{RELEASE SPRINT} DELIVERY_STATUS {} {U:}}
{{WP} WP_STATUS {} {BO:}}
{{ChangeNotes!TASK} IS_UNPLAN {} {BL:}}
{{TASK WP} DATE_LABEL {} {BP:} DATE_EN}
{{TASK WP} DATE_INTEG_PLAN {} {BD:} DATE_EN}
{{TASK} TASK_STATUS {} {AE:}}
{{TASK} TASK_TYPE {} {AB:}}
}
# ############
# # FINDINGS #
# ############
# This is a list where each element is:
# {<artefactTypeList> <findingId> <condition> <value> <localisation>}
# Where:
# - <artefactTypeList>: the list of artefact type for which the metric has to be used
# each element of the list is (sheetName!)?artefactType where sheetName is used
# to restrict search to only one sheet. sheetName is optional.
# - <findingId>: the name of the FindingId to be injected into Squore, as defined in your analysis model
# - <confition>: see COMMON DEFINITIONS above. This is the condition for the finding to be triggered.
# - <value>: see COMMON DEFINITIONS above. This is the value for the message of the finding (can be built from multi column)
# - <localisation>: this a <value> representing the localisation of the finding (free text)
set FindingsSpecs {
{{WP} {BAD_WP} {BL:.+ AF:.+} {{This WP is not in a correct state } AF:.+} {A:}}
}
# #######################
# # TEXTUAL INFORMATION #
# #######################
# This is a list where each element is:
# {<artefactTypeList> <infoId> <condition> <value>}
# Where:
# - <artefactTypeList> the list of artefact types for which the info has to be used
# each element of the list is (sheetName!)?artefactType where sheetName is used
# to restrict search to only one sheet. sheetName is optional.
# - <infoId> : is the name of the Information to be attached to the artefact, as defined in your analysis model
# - <confition> : see COMMON DEFINITIONS above. This is the condition for the info to be generated.
# - <value> : see COMMON DEFINITIONS above. This is the value for the info (can be built from multi column)
set InfosSpecs {
{{TASK} ASSIGN_TO {} {XB:}}
}
# ########################
# # LABEL TRANSFORMATION #
# ########################
# This is a list value specification for MeasureId or InfoId:
# <MeasureId|InfoId> { {<LABEL1> <value1>} ... {<LABELn> <valuen>}}
# Where:
# - <MeasureId|InfoId> : is either a MeasureId, an InfoId, or * if it is available for every measureid/infoid
# - <LABELx> : is the label to macth (can contain perl regexp)
# - <valuex> : is the value to replace the label by, it has to match the correct format for the metrics (no format for infoid)
#
# Note: only metrics which are labels in the excel file or information which need to be rewriten, need to be described here.
set Label2ValueSpec {
{
STATUS {
{OPENED 0}
{ANALYZED 1}
{CLOSED 2}
{.* -1}
}
}
{
* {
{FATAL 0}
{ERROR 1}
{WARNING 2}
{{LEVEL:\s*0} 1}
{{LEVEL:\s*1} 2}
{{LEVEL:\s*[2-9]+} 3}
}
}
}
Note that a sample Excel file with its associated config.tcl is available in $SQUORE_HOME/addons/tools/ExcelMetrics in order to further explain available configuration options.Table of Contents
For more information about External Tools, consult the section called “External Tools”.
=========================
= Generic External Tool =
=========================
This default external tool provides a basic framework for creating users, groups, roles, profiles and projects.
In order to create an external tool based on this Generic tool, you need to create 4 files:
- config.tcl (optional) allows to override default options
- form.xml, with a baseName="Generic" attribute
- form_en.properties, where you externalise the strings displayed in the user interface (and optionally a form_fr.properties file where you translate those strings)
- execute.tcl, where you get the variables defined in form.xml and config.tcl and run your script
==============
= config.tcl =
==============
The contents of this file overrides default values, for the variable jar, commands and url:
set jar "$squore_home/client/squore-engine.jar"
set commands "DELEGATE_CREATION"
set url "http://[server]:[port]/SQuORE_Server" #dynamically obtained from the server installation
If the above default values are OK, you do not need a config.tcl file.
============
= form.xml =
============
This file is like any other form.xml, but will have to contain the credential part if the create_project pro is called.
===============
= execute.tcl =
===============
This file is normal tcl file. The following proc are predefined:
* read_err msg: sends a message to the log flagged as an error
* read_out msg: sends a message to the log flagged as an info
* create_project args: creates a project.
The following arguments are automatically set and should not be passed to create_projet:
-Dsquore.home.dir
-jar
--url
--commands
--login
--password
The proc returns 1 in case of success and 0 otherwise.
* create_group name ?profiles?
* create_user [-name user_name] [-mail email] [-locale locale] login password ?groups? ?profiles?
* create_profile name
* create_role name
* add_permission name target action
==================
= Example Script =
==================
# set "demo" as password
set pwd {ieSV55Qc+eQOaYDRSha/AjzNTJE=}
create_user -name {Augustus Hill} -mail augustus.hill@domain.com -locale en augustus $pwd [list admin users]
create_role HEAD_OF_DEPARTMENT
add_permission HEAD_OF_DEPARTMENT PROJECTS VIEW
add_permission HEAD_OF_DEPARTMENT PROJECTS MANAGE
add_permission HEAD_OF_DEPARTMENT PROJECTS BASELINE
add_permission HEAD_OF_DEPARTMENT PROJECTS VIEW_DRAFTS
add_permission HEAD_OF_DEPARTMENT ACTION_ITEMS MODIFY
add_permission HEAD_OF_DEPARTMENT ATTRIBUTES MODIFY
add_permission HEAD_OF_DEPARTMENT SOURCE_CODE VIEW
add_permission HEAD_OF_DEPARTMENT ARTEFACTS MODIFY
create_project --name=Earth --wizardId=RISK -r type=FROMPATH,path=$squore_home/samples/c/Earth/V1 --teamUser=augustus,HEAD_OF_DEPARTMENTTable of Contents
sqexport.pl — Squore export utility
sqexport.pl [
option
...]
users
[
-r
]
sqexport.pl [
option
...]
groups
[
-m
]
sqexport.pl [
option
...]
versions
-m
[
-l
] [
-u
]
id_user
id_model
sqexport.pl [
option
...]
versions
-p
[
-l
] [
-u
]
id_user
id_project
sqexport.pl [
option
...]
artefacts
-m
[
-R
] [
--add-measure
...] [
measure
-T
...] [
type
-L
] [
level
-u
]
id_user
id_model
sqexport.pl [
option
...]
artefacts
-p
[
-R
|
-r
] [
id_rvers
--add-measure
...] [
measure
-T
...] [
type
-L
] [
level
-u
]
id_user
id_project
[
id_vers
]
The sqexport.pl script connects to the Squore database and exports data into the CSV format.
This command extracts raw data from the database. That is, it does not read i18n files or model properties to translate strings.
Columns common to the
versions
and
artefacts
exports are:
model_id - the database identifier of the model (verbose mode only).
model - the model name.
app_id - the database identifier of the project (verbose mode only).
app_name - the project name.
root_id - the database identifier of the root artefact (verbose mode only).
v_id - the database identifier of the version (verbose mode only).
v_name - the version name.
These columns are exported:
uid - the database identifier of the user (verbose mode only).
login - the login of the user.
sqexport.pl
users
[
-r
]
This command exports all user information for all Squore users. The output contains these additional columns:
fullname - the full name of the user.
email - the e-mail of the user.
password - the SHA-1 of the user password, base 64 encoded.
department - the department of the user.
When the -r option is specified, the user profiles are
exported instead. The output contains these additional columns:
role_id - the database identifier of the profile (verbose mode only).
role - the profile name of the user.
These columns are exported:
gid - the database identifier of the group (verbose mode only).
group - the name of the group.
sqexport.pl
groups
[
-m
]
This command exports all Squore groups.
When the -m option is used, group members are exported
instead. Here are the additional columns in this mode:
uid - the database identifier of the group member (verbose mode only).
login - the login of the group member.
These additional columns are exported:
status - the project's version status.
sl_rank - the (numeric) rank of the level of the project.
level - the level of the project.
app_name - The project name.
sqexport.pl
versions
-m
[
-l
] [
-u
]
id_user
id_model
This form exports all versions of projects that use the model identified
by id_model. If -l is used, only the
last version of each project is exported.
The id_user is used to restrict output data,
using access controls defined in Squore. If not supplied, versions and
projects are exported regardless of access control lists.
sqexport.pl
versions
-p
[
-l
] [
-u
]
id_user
id_project
This form exports all versions of the project identified by
id_project. If -l is used, only
the last version of the project is exported.
The id_user is used to restrict output data,
using access controls defined in Squore. If not supplied, versions and
projects are exported regardless of access control lists.
These additional columns are exported:
art_id - the database identifier of the artefact.
art_path - the path of the artefact.
art_name - the name of the artefact.
type - the type of the artefact.
sl_rank - the (numeric) rank of the level of the artefact.
level - the level of the artefact.
trend - the trend of the artefact, compared to
the reference version (with -R or -r
only). Values are 'N' for new artefacts, '^' for artefacts that improved,
'v' for artefacts that regressed, and '=' for others.
* - the measure values, as specified with
the --add-measure options.
sqexport.pl
artefacts
-m
[
-R
] [
--add-measure
...] [
measure
-T
...] [
type
-L
] [
level
-u
]
id_user
id_model
Exports all artefacts of the id_model model,
eventually filtered out by the -T and -L
filters. Both parameters of these options are identifiers of the types and
the level, as specified in the model. This is possible to specify types
separated by a comma, or multiple -T options. Such types
are then OR-ed.
Only artefacts that belong to the last version of projects are exported.
If the -R option is set, the trend of levels of artefacts is
computed against the last but one version of the projects. By default, there
is no trend computation.
Use the --add-measure option to specify the list of measures
to add to the output. Use with caution on large result sets.
The id_user is used to restrict output data,
using access controls defined in Squore. If not supplied, artefacts are
exported, regardless of access control lists.
sqexport.pl
artefacts
-p
[
-R
|
-r
] [
id_rvers
--add-measure
...] [
measure
-T
...] [
type
-L
] [
level
-u
]
id_user
id_project
[
id_vers
]
This form exports artefacts of the id_project project
in its id_vers version. If id_vers
is not specified, the last version if the project is used. Artefacts may be
filtered out with the -T and
type
-L options.level
The reference version to compute trends of levels of artefacts is either set
with -R (use the version right before id_vers),
or with -r to set an explicit
version of the project.id_rvers
Use the --add-measure option to specify the list of measures
to add to the output. Use with caution on large result sets.
The id_user is used to restrict output data,
using access controls defined in Squore. If not supplied, artefacts are
exported, regardless of access control lists.
These options are common to all export types.
-h host
Overrides the database host name.
-p port
Overrides the database port number.
-d dbname
Overrides the database name.
-u user
Overrides the database user name.
-f file
Set the CSV output file. If not specified, the output is written to the standard output.
-s sep
Set the CSV separator. Defaults to the ';' character.
-S slices
Specifies a subset of columns to write, starting from 0. The column numbering is computed against the verbose mode, not the standard mode. Separate column numbers with the ',' character.
-v
Turns on the verbose mode. Exports additional columns (mainly internal database ids), and displays some SQL and post processing timings.
-a
Turns on export at the artefact level.
-m
Turns on export at the model level.
-p
Turns on export at the project level.
-c
Counts entries only, do not list all of them.
-l
Exports the last version of each project only.
-R
Set the reference version for delta or trend computations to the last but one version of the project, from either its last version, or the user supplied version.
-r id_rvers
Set the reference version for delta or trend computations to
the version pointed to by the id_rvers.
-T type
...
Filter artefacts of types type, which is
the external id of the artefact type, as specified by the model,
like APPLICATION, CLASS, FUNCTION, etc. Types may be coma separated.
-L level
Artefacts shall have the level level,
which is the external id of the level of performance of a scale, as
specified by the model, like LEVELA, LEVELB, etc.
With the introduction of project milestones, a series of goals for specific metrics at certain dates in the life of your project, Squore offers new ways to measure your objectives and detect deviations from your goals early:
You are alerted early if your current performance shows that you will not meet your goals and can react before it is too late
You keep track of your various goals and communicate any change to the rest of your team
You can reflect on a project's history and learn from it
This example focuses on a project that is slipping, then over-performing and how the team reacts along the course of the development process. Our team is tracking a basic task completion metric over the lifetime of the project, which includes milestones for Requirements Review, Infrastructure Complete, Code Complete, Beta Release and Final Release.
Here is where they stand on the day of the Final Release and look back at how the project went:
The chart shows the following information:
Vertical dotted lines (markers) on the x-axis for each milestone in the project at the predefined date
A solid light-blue line showing the task completion metric for each version of the project
A dotted green line showing the goal for the task completion metric at each milestone
A solid red line showing the goals actually used for the task completion metric during the lifetime of the project.
Deviations from the goals around the REQ and BETA milestones
In order to understand why changes were made to the goals, let's go back to the January 27th analysis and look at the Task Completion chart again. Because we are using milestones and have a defined goal for the task completion metric, we can get a projection of what our metric will be by the time we hit the milestone dates.
So instead of just showing results from previous analyses, the Progress line continues past January 27th to show what results we can expect based on the performance so far. Our chart is configured to show the projected value for the next 3 milestones, and all 3 projections are below the goal line for the metric.
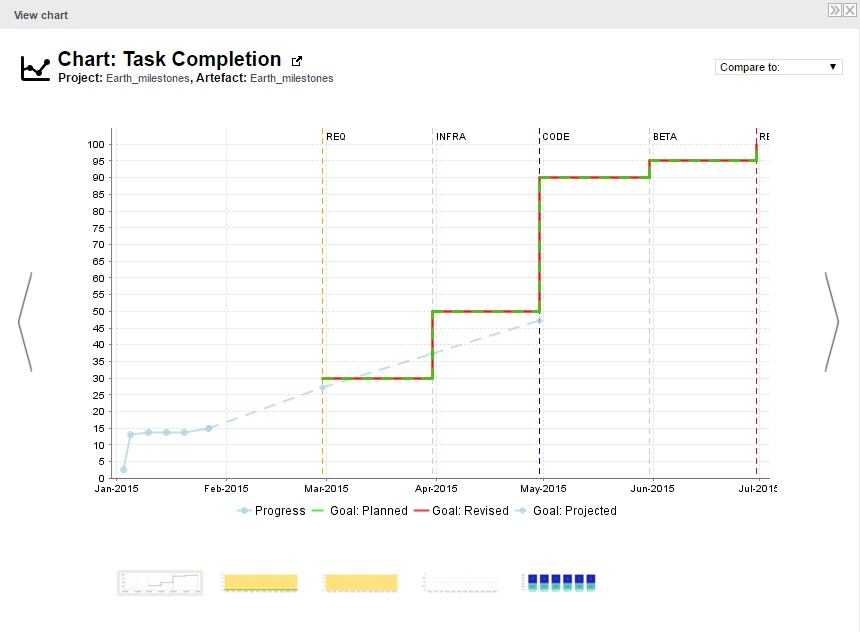
The team knows this: a Pessimistic Projection action item was already opened on January 15th to inform them that the current performance could cause problems in milestones 2 and 3. But today, an Objective Not Met action item informs them that they will not meet their goal even for the upcoming milestone.
After a team meeting, it is decided that the best course of action is to keep the goal for the Requirements Review milestone, but move its date by two weeks. The analysis run the next morning confirms this on the Task Completion chart, where you see the first deviation between the planned goal (green) and the actual goal (red). The progress objective will be met for the first milestone, but there are still doubts for the next two:
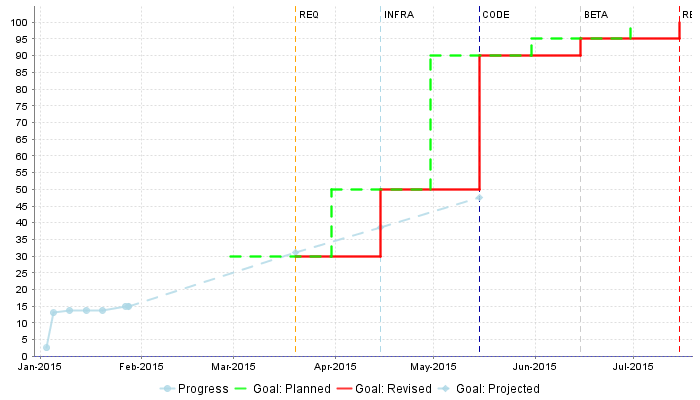
Let's fast forward to the end of May after the Code Complete milestone and before the Beta Release to find our team performing better than expected: progress is already over the goal for the beta, and it makes sense to raise the goal for the beta. In a final review after the release, we can use this information to revise our default goals for other projects of the same type. As before, this information can be highlighted in Squore using an action item similar to the one opened on May 27th:
After revising their goal, the team can share the new standards for the project to their collaborators in the Task Completion chart from June 13th, where the actual goal line (red) moves up compared to the planned goal line (green) for the Beta Release milestone:
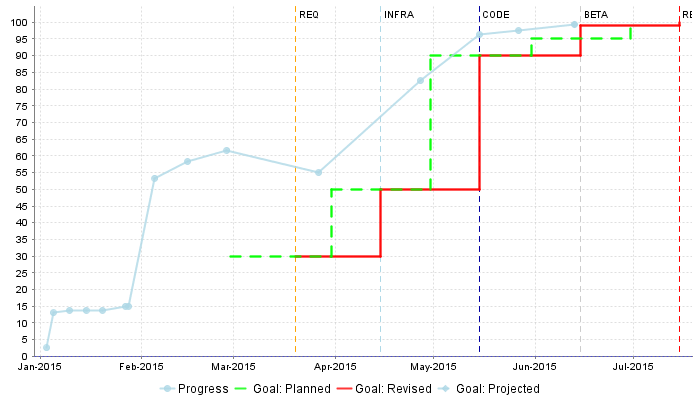
In order to add support for milestones to your model, configure your wizard to allow users to create milestones and goals:
<Bundle xmlns:xi="http://www.w3.org/2001/XInclude">
<wizard wizardId="DOC" versionPattern="v#N1#" img="../../Shared/Images/icons/faded.png">
<tools all="FALSE">
<tool name="project_data" optional="FALSE" checkedInUI="TRUE" />
<tool name="Squore" optional="TRUE" checkedInUI="TRUE">
<param name="scnode" value="TRUE" />
<param name="scnode_name" value="Code" />
</tool>
</tools>
<milestones canCreateMilestone="TRUE" canCreateGoal="TRUE">
<goals displayableFamilies="GOALS" />
</milestones>
</wizard>
</Bundle>The
milestones
element allows users to create milestones in
the project creation wizard (canCreateMilestone="TRUE") and also set goals (canCreateGoal="TRUE").
The goals can be set for metrics of the GOALS family only in this example (displayableFamilies="GOALS").
The result in the web UI is the following:
A project wizard allowing users to create milestones freely during an analysis
When creating a new project, a user decides to create a Specification Freeze milestone with one objective of 100 for the Requirement Status indicator. Other goals can be set, for the other metrics in the project that belong to the GOALS family: Risk Index, Task Progress, Test Result.
If you have company-wide milestones and objectives that need to be set for every project created with the wizard, you can specify the goals directly. Milestones can also be marked as mandatory or optional:
<Bundle xmlns:xi="http://www.w3.org/2001/XInclude">
<wizard wizardId="DOC_WITH_MILESTONES" versionPattern="v#N1#" img="../../Shared/Images/icons/faded.png">
<tools all="FALSE">
<tool name="project_data" optional="FALSE" checkedInUI="TRUE" />
<tool name="Squore" optional="TRUE" checkedInUI="TRUE">
<param name="scnode" value="TRUE" />
<param name="scnode_name" value="Code" />
</tool>
</tools>
<milestones canCreateMilestone="TRUE" canCreateGoal="TRUE">
<goals displayableFamilies="GOALS">
<goal measureId="RESULT" mandatory="TRUE" highestIsBest="FALSE" />
<goal measureId="STATUS" mandatory="TRUE" highestIsBest="TRUE" />
<goal measureId="PROGRESS" mandatory="TRUE" highestIsBest="TRUE" />
<goal measureId="RISK_INDEX" mandatory="TRUE" highestIsBest="FALSE" />
</goals>
<milestone id="REQUIREMENT_FREEZE" mandatory="TRUE">
<defaultGoal measureId="RESULT" value="0" />
<defaultGoal measureId="STATUS" value="1" />
<defaultGoal measureId="PROGRESS" value="30" />
<defaultGoal measureId="RISK_INDEX" value="1" />
</milestone>
<milestone id="INFRASTRUCTURE_FREEZE" mandatory="TRUE">
<defaultGoal measureId="RESULT" value="0" />
<defaultGoal measureId="STATUS" value="1" />
<defaultGoal measureId="PROGRESS" value="50" />
<defaultGoal measureId="RISK_INDEX" value="1" />
</milestone>
<milestone id="CODE_FREEZE" mandatory="TRUE">
<defaultGoal measureId="RESULT" value="0" />
<defaultGoal measureId="STATUS" value="1" />
<defaultGoal measureId="PROGRESS" value="90" />
<defaultGoal measureId="RISK_INDEX" value="0.5" />
</milestone>
<milestone id="BETA_RELEASE" mandatory="FALSE">
<defaultGoal measureId="RESULT" value="1" />
<defaultGoal measureId="STATUS" value="1" />
<defaultGoal measureId="PROGRESS" value="95" />
<defaultGoal measureId="RISK_INDEX" value="0.3" />
</milestone>
<milestone id="RELEASE" mandatory="TRUE">
<defaultGoal measureId="RESULT" value="1" />
<defaultGoal measureId="STATUS" value="1" />
<defaultGoal measureId="PROGRESS" value="100" />
<defaultGoal measureId="RISK_INDEX" value="0" />
</milestone>
</milestones>
</wizard>
</Bundle>When creating a new project, the predefined goals are filled in in the web interface, and you can still add a Beta Release milestone (using the default values specified in the wizard bundle) if needed by using the + icon:
A project wizard with preconfigured milestones and goals
If you create projects using the command line interface, you can specify settings for your milestones with the -M parameter:
-M "id=BETA_RELEASE,date=2015/05/31,PROGRESS=95"
or with a project config file:
<SquoreProjectSettings> <Wizard> <Milestones> <Milestone id="BETA_RELEASE" date="2015-05-31"> <Goal id="PROGRESS" value="95" /> </Milestone> </Milestones> </Wizard> </SquoreProjectSettings>
In your analysis model, new functions are available to work with milestones and projections:
HAS_MILESTONE([milestoneId or keyword] [, date])
checks if
a milestone with the specified milestoneId exists in the project.
The function returns 0 if no milestone is found, 1 if a milestone is found.
DATE_MILESTONE([milestoneId or keyword] [, date])
returns the date associated to a milestone.
GOAL(measureId [, milestoneId or keyword] [, date])
returns the goal for a metric at a milestone.
You can use keywords instead of using a milestone ID. You can retrieve information about the next, previous, first or last milestones in the project by using:
NEXT
NEXT+STEP
where STEP is a number indicating how many milestones to jump ahead
PREVIOUS
PREVIOUS-STEP
where STEP is a number indicating how many milestones to jump backward
FIRST
LAST
Consut the Configuration Guide for more details.
On your charts, you are now able to:
Display the goals defined for each milestone in your project
Display the changes made to the goals defined for each milestone
Display the date changes for your milestones
Show markers for milestone dates and goals
You can also compute metrics with functions like LEAST_SQUARE_FIT(), which lets you calculate projections. This is how the Task Completion chart used in this example was created. You can find its full definition below:
<chart type="TE" id="TASK_PROJECTION" byTime="TRUE" width="700" height="400" displayOnlyIf="MILESTONES_ARE_ENABLED"> <dataset renderer="STEP" > <goal dataBounds="[0;100]" color="GREEN" stroke="DOTTED" shape="CIRCLE" alpha="200" label="Planned" versionDate="FIRST_BUILD_DATE">PROGRESS</goal> <goal dataBounds="[0;100]" color="RED" stroke="SOLID" shape="DIAMOND" alpha="200" label="Revised">PROGRESS</goal> </dataset> <dataset renderer="LINE"> <measure stroke="SOLID" color="#ADD8E6" alpha="200">PROGRESS</measure> </dataset> <dataset renderer="LINE"> <goal dataBounds="[0;100]" color="#ADD8E6" stroke="DOTTED" shape="DIAMOND" alpha="200" label="Projected"> <forecast> <version value="PROGRESS" timeValue="CUR_BUILD_DATE" /> <version value="PROGRESS_NEXT" timeValue="NEXT_MILESTONE" /> <version value="PROGRESS_NEXT_1" timeValue="NEXT_1_MILESTONE" /> <version value="PROGRESS_NEXT_2" timeValue="NEXT_2_MILESTONE" /> </forecast> </goal> </dataset> <markers> <marker fromMilestones="true" alpha="150" isVertical="TRUE" stroke="DOTTED" /> </markers> </chart>
The action items monitoring the project's progress also make use of the new GOAL() function and were defined as follows:
<?xml version="1.0" encoding="utf-8" standalone="yes"?>
<Bundle>
<DecisionCriteria>
(...)
<DecisionCriterion dcId="PROGRESS_WARNING" categories="SCALE_PRIORITY.CRITICAL" targetArtefactTypes="APPLICATION">
<Triggers>
<Trigger>
<Test expr="MILESTONES_ARE_ENABLED" bounds="[1;1]" />
<Test expr="IF(PROGRESS_NEXT=-1, 0, PROGRESS_NEXT < GOAL(PROGRESS, NEXT))" bounds="[1;1]"
p2="#{MEASURE.DAYS_TO_NEXT}" p0="#{MEASURE.PROGRESS_GOAL_NEXT}" p1="#{MEASURE.PROGRESS_NEXT}" descrId="PROGRESS_WARNING_NEXT_ACTION" />
</Trigger>
</Triggers>
</DecisionCriterion>
(...)
<DecisionCriterion dcId="OVERPERFORMANCE" categories="SCALE_PRIORITY.NONE" targetArtefactTypes="APPLICATION">
<Triggers>
<Trigger>
<Test expr="MILESTONES_ARE_ENABLED" bounds="[1;1]" descrId="MILESTONES_ARE_ENABLED" />
<Test expr="IF(PROGRESS_NEXT=-1, 0, IF(PROGRESS / GOAL(PROGRESS, NEXT) > 1.1, 0, 1))" bounds="[1;1]"
p2="#{MEASURE.PROGRESS}" p1="#{MEASURE.DAYS_TO_NEXT}" p0="#{MEASURE.PROGRESS_GOAL_NEXT}" descrId="OVERPERFORMANCE" />
</Trigger>
</Triggers>
</DecisionCriterion>
</DecisionCriteria>
</Bundle>Check out the Getting Started Guide and the Configuration Guide to learn more about milestones, and if you would like to try out the demo described in this article on your own installation or review the entire model, download the configuration folder from our wiki and launch the demo from Tools > Feature Spotlight: Milestones.